基于中科大linux101和苏大ppt的linux笔记
苏大部分
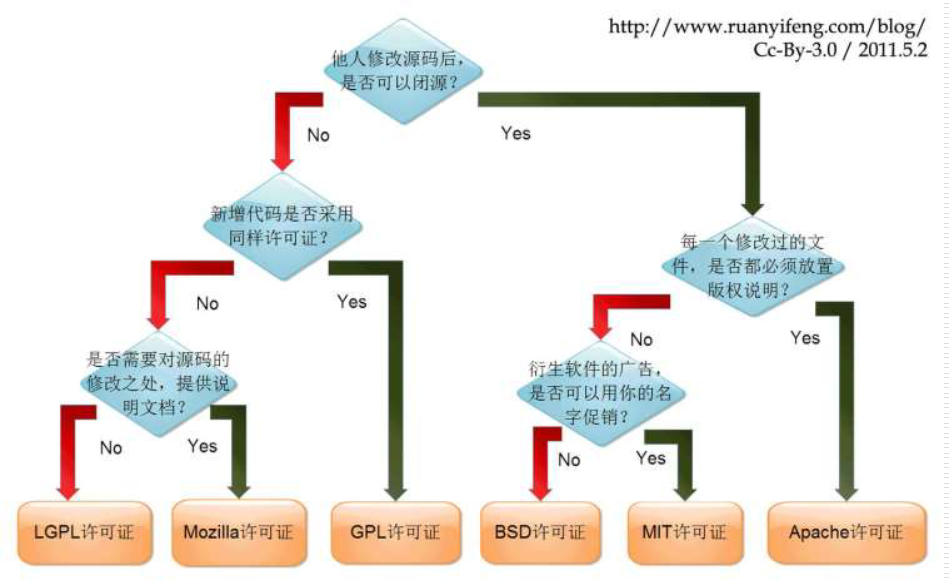
概念
软件可以粗略分为系统,工具,应用
软件的发行模式有:
- 商业软件
- 共享软件,免费给用户使用的商业软件,比如入门版杀毒软件,不一定开源
- 开源软件,开放源代码的软件,但不代表用户有自由分发修改源代码的权力
- 自由软件,开源,任何用户都有权使用、拷贝、扩散、修改该软件,但有义务公布修改后的代码
Linux系统提供多个虚拟控制台(默认6个字符界面,1个图形界面),可以独立使用,自由切换
文件
命名
- 除/之外,所有的字符都合法
- 大小写敏感
- 有些字符最好不用,如空格符、制表符、退格符和字符:?, @ # $ & () | ; ‘ ’ “ ” < >
- 避免使用+、-或. 来作为普通文件名的第一个字符
- 可以使用长文件名或目录名(255个字符)
- 包括完整路径的文件名不超过4096字符
主要的文件类型
- 普通文件
- 文本
- 二进制
- 数据格式
- 目录(同一个文件夹下不可能同时存在相同名称的文件和文件夹)
- 符号链接
- 字符设备文件,键盘、鼠标等串行接口设备
- 块设备文件,存储数据的设备,如硬盘、软盘等
- 套接字,socket文件,用于网络数据连接。
- 命名管道,用于进程间通信,解决多个程序同时访问一个文件造成的错误
目录
| bin | 存放二进制的可执行程序 |
| boot | 存放用于系统引导时使用的各种文件 |
| dev | 存放设备文件,用户通过这些文件访问外部设备 |
| etc | 存放系统的配置文件 |
| home | 存放用户文件的目录,每个用户在该目录下有一个与该用户名对应的子目录 |
| root | 超级用户目录 |
| sbin | 类似于/bin目录,存放二进制文件,只有root才能访问 |
| tmp | 用于放置各种临时文件 |
| var | 用于存放需要随时改变的文件,如系统日志、脱机工作目录等 |
| mnt | 系统管理员安装临时文件系统的安装点 |
| opt | 一般情况下,该目录不属于系统的基本文件系统,是额外安装的应用程序包所放置的地方 |
| usr | 用于存放系统应用程序 |
| lib | 存放根文件系统中的程序运行所需要的共享库及内核模块 |
| proc | 是一个虚拟文件系统,存放当前内存的映射,主要用于在不重启机器的情况下管理内核 |
| lost+ found | 存放一些系统检查结果,发现不合法的文件或数据都存放在这里,通常此目录是空的,除非硬盘遭到损坏 |
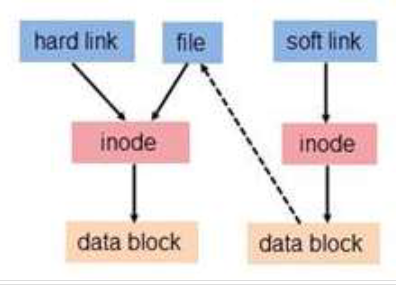
链接文件
硬链接 将两个文件名指向硬盘上同一个存储空间(inode),对任何一个文件的修改都将影响到另一个文件。
特性:- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
符号链接
又称软链接,是指将一个文件指向另外一个文件的文件名。
特性:
- 软链接有自己的文件属性及权限等;
- 软链接可对文件或目录创建;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 若被指向的原文件被删除,则相关软连接被称为死链接
- 删除软链接并不影响被指向的文件,若被指向路径文件被重新创建,死链接可恢复为正常的软链接
符号链接可以跨文件系统,即可以跨磁盘分区。硬链接不可以跨文件系统。它只能建立对文件的链接。
链接文件命令 ln
| ln file1 file2 | 创建源文件file1的硬链接file2 |
| ln -s file1 file2 | 创建源文件file1的软链接file2 |
符号链接可以跨文件系统,即可以跨磁盘分区。
硬链接不可以跨文件系统,只能建立对文件的链接。
硬链接删除只原文件或硬链接不影响文件内容
软连接删除源文件导致链接失效
通配符
* |
任意长度字符 |
|---|---|
? |
任意单个字符 |
[…] |
匹配任何包含在括号内的单个字符,可以是范围(-) 或多个字符 |
!/^ |
匹配任何不包含在[]括号内的字符 |
{…} |
匹配任何包含在括号内的模式,模式间用,隔开 支持遍历查询、创建、删除、修改文件 |
ls [!abc]*//首字符不是a或b或c的所有文件
ls a{0,1}{ab,ba}//列出当前目录下符合a0ab、a0ba、a1ab、a1ba名称的文件
ls [a-zA-Z]*
一些命令
find . 查找当前目录下所有文件和文件夹
find . -name ‘my*’查找当前目录下所有my开头的文件和文件夹
find . -type f -name my*在当前目录下查找以my开头的普通文件
find . -size +25k在当前目录下查找大于25k的文件
scp /home/user/a.txt user1@192.168.1.2:/home/user1 复制a.txt到远程设备user的主目录下
rm -ri usr/ 删除usr目录及其内容,删除时有提示
rm -d usr/ 删除usr目录,usr是一个空目录
查找系统文件所在路径命令 whereis
more 只能向下翻页,
less可以上下翻页,可以通过输入/pattern方式查找匹配
tac mylist 从后往前显示mylist的内容
统计文本文件的行数,字数,字符数 wc//l行,w单词,c字节数,m字符数
tar [-cxtzZjvC] [-f 文档名称] 文件与目录
c:压缩,x:解压,t:查看 三选一
zZj是压缩算法,z的后缀是gz最常用
f后接文件名,v表示过程中打印信息,C接目录
tar -zxvf myusr.tar.gz -C /home/CentOS/a 解压到指定目录/home/CentOS/a
tar -zcvf myusr.tar.gz mydoc 用gzip将mydoc目录打包后压缩
显示文件使用磁盘空间量 du
显示文件系统磁盘空间的使用情况 df ,-h容易阅读的形式
显示和编辑历史命令 history
记录历史命令的数目:HISTSIZE
记录历史命令的文本文件:HISTFILE
默认的记录文件:.bash_history
alias [别名]='[命令]'
unalias [-a] 别名
文件系统
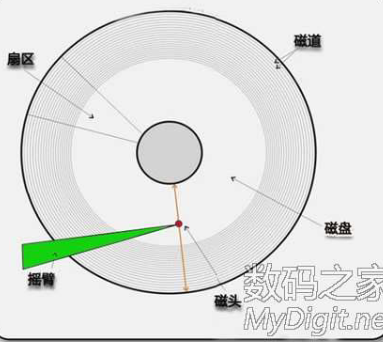
硬盘容量=柱面数(磁道数)*磁头数(盘片数)*扇区数*512B
总扇区=磁道数*磁头数*扇区数
总磁道=磁道数*磁头数
硬盘分区表
MBR
硬盘的第一个扇区存有主引导记录(Master boot record, MBR)及分区表(partition table)
- MBR用于引导操作系统
- partition table用于记录分区信息 一个MBR分区表类型的硬盘最多存在4个主分区,每个分区项占用16个字节
如果分区超过4个,则需要使用扩展分区,即一个物理硬盘上最多有3个主分区和1个扩展分区。
扩展分区不能直接使用,必须分割成为逻辑分区,一个扩展分区中的逻辑分区可以任意多个。
GPT
全称全局唯一标识分区表 GUID Partition Table
- 主分区数量任意(Win 128个)
- 支持最大18EB(NTFS 256TB) 1EB=1024PB
可能需要EFI支持(Win、Mac)
linux文件系统
磁盘分区完毕后还需要进行格式化(format),不同操作系统默认的文件系统不同,所以需要格式化成不同格式的分区。
EXT2(second extended filesystem)是LINUX内核默认的文件系统。
EXT2中的主要构成:
- SuperBlock 记录文件系统的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- Block 实际记录文件的内容,若文件较大,则占用多个 block。
- Inode 记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block 号码
inode
ext2 创建一个目录时,分配1个 inode 与至少1块 block 给目录
•inode 记录目录权限与属性,并记录分配到 block号码
•block 记录目录下文件名与该文件名占用的 inode
在读取时会先找到inode,定位到相应block,如果还有子文件就继续定位其inode,这样递归下去
inode 数量与大小在格式化时固定,记录存取模式,拥有者和组,容量,block的地址,修改创建时间等
inode包括:
- 12个直接block号码记录区
- 1个间接block号码记录区
- 1个双间接block号码记录区
- 1个三间接block号码记录区
特征:
- 每个 inode 大小均固定为 128 bytes;
- 每个文件仅占用一个 inode;
- 文件系统能够创建的文件数量与 inode 的数量有关;
- 系统读取文件时先找到 inode,分析 inode 所记录的权限与用户是否符合,若符合读取 block 的内容。
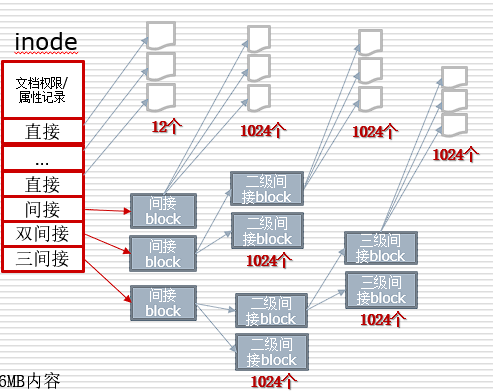 默认一个block为 4KB大小
默认一个block为 4KB大小
- 12个直接连接可以记录
12*4=48KB内容 - 1个间接连接可以记录
1024*4=4096KB内容
升级
EXT2文件系统高效稳定,但不提供日志
EXT3
提供日志模式:
data=journal模式
对所有的文件数据及metadata(定义文件系统中数据的数据,即数据的数据)进行日志记录
data=ordered或data=writeback模式
只对metadata记录日志,而不对数据进行日志记录
EXT4
EXT3的扩展升级,可以提供更佳的性能和可靠性,包括支持更大的分区和文件大小,更快的文件操作速度。
- EXT2文件系统高效稳定、安全性高
- FAT文件系统磁盘利用率高,性能一般
实例
fdisk
1 | fdisk [-options] <disk> |
中科大的xubuntu镜像
1
2
3
4
5
6
7
8
9
10
11
12
13
14ustc@ustclug-linux101:~/桌面$ sudo fdisk -l
[sudo] ustc 的密码:
Disk /dev/sda:5 GiB,5368709120 字节,10485760 个扇区
Disk model: VMware Virtual S
单元:扇区 / 1 * 512 = 512 字节
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:gpt
磁盘标识符:12526913-E330-4CA7-A379-90A87EF858B0
设备 起点 末尾 扇区 大小 类型
/dev/sda1 2048 499711 497664 243M EFI 系统
/dev/sda2 499712 10483711 9984000 4.8G Linux 文件系统
mkfs格式化
mkfs [-t 磁盘格式名] <partition> 1
mkfs -t ext3 /dev/sdb1
mount挂载
文件系统在访问时,必定需要一个访问地址,也就是要能够链接到目录树才能被使用。
将文件系统与目录树结合的动作称为『挂载』 1
2
3
4
5
6
7
8
9
10
11
12
13mount [-t vfstype] [-o options] device dir
-t 指定文件系统的类型,通常不必指定
mount 显示所有挂载的信息
mount –a 将所有未挂载设备挂载
mount /dev/hda2 /mnt/myhd2 将hda2设备挂载到/mnt/myhd2
mount -t iso9660 /dev/cdrom /media/cdrom 挂载光驱
umount [选项] dir
选项:
-f 强制卸载
-all 卸载所有挂载
例:
umount /media/cdrom 卸载刚才挂载的光驱
shell
Shell是系统的用户界面,提供了用户和操作系统内核进行交互操作的接口,位于应用与内核之间
shell命令可以分为内部和外部,内部可以直接执行,外部则需要查找
格式为cmd [-options] [arguments]
普通用户提示符是$,超级用户是#
常用命令:ls,clear,type(查询命令类型)
关机与重新启动本质是切换运行级别,6是重启,1是关机
init 6|init 0
reboot| halt
shutdown -r +5|shutdown -h +5
帮助程序有:help,man,iinfo,whatis(man -f)
重定向
Linux启动后,默认打开3个文件描述符
•标准输入:standard input 0
•标准输出:standard output 1
•错误输出:error output 2
每条shell命令执行,都会继承父进程的文件描述符。因此,所有运行的shell命令,都会有默认3个文件描述符。
默认的标准输出端口和标准错误端口为控制台的屏幕,标准输入端口是控制台的键盘
重定向 是指不使用系统的标准输入,标准输出或标准错误端口,而重新指定输入输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14输入重定向
< 输入重定向,从普通文件获取
<<!...! 输入重定向, here文件,即从命令行获取
wc <<!
>This text forms the content of heredocument
>which continues until the end of delimiter
>!
输出重定向
> 输出重定向,覆盖模式
>> 输出重定向,追加模式
2> 错误重定向,覆盖模式
2>> 错误重定向,追加模式
&> 同时实现输出重定向和错误重定向,覆盖模式
&>> 同时实现输出重定向和错误重定向,追加模式
管道
管道是一种两个进程间进行单向通信的机制
每个命令的输出作为下一条命令的输入,管道线中的命令从左到右顺序执行的,管道线是单向的
因为管道传递数据的单向性,管道又称为半双工管道
1
ls –l | wc -l
命令替换
Shell中的命令参数可以由另一个命令执行的结果来替代
命令格式: 1
2
3$cmd1 `cmd2 arguments`
或
$cmd1 $(cmd2 arguments)//$()形式可嵌套命令替换
命令聚合
在一个命令行上使用若干shell元字符将若干命令聚合在一起运行。
执行聚合的几种方式:
•cmd1;cmd2 顺序执行若干命令
1
pwd;date;ls
•cmd1&&cmd2 当cmd1运行成功时才运行cmd2
1
gzip mylargefile&&echo "OK."
cmd1||cmd2 当cmd1运行失败时才运行cmd2
1
gzip mylargefile||echo "FALSE."
(cmdlist) 在子shell中执行命令序列,命令不影响当前shell
1
(date;who|wc -l)>~/login-users.log
文本编辑
vim
:n1,n2 s/old/new/g g代表所有,不加则只替换一次
[Ctrl] + [f] | [Ctrl] + [b] 屏幕『向前/后』移动一页
r 取代(replace)光标所在的那一个字符;
R 一直取代光标所在的文字,直到按下 ESC 为止;
:set number 在编辑文件时显示行号
:set nonumber 不显示行号
:set ruler 在屏幕底部显示光标所在的行,列位置
:set noruler 不显示光标所在的行,列位置
grep
正则表达式是字符串的一种表达方式,用于字符串的处理,查找删除特定模式的字符串。
语法详细见101部分
1 | grep [-acinv] [--color=auto] [-EFGP] 'PATTERN' filename |
sed
sed是一个过滤模式的文本处理工具,可以对数据按行进行替换、删除、新增、选取等处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48sed [-nri] [-e script] [-f scriptfile] filename
-n 静默模式,即只有经过sed处理的那一行(或者动作)
才输出。默认会输出所有内容。
-e script 运行命令中的脚本
-f <文件名> 运行文件内的脚本
-r 使用扩展正规表达式(默认使用基本表达式)
-i 直接修改文件,而不是输出到标准输出
如果不选相当于预览修改效果
[addr]X[options]
addr 行地址
X 表示sed支持的单字符操作命令,如果设定行地址
则操作命令只对选择的行进行处理
options 某些操作命令所需的额外选项
n 指定命令对第n行进行动作
n1,n2 指定命令对第n1行到第n2行进行动作
$ 最后一行
a ∶新增(append), a 的后面可以接字串,而这些字串会在新的一行出现 (所选行的下一行)
i ∶插入(insert), i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
c ∶取代, c 的后面可以接字串
d ∶删除,通常命令后面不接任何东西;
sed '1a Hi' file #第一行后新增Hi
sed 'a Hi' file #每行后新增Hi
sed '1i Hi' file #第一行前新增Hi
sed '1c Hi' file #第一行代替为Hi
sed '1,20d' file #删除第1-20行
s :查找并替换
s/regex/replacement/flags
regex 正则表达式
replacement 替换的内容
flags 设置符号
包括 g全局替换 p打印 =打印行号
sed 's/old/new/’ file
sed 's/old/new/g’ file
\L 将后面的内容转为小写,直到遇到\U或\E结束
\l 将后面的一个字符转为小写
\U 将后面的内容转为大写,直到遇到\L或\E结束
\u 将后面的一个字符转为大写
\E 结束\L,\U的转换
s/(.*)/\U\1/g # 将所有字符大写
sed -i 's/123/1234/g' a.txt 将 a.txt 文件中所有行中的 123 用 1234 替换
cat a.txt | sed 's/offcie/ofiice/g'
cat telephone.data | sed 's/^[0-9]\{3\}/(&)/' > newTelephone.data
tr
tr是一个过滤模式的文本处理工具
- 用于替换(translate)、压缩和删除标准输入中的 字符
- 使用字符集来描述替换、压缩和删除的字符
- 通过管道接收待处理文本
1 | tr [-cdst] SET1 [SET2] |
awk
awk是一个强大的文本分析工具
- 逐行读入文件,并假定输入的文本是一个结构化文本
- 每一行称为一个记录(Record),每一列称为一个域(Field)
- 默认空格为分隔符进行行列切片,切开部分进行各种分析处理
- 支持样式装入、流控制、数学运算、进程控制语句,提供内置变量和函数
1 | awk [-Ffv] ' pattern{action}' {filenames} |
sort
sort是一个用于排序的文本处理工具
- 以行为单位进行排序
- 以指定分隔符对内容进行分列
- 对指定列进行升序或降序
1 | sort [选项] [文件] |
用户系统
账户的实质上是一个用户在系统上的标识,系统依据账户来区分每个用户的文件、进程、任务
普通用户账户:在系统上的任务是进行普通工作
超级用户账户:在系统上的任务是对普通用户和整个系统进行管理。
系统用户账户:伪用户,并不能登录,由操作系统自己操作。 每个用户都被分配了一个唯一的用户ID号(UID)
超级用户:UID=0,GID=0
普通用户:UID>=500(有的系统是1000)
系统用户(伪用户,不可登录):0<UID<500(有的系统是1000)
用户名和 UID 被保存在 /etc/passwd 这个文件中
组
- 组是用户的集合
- 每个组都被分配了一个唯一的组ID号(GID)
- 组和GID 被保存在 /etc/group 文件中
- 每个用户都有他们自己的私有组
- 每个用户都可以被添加到其他组中来获得额外的存取权限
- 组中的所有用户都可以共享属于该组的文件
- 当一个用户同属于多个组时,将这些组分为:
- 主组(初始组):用户登录系统时的组
- 附加组:可切换的其他组
权限管理
口令文件 /etc/passwd
| name | password | uid | gid | description | home | shell |
|---|---|---|---|---|---|---|
| 用户名 | 在此文件中的口令是X,这表示用户的口令是被/etc/shadow文件保护的 | 用户的识别号,是一个数字。每个用户的UID都是唯一的 | 用户的组的识别号,也是一个数字。每个用户账户在建立好后都会有一个主组。主组相同的账户其GID相同。 | 用户的个人资料,包括地址、电话等信息 | 用户的主目录,通常在/home下,目录名和账户名相同 | 用户登录后启动的shell,默认是/bin/bash |
组账号文件 /etc/group
被加密后的密码实际上储存在/etc/shadow中(包括修改密码时间,修改密码的最小最大时间间隔,警告修改时间等)
组口令则储存在/etc/gshadow
用户管理相关命令:
useradd , userdel, usermod ,passwd ,chage ,su,sudo
groupadd, groupdel, groupmod
权限管理相关命令:
- 权限设定命令 chmod
- 修改文件的属主和/或组命令 chown
- 修改文件的所属组命令 chgrp
1 | useradd [<选项>] <用户名> |
sudo的权限配置存在/etc/sudoers,用visudo配置
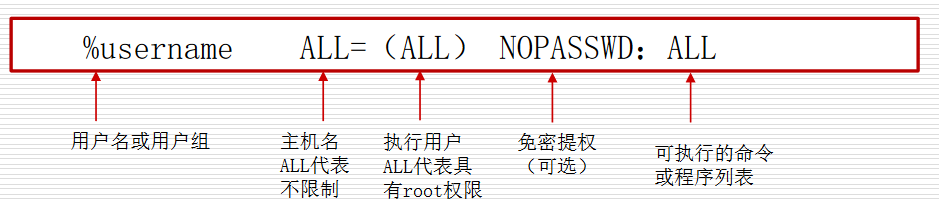
权限对应数字:
| r | 4 |
|---|---|
| w | 2 |
| x | 1 |
| - | 0 |
1 | ```chmod [who] [+| - |=] [permission] 文件或目录名 |
系统管理
进程
进程是正在运行的程序的实例。Linux是多任务系统,可以同时运行多个进程
PID :进程识别号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45进程状态命令 ps
BSD风格:
a 显示与终端tty有关的所有进程信息
x 显示所有非控制终端上的进程信息
u 显示面向用户的信息列(用户名、CPU、内存等)
pid号 显示指定进程pid信息
UNIX风格
-a 显示同一终端下的所有进程信息
-A或-e 显示所有进程
-l 显示长格式
-H 显示进程的树状结构。
-w 宽输出
-f 完全显示信息,即增加显示用户名、PPID等信息
-pid号 显示指定进程pid信息
• 标准字段
PID 进程标志号
TTY 进程创建时对应的终端,?表示不占用终端
TIME CPU累计使用时间
CMD 执行进程的命令名称
• 扩展字段
UID 进程的用户ID
PPID 父进程ID
• BSD扩展字段
USER 启动进程的用户
%CPU 进程占用CPU时间与该进程总的运行时间的比例
%MEM 进程占用的内存与总内存的比例
VSZ 进程占用的虚拟内存大小
STAT 进程运行状态(D、R、S、T、Z等)
START 开始的时间
进程终止命令 kill
kill [选项] 进程号
常用选项:
-l 列出全部的信号名称。
-a 当处理当前进程时,不限制命令名和进程号的对应关系。
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号。
-s 指定发送信号。
-u 指定用户。
-信号 描述进程终止发送的信号编号
kill -9 2277 9号信号代表强制终止
显示资源消耗最多的进程 top
显示当前内存和交换空间的使用情况 free
网络
1 | 测试网络的连通性 ping |
内核与软件
- 二进制软件包 优点:安装简单,可以本地安装也可以在线安装
缺点:灵活性一般,通常与平台或系统有关联
- 源代码包 优点:按需配置,可以适应多种平台系统
缺点:源代码无法直接运行,需要先编译再安装安装过程难度较大,对操作人员有一定要求
gz,tgz,bz2等后缀压缩包
1 | ➢ 安装 |
Red Hat、CentOS 和 Fedora 等使用 rpm 系统,rpm后缀
1 | rpm [-ivhe] rpm包名 |
Debian、Ubuntu、Mint 等系统使用 dpkg系统,deb后缀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19dpkg [-irPL] deb包名
-i: 安装软件包;
-r: 删除软件包;
-P: 删除软件包的同时删除其配置文件;
-L: 显示于软件包关联的文件;
-l: 显示所有安装的包
dpkg –i software.rpm 安装
dpkg –r software 卸载
apt [选项] 软件名称
intall 安装
update 检查升级
upgrade 升级
remove 卸载
list 列出当前安装的软件
search 搜索软件
apt list --upgradeable
apt list --installed
内核编译概念:
- 内核是硬件与软件之间的一个中间层
- 内核模块是内核的一部分
- 内核模块可以单独编译
- 内核更新可以自定义功能或者优化系统
shell编程
利用Shell提供的高级命令语言功能所写的程序称为Shell脚本。是纯文本文件,由shell解释执行,所以是解释型编程语言
可分为交互性与非交互性
退出脚本或当前Shell :exit n,返回0表示成功,0-255是某种失败
变量分类
- 用户变量,由用户自己定义、修改和使用
- 环境变量,由系统维护,用于设置用户的Shell工作环境,部分变量用户可以修改,用户也可以新增自定义的环境变量
- 特殊参数变量(Special Parameters),Bash 预定义的特殊变量,用户不能直接修改,但可以使用
用户变量
1 | 变量替换 |
除了直接赋值,也可以declare:
declare [选项] variable[=value]
| -r | 只读 ( readonly ) | -a | 数组 ( array ) |
| -x | 环境变量(export 为全局变量) | -p | 列出变量 |
| -i | 整型 ( integer ) | -f -F | 列出函数 ( function ) |
1 | ls /mnt/c/Program Files/ |
数组
申明:
- variable=(item1 item2 item2 ... )
- declare -a variable=(item1 item2 item2 ... ) 引用:${variable[n]}
取消变量命令 unset
1
2
3
4
5
6
7
8declare -a stu 定义数组变量
stu=(math1101 math1102 math1103) 数组赋值
stu[1]=math 单个赋值
echo ${stu[0]} 列出stu的第一个元素
echo ${stu[*]} 列出stu的所有元素
echo ${#stu[*]} 给出数组stu中元素的个数
unset stu[1] 删除stu的第二个元素
unset stu 删除整个数组
环境变量
比较重要的有
| 历史信息 | 描述 |
|---|---|
| HISTFILE | 用于存储历史命令的文件 |
| HISTSIZE | 历史命令列表的大小 |
| HOME | 当前用户的用户目录 |
| USER | 当前用户名 |
| UID | 当前用户的UID |
| LANG | 当前用户的主语言环境 |
| TERM | 当前用户的终端类型 |
| PATH | Bash寻找可执行文件的搜索路径 |
| PWD | 当前工作目录 |
| ENV | Linux查找配置文件的路径 |
1 | • 系统环境设置文件(对所有用户有效) |
位置变量
$n 表示第n个参数值
ls -l a*中,$1=-l $2=a*
左移参数命令 shift [n]
变量操作
判断变量是否存在或是否为空,并能对不存在或为空的变量作出相应的动作,这类操作称之为变量测试
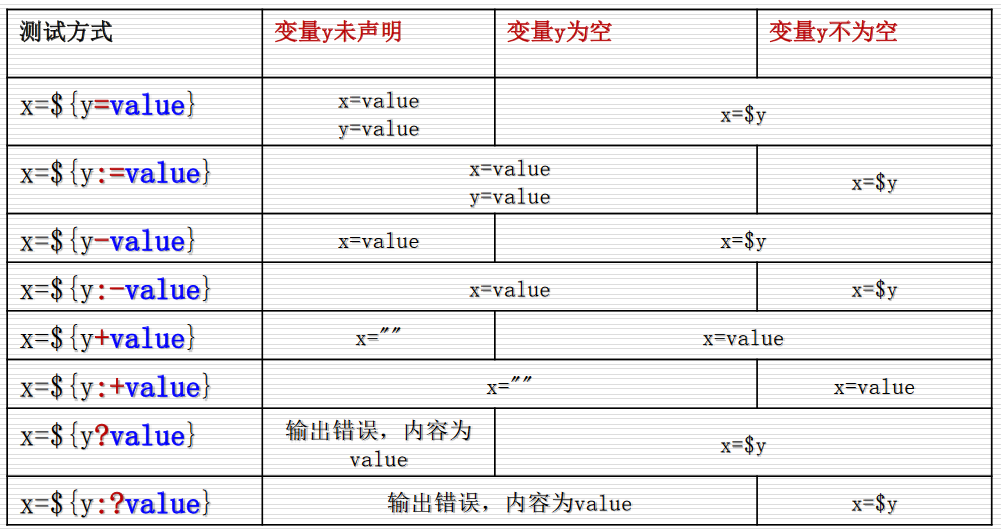

变量的间接引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19$(!varname)
aaa=123
Bbb=aaa
Echo $bbb
Echo ${!bbb}
#运行结果
aaa
123
eval \$$varname
eval newstr=\$$str2
echo $newstr
Hello World
告知shell取出参数,并重新运算参数内容 eval
eval arg1 [arg2] ... [argN]
eval会对参数进行扫描和替换
1.将所有的参数连接成一个表达式,并计算或执行该表达式
2.参数中的任何变量都将被展开
算术运算:
1 | let num2=4+1 |
输入输出
1 | read [参数] [var1 var2 ...] |
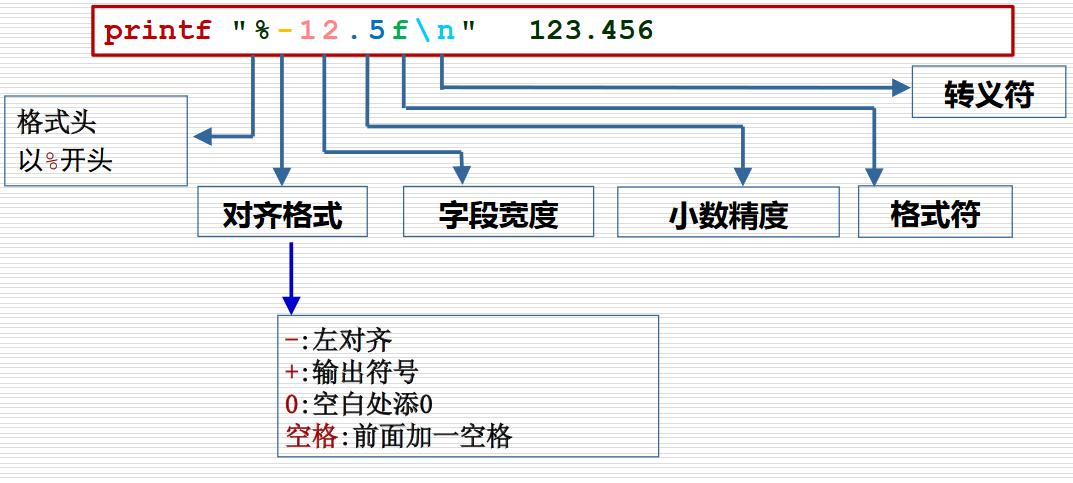
| 转义符 | 说明 |
|---|---|
\\ |
反斜线 |
\a |
报警符(BEL) |
\b |
退格符 |
\c |
禁止尾随的换行符 |
\f |
换页符 |
\n |
换行符 |
\r |
回车符 |
\t |
水平制表符 |
\v |
纵向制表符 |
逻辑和流程运算
条件测试可以判断某个特定条件是否满足,Bash中没有布尔类型变量,0表示真,非0表示假
1 | test <测试表达式> |
流程控制 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132if expr1 # 如果 expr1 为真(返回值为0)
then # 那么
commands1 # 执行语句块 commands1
elif expr2 # 若 expr1 不真,而 expr2 为真
then # 那么
commands2 # 执行语句块 commands2
... ... # 可以有多个 elif 语句
else # else 最多只能有一个
commands4 # 执行语句块 commands4
fi # if 语句必须以单词 fi 终止
myhost=centos1.ls-al.me
if ping -c1 -w2 $myhost &>/dev/null
then
echo "$myhost is UP."
else
echo "$myhost is DOWN."
fi
if ((age>=0&&age<13)) ; then echo "Child !"
elif ((age>=13&&age<20)); then echo "Callan !"
elif ((age>=20&&age<30)); then echo "P III !"
elif ((age>=30&&age<40)); then echo "P IV !"
else echo "Sorry I asked."
fi
case expr in # expr 为表达式,关键词 in 不要忘!
pattern1) # 若 expr 与 pattern1 匹配,注意括号
commands1 # 执行语句块 commands1
;; # 跳出 case 结构
pattern2) # 若 expr 与 pattern2 匹配
commands2 # 执行语句块 commands2
;; # 跳出 case 结构
... ... # 可以有任意多个模式匹配
*) # 若 expr 与上面的模式都不匹配
commands # 执行语句块 commands
;; # 跳出 case 结构
esac # case 语句必须以 esac 终止
echo "What is your preferred scripting language?"
echo "1) bash"
echo "2) perl"
echo "3) python"
echo "4) ruby"
echo "5) I do not know !"
read lang
case $lang in
1) echo "You selected bash" ;;
2) echo "You selected perl" ;;
3) echo "You selected python";;
4) echo "You selected ruby" ;;
5) exit
esac
read yn
case $yn in
1|[Ss]) echo "You selected $yn" ;;
2|[Rr]) echo "You selected $yn" ;;
3|[Ee]) echo "You selected $yn" ;;
esac
for variable in list
# 每一次循环,依次把列表 list 中的一个值赋给循环变量
do # 循环体开始的标志
commands # 循环变量每取一次值,循环体就执行一遍
done # 循环结束的标志,返回循环顶部
for day in Mon Tue Wed Thu Fri ; do
echo "Weekday $((i++)) : $day"
done
for ((expr1;expr2;expr3)) # 执行 expr1
do # 若 expr2的值为真时进入循环,否则退出 for循环
commands # 执行循环体,之后执行 expr3
done # 循环结束的标志,返回循环顶部
for ((i=0;i<10;i++))
do
echo $i
done
while expr # 执行 expr
do # 若expr的退出状态为0,进入循环,否则退出while
commands # 循环体
done # 循环结束标志,返回循环顶部
num =99
while ((num>10))
do
echo "num is above 10"
num=$((RANDOM%100))
done
echo "find a num below 10,the num is $num"
until ((num<=10))
do
echo "num is above 10"
num=$((RANDOM%100))
done
echo "find a num below 10,the num is $num"
select name in "Linux" "Windows" "MacOS" "Android" "HarmonyOS"
do
case $name in
"Linux")
echo "Linux is the best os!"
break
;;
"Windows")
echo "Windows is good!"
break
;;
"MacOS")
echo "Mac OS is good!"
break
;;
"Android")
echo "Android is a mobile os!"
break
;;
"MacOS")
echo "Android is a mobile os!"
break
;;
"HarmonyOS")
echo "HarmonyOS is a mobile os!"
break
;;
esac
done
函数
- 函数在使用前必须先定义
- 返回值$?(0~255)
1
2
3
4
5[ function ] funname [()] //申明函数
{
action; //函数内部语句
[return int;] //返回值,如不带则返回最后一条命令的执行状态
}
linux101

apt
1 | $ apt search firefox |
中间两行每个字段的含义:
| 样例中的字段 | 含义 |
|---|---|
firefox |
即为在软件仓库中的包名 |
bionic-updates,bionic-security,now |
为包含这个软件包的仓库源 |
72.0.2+build1-0ubuntu0.18.04.1 |
为软件包的版本 |
amd64 |
软件包的架构;还可能为i386、all等 |
Safe and easy web browser from Mozilla |
在软件仓库中对这个软件包的描述 |
请避免直接使用 dpkg -i 安装 deb 包。 在绝大多数情况下,都应该使用 apt 来安装 deb 文件。 如果不小心执行了 dpkg -i 导致系统出现依赖问题,可以尝试通过如下的方式调用 apt 帮助修复依赖管理:
1 | sudo apt -f install |
环境变量
我们不能每次在需要编译程序的时候输入如此长的路径找到 clang 和 clang++,而更希望的是能够像 apt 那样在任何地方都可以直接运行。
我们可以这样做:
1 | # 将 clang+llvm-10.0.0-x86_64-linux-gnu-ubuntu-18.04 目录下的所有内容复制到 /usr/local/ 下 |
为什么是 /usr/local 呢?因为 /usr/local/bin 处在 PATH 环境变量下。当我们在终端输入命令时,终端会先判断是否为终端的内建命令,如果不是,则会在 $PATH 环境变量中包含的目录下进行查找。因此,只要我们将一个可执行文件放入了 $PATH 中的目录下面,我们就可以像 apt 一样,在任意地方调用我们的程序。 通过这个命令可以看到当前的 PATH 环境变量有哪些目录。
1 | $ echo $PATH |
在上面的复制过程中,源目录和目标目录的两个 bin 目录会相互合并,clang 和 clang++ 两个可执行文件也就被复制到了 /usr/local/bin/ 目录中。这样子也就达到了我们希望能够在任意地方调用我们的可执行文件的目的。此外,在复制的时候 lib、doc 等文件夹也会和 /usr/local 下的对应目录合并,将 clang 的库和文档加到系统当中。
模式匹配
许多现代的 shell 都支持一定程度的模式匹配。举个例子,bash 的匹配模式被称为 glob,支持的操作如下:
| 模式 | 匹配的字串 |
|---|---|
* |
任意字串 |
foo* |
匹配 foo 开头的字串 |
*x* |
匹配含 x 的字串 |
? |
一个字符 |
a?b |
acb、a0b 等,但不包含 a00b |
*.[ch] |
以 .c 或 .h 结尾的文件 |
进程
htop
Htop 可以简单方便查看当前运行的所有进程,以及系统 CPU、内存占用情况与系统负载等信息。
使用鼠标与键盘都可以操作 htop。Htop 界面的最下方是一些选项,使用鼠标点击或按键盘的 F1 至 F10 功能键可以选择这些功能,常用的功能例如搜索进程(F3, Search)、过滤进程(F4, Filter,使得界面中只有满足条件的进程)、切换树形结构/列表显示(F5, Tree/List)等等。
进程标识符(PID,Process Identifier(是一个数字,是进程的唯一标识。在 htop 中,最左侧一列即为 PID。当用户想挂起、继续或终止进程时可以使用 PID 作为索引。
在 htop 中,直接单击绿色条内的 PID 栏,可以将进程顺序按照 PID 升序排列,再次点击为降序排列,同理可应用于其他列。
linux对进程的分类
Status: R: running; S: sleeping; T: traced/stopped; Z: zombie; D: disk sleep S 对应的 sleeping 又称 interruptible sleep,字面意思是「可以被中断」;而 D 对应的 disk sleep 又称 uninterruptible sleep,不可被中断,一般是因为阻塞在磁盘读写操作上。 Zombie 是僵尸进程,该状态下进程已经结束,只是仍然占用一个 PID,保存一个返回值。而 traced/stopped 状态正是下文使用 Ctrl + Z 导致的挂起状态(大写 T),或者是在使用 gdb 等调试(Debug)工具进行跟踪时的状态(小写 t)。
| 状态 | 缩写表示 | 说明 |
|---|---|---|
| Running | R | 正在运行/可以立刻运行 |
| Sleeping | S | 可以被中断的睡眠 |
| Disk Sleep | D | 不可被中断的睡眠 |
| Traced / Stopped | T | 被跟踪/被挂起的进程 |
| Zombie | Z | 僵尸进程 |
ps
ps(process status)是常用的输出进程状态的工具。直接调用 ps 仅会显示本终端中运行的相关进程。如果需要显示所有进程,对应的命令为 ps aux。
优先级与 nice 值
有了进程,谁先运行?谁给一点时间就够了,谁要占用大部分 CPU 时间?这又是如何决定的?这些问题之中体现着优先权的概念。如果说上面所介绍的的那些进程属性描述了进程的控制信息,那么优先级则反映操作系统调度进程的手段。在 htop 的显示中有两个与优先级有关的值:Priority(PRI)和 nice(NI)。以下主要介绍用户层使用的 nice 值。
Nice 值越高代表一个进程对其它进程越 "nice"(友好),对应的优先级也就更低。Nice 值最高为 19,最低为 -20。通常,我们运行的程序的 nice 值为 0。我们可以打开 htop 观察与调整每个进程的 nice 值。
用户可以使用 nice 命令在运行程序时指定优先级,而 renice 命令则可以重新指定优先级。当然,若想调低 nice 值,还需要 sudo(毕竟不能随便就把自己的优先级设置得更高,不然对其他的用户不公平)。
1 | nice -n 10 vim # 以 10 为 nice 值运行 vim |
用户进程控制
 信号是 Unix 系列系统中进程之间相互通信的一种机制。发送信号的 Linux 命令叫作
信号是 Unix 系列系统中进程之间相互通信的一种机制。发送信号的 Linux 命令叫作 kill。被称作 "kill" 的原因是:早期信号的作用就是关闭(杀死)进程。
前后台
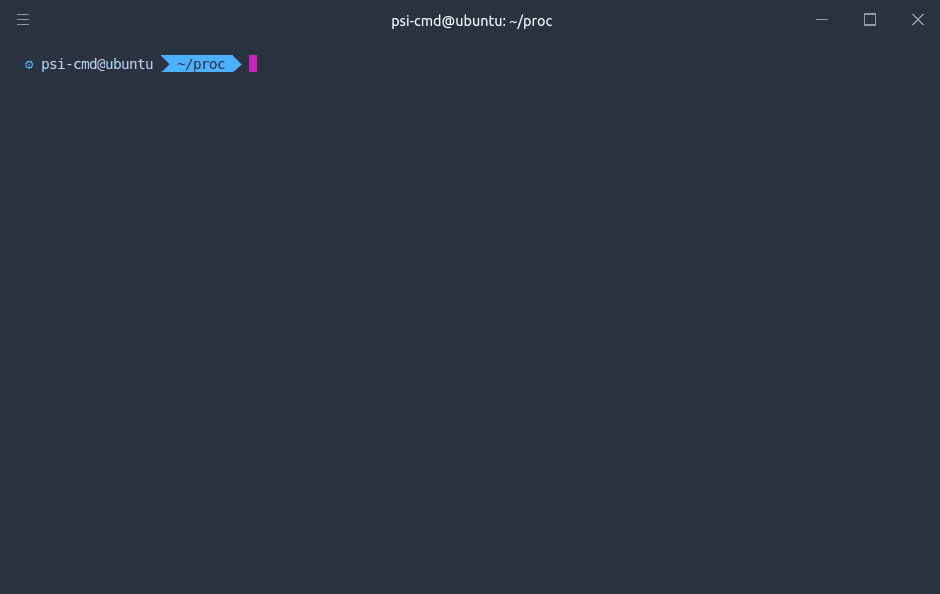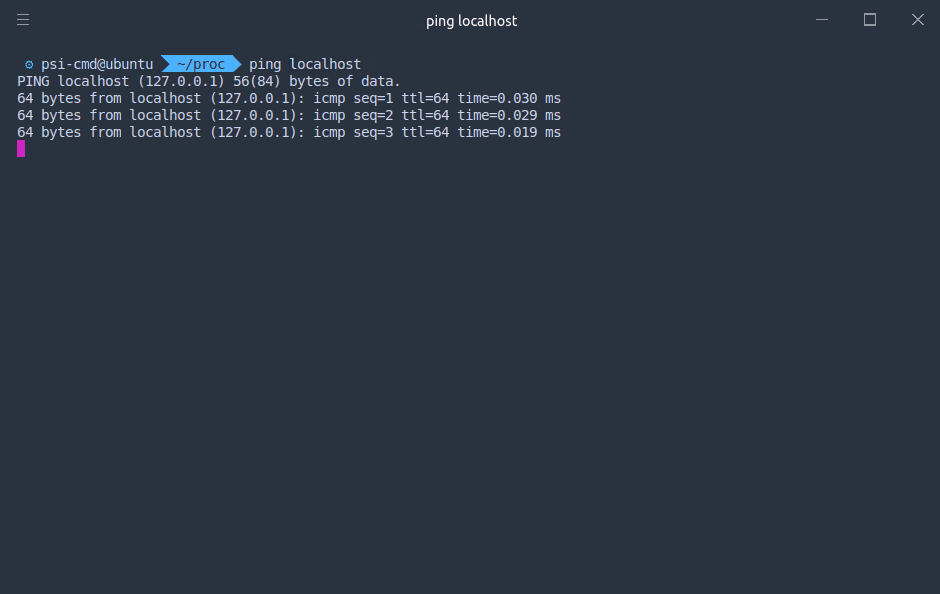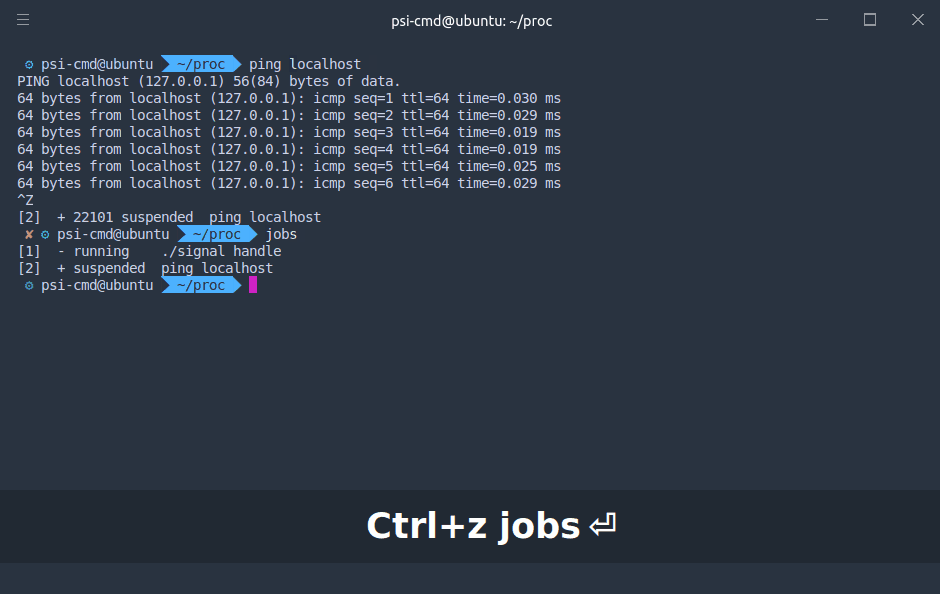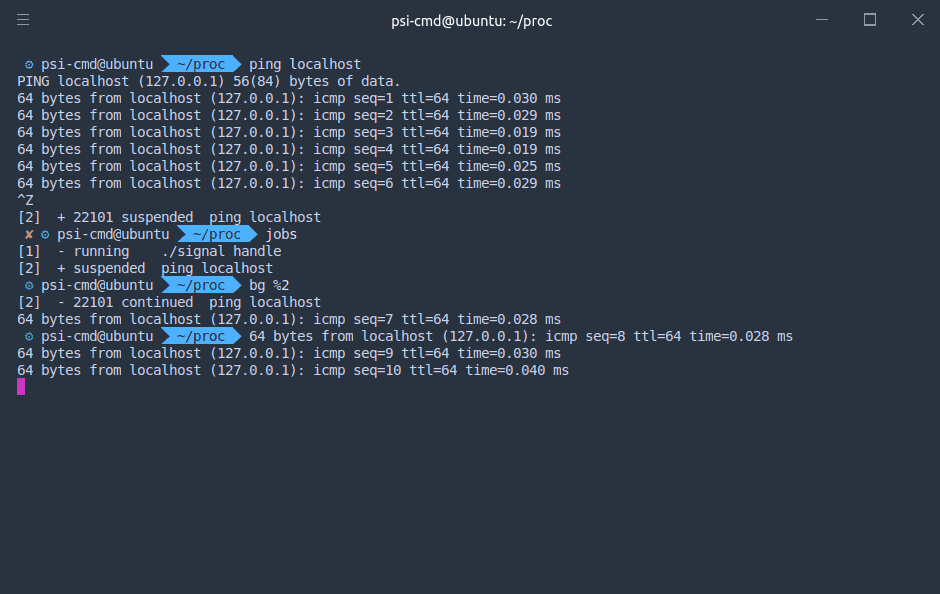 默认情况下,在 shell 中运行的命令都在前台运行,如果需要在后台运行程序,需要在最后加上
默认情况下,在 shell 中运行的命令都在前台运行,如果需要在后台运行程序,需要在最后加上 & 而如果需要将前台程序切换到后台,则需要按下 Ctrl + Z 发送 SIGTSTP 使进程挂起,控制权还给 shell 我们可以使用 jobs 命令,看到当前 shell 上所有相关的进程 任务前的代号在 fg,bg,乃至 kill 命令中发挥作用。使用时需要在前面加 %,如将 2 号进程放入后台,则使用 bg %2
终止进程
标准的终止进程信号是 SIGTERM,意味着一个进程的自然死亡
- htop 中自带向进程发送信号的功能。按下 K 键,在左侧提示栏中选择需要的信号,按下回车发送。同时可以使用空格对进程进行标记,被标记的进程将改变显示颜色。此时重复上述过程,可对被标记进程批量发送信号。
- 如果不加任何参数,只有 PID,
kill命令将自动使用 15(SIGTERM)作为信号参数。 - 在信号中,9 代表 SIGKILL,收到这个信号之后,程序会立刻退出。在使用时,直接
kill -9 PID即可。
其他类 kill 命令
pgrep/pkill后面接模糊名称,实际上类似于对名称进行grep命令。pgrep仅列出搜索到的进程名称符合用户输入的进程标识符,而pkill会根据用户的输入向进程发送信号。killall与pkill有一些类似,会向指定名字的进程发送信号。xkillxkill是针对窗口的 kill,运行该命令后,鼠标点击程序对应的窗口,就可以杀死该程序。
脱离终端
如果你使用过 SSH 连接到远程服务器执行任务,那么你会发现,你在 shell 中执行的程序在 SSH 断开之后会被关闭。这是因为终端一旦被关闭会向其中每个进程发送 SIGHUP(Signal hangup),而 SIGHUP 的默认动作即退出程序运行。
nohup
nohup,字面含义,就是「不要被 SIGHUP 影响」。
1 | $ nohup ping 101.ustclug.org & |
在需要屏蔽 SIGHUP 的程序前添加 nohup,则运行时的输出将被重定向到 nohup.out,也可以通过重定向手段自定义输出的文件。
服务
服务管理
目前绝大多数 Linux 发行版的 init 方案都是 systemd,其管理系统服务的命令是 systemctl。
若想了解全部服务内容,可以运行 systemctl list-units 来查看。该命令将显示所有 systemd 管理的单元,同时右面还会附上一句注释来表明该服务的任务。
1 | $ tldr systemctl |
例行性任务
可以用at,crontab等工具创建例行性任务 详见linux101
用户权限和文件系统
可以查看 /etc/passwd 文件,来得到系统中用户的配置信息。 普通用户的文件存储于位于 /home/username/路径
以 root 之外的用户的身份执行命令:加上 -u 用户名 的参数即可。
1 | $ sudo -u nobody id |
用户组
用户组是用户的集合。通过用户组机制,可以为一批用户设置权限。可以使用 groups 命令,查看自己所属的用户组。
1 | $ groups |
用户组和用户一样,也有编号:GID (Group ID)。
文本处理
正则表达式
在线编辑正则表达式 正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
特殊字符表:
| 特殊字符 | 描述 |
|---|---|
[] |
方括号表达式,表示匹配的字符集合,例如 [0-9]、[abcde] |
() |
标记子表达式起止位置 |
* |
匹配前面的子表达式零或多次 |
+ |
匹配前面的子表达式一或多次 |
? |
匹配前面的子表达式零或一次 |
\ |
转义字符,除了常用转义外,还有:\b 匹配单词边界;\B 匹配非单词边界等 |
. |
匹配除 \n(换行)外的任意单个字符 |
{} |
标记限定符表达式的起止。例如 {n} 表示匹配前一子表达式 n 次;{n,} 匹配至少 n 次;{n,m} 匹配 n 至 m 次 |
| |
表明前后两项二选一 |
$ |
匹配字符串的结尾 |
^ |
匹配字符串的开头,在方括号表达式中表示不接受该方括号表达式中的字符集合 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ 比较常用 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM 比较常用 |
\t |
匹配一个制表符。等价于 \x09和 \cI |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]. |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]. |
\w |
匹配字母、数字、下划线。等价于[_[:alnum:]] |
\d |
匹配数字。等价于 [0-9] |
{n,m}表示匹配次数,包括n,m次
若是想要匹配特殊字符本身,需要在之前加上转义字符 \。
基本/扩展正则表达式
基本正则表达式(Basic Regular Expressions, BRE)和扩展正则表达式(Extended Regular Expressions, ERE)是两种 POSIX 正则表达式风格。
BRE 可能是如今最老的正则风格了,对于部分特殊字符(如 +, ?, |, {)需要加上转义符 \ 才能表达其特殊含义。
ERE 与如今的现代正则风格较为一致,相比 BRE,上述特殊字符默认发挥特殊作用,加上 \ 之后表达普通含义。
懒惰和贪婪
使用 * + 的时候默认是贪婪模式,即尽可能匹配更多的子表达式。在 * + 之后加上 ? 变为懒惰模式,即尽可能匹配更少的子表达式。
例如:123456456
贪婪:1.+6 -> 123456456
懒惰:1.+?6 -> 123456 后向引用可以将之前匹配到的具体内容再次利用。在正则表达式中,() 以及它们包含的内容为一个分组,每个分组默认拥有一个组号。
组号分配规则:
- 0 代表整个表达式
- 从左至右,按左括号的出现顺序分配,第一个为 1,第二个为 2,以此类推
- 扫描两遍,第一次只分配未命名的组,第二次只分配命名的组。即任意命名组的组号都大于未命名的组号
后向引用
零宽断言
零宽断言用于查找某些内容进行定位,但内容并不放入匹配结果,就像 \b ^ $ 的定位一样。(?=exp) 用于匹配表达式 exp 前面的位置,(?<=exp) 用于匹配后面的位置。
拓展阅读
其他的文本处理工具
grep
grep 全称 Global Regular Expression Print,是一个强大的文本搜索工具,可以在一个或多个文件中搜索指定 pattern 并显示相关行。
grep 默认使用 BRE,要使用 ERE 可以使用 grep -E 或 egrep。
命令格式:grep [option] pattern file
一些用法:
-n:显示匹配到内容的行号-v:显示不被匹配到的行-i:忽略字符大小写
1 | ls /bin | grep -n "^man$" # 搜索内容仅含 man 的行,并且显示行号 |
sed
sed 全称 Stream EDitor,即流编辑器,可以方便地对文件的内容进行逐行处理。
sed 默认使用 BRE,要使用 ERE 可以 sed -E。
命令格式:
1 | sed [OPTIONS] 'command' file(s) |
此处的 command 和 scriptfile 中的命令均指的是 sed 命令。
常见 sed 命令:
- s 替换
- d 删除
- c 选定行改成新文本
- a 当前行下插入文本
- i 当前行上插入文本
1 | $ echo -e "seD\nIS\ngOod" > sed_demo |
awk
awk 是一种用于处理文本的编程语言工具,名字来源于三个作者的首字母。相比 sed,awk 可以在逐行处理的基础上,针对列进行处理。默认的列分隔符号是空格,其他分隔符可以自行指定。
awk 使用 ERE。
命令格式:awk [options] 'pattern {action}' [file]
awk 逐行处理文本,对符合的 patthern 执行 action。需要注意的是,awk 使用单引号时可以直接用 $,使用双引号则要用 \$。
一些示例:
1 | $ cat awk_demo |
示例中 $1,$2,$3 分别指代本行的第 1、2、3 列。特别地,$0 指代本行。
awk 语言是「图灵完全」的,这意味着理论上它可以做到和其他语言一样的事情。这里我们不仅可以对每行进行操作,还可以定义变量,将前面处理的状态保存下来,以下是一个求和的例子:
1 | $ awk 'BEGIN { sum = 0 } { sum += $2 * $3 } END { print sum }' awk_demo |
tr,sort
除此之外,tr可用于进行简单的预处理,sort可以用于进行简单的排序、
shell环境
组命令:
使用
{ 命令1; 命令2; … },组命令在 shell 内执行,不会产生新的进程,注意花括号和命令之间的空格。使用
(命令1; 命令2; …),组命令会建立独立的 shell 子进程来执行组命令,这里的圆括号周围并不需要空格。
可以在脚本开头加上 set -u 来实现使用未定义变量报错,否则会默认成空值
位置参数
- Shell 解释用户的命令时,把命令程序名后面的所有字串作为程序的参数。分别对应
$1、$2、$3、……、$9,程序名本身对应$0。 - 可用
shift <n>命令,丢弃开头的 n 个位置变量,改变$1、$2、$3等的对应关系。 - 可用
set命令,重置整个位置变量列表,从而给$1、$2、$3等赋值。
1 | $ set one two three |
特殊变量
| 特殊变量 | 说明 |
|---|---|
$# |
命令行上的参数个数,不包括 $0 |
$? |
最后命令的退出代码,0 表示成功,其它值表示失败 |
$$ |
当前进程的 PID |
$! |
最近一个后台运行进程的进程号 |
$* |
命令行所有参数构成的一个字符串 |
$@ |
用双引号括起的命令行各参数拼接构成的一个字符串 |
$_ |
在此之前执行的命令或脚本的最后一个参数 |
$0 |
命令行上输入的Shell程序名 |
特殊字符
反斜杠,消除单个字符的特殊含义。
- 包含空白字符(空格和制表符)、反斜杠本身、各种引号,以及
$、!等。 - 与其他语言不同,shell 中反斜杠不会将普通字符转义为其他含义(例如
\n不会被视作换行符)。
- 包含空白字符(空格和制表符)、反斜杠本身、各种引号,以及
使用双引号包裹字符串可以消除空白字符切分参数的特殊含义,但是很多其他特殊字符的特殊含义仍然保留。双引号也被称为「弱引用」。
单引号,能消除所有特殊字符的特殊含义,包括反斜杠,因此单引号字符串中不能使用反斜杠转义单引号本身。单引号也被称为「强引用」。
反引号(
`)括起的字符串,被 shell 解释为命令,执行时用命令输出结果代替整个反引号对界限部分。- 与反引号相同的语法是
$(command),它的好处是界限更明确,且可以嵌套。因此编写新脚本时,更建议使用此语法。
- 与反引号相同的语法是
语法
具体语法可参考linux101
拓展阅读
进程与会话
Fork 是类 UNIX 中创建进程的基本方法:将当前的进程完整复制一份。新进程和旧进程唯一的区别是 fork() 的返回值不同。程序员可以根据其返回值为新旧进程设置不同的逻辑。
除了最开始的 0 号进程外,绝大多数情况下其他进程是由另一个进程通过 fork 产生的。这里产生进程的一方为父进程,被产生的是子进程。在 Linux 中,父进程可以等待子进程,接收子进程退出信号以及返回值。 父进程如果先于子进程退出,产生孤儿进程,会被0号进程(init)接管 子进程先退出但父进程没有回应,产生僵尸进程,会被系统定时清理
进程组大体上是执行同一工作的进程形成的一个团体,通常是由于父进程 fork 出子进程后子进程继承父进程的组 ID 而逐渐形成。
会话 (session) 可以说是面向用户的登录出现的概念。当用户从终端登录进入 shell,就会以该 shell 为会话首进程展开本次会话。一个会话中通常包含着多个进程组,分别完成不同的工作。用户退出时,这个会话会结束,但有些进程仍然以该会话标识符 (session ID) 驻留系统中继续运行。
| 进程属性 | 意义/目的 |
|---|---|
| PID | Process ID,标识进程的唯一性。 |
| PPID | Parent PID,标识进程父子关系。 |
| PGID | Process Group ID,标识共同完成一个任务的整体。 |
| TPGID | 标识一组会话中处于前台(与用户交流)的进程(组)。 |
| SID | Session ID,标识一组会话,传统意义上标识一次登录所做的任务的集合,如果是与具体登录无关的进程,其 SID 被重置。 |
终端 (Terminal) 与控制台 (Console)
在上世纪六十年代,个人计算机尚未开始发展,用户使用计算机的一种常见方式就是通过终端,与远程的服务器连接交互。当时键盘和显示器连为一体,称为终端(terminal)。而主机自带的一套键盘与屏幕只能给系统管理员使用,称为控制台 (console),用来输出启动 debug 信息(现在的 Linux 系统如果因故障而不得不进入单用户修复模式,则只有一个终端 /dev/console 开启)。
然而随着时代的发展,这种模式逐渐被家庭电脑的分布式主机取代,我们不需要,也没有多套终端了,只有显示器、键盘、鼠标。但是为了向前兼容性,我们需要假装这是一个(甚至多个)终端,所以一般发行版 /dev 目录下有 7 个终端 tty1 ~ tty7,通过 Ctrl + Alt + F1 ~ F7 切换键盘与显示器与哪个终端相对应。
再后来,随着时代发展,终端需要出现在图形界面上了,然而承载图形界面的也是终端,所以终端里的终端就需要终端模拟器来实现了。由此,出现在图形界面上的终端才叫终端模拟器。
没有图形界面时,shell 一般为控制台 (tty) 的子进程,在图形界面上 shell 建立在虚拟终端 (pty, pseudo tty) 之上。顺带一提,服务器常用的远程连接工具 ssh 的父进程也是一个 pty。
参考阅读: 你真的知道什么是终端吗?
文件系统的特殊权限位
有三个特殊权限位:setuid, setgid 和 sticky。
setuid: 以文件所属的用户的身份 (UID) 执行此程序。setgid: 对文件来说,以文件所属的用户组的身份 (GID) 执行此程序;对目录来说,在这个目录下创建的文件的用户组都与此目录本身的用户组一致,而不是创建者的用户组。sticky(restricted deletion flag): 目录中的所有文件只能由文件所有者(除root以外)删除或者移动。一个典型的例子是临时文件夹/tmp,在此文件夹中你可以创建、修改、重命名、移动、删除自己的文件,但是动不了别人的文件。
/usr/bin/passwd 的文件权限设置:
1 | $ ls -l /usr/bin/passwd |
可以看到,本来是执行权限位的地方变成了 s。这代表此文件有 setuid 特殊权限位。在你执行 passwd 的时候,它的实际权限和 root 一样,只是它知道,执行它的人是你(而非 root),所以只提供修改你自己的密码的功能。
此外,passwd需要知道实际执行自己的用户是谁,在 Linux 中,有两个系统调用可以获取当前进程归属的 UID:getuid() 和 geteuid()。前者对应的是「实际用户」(Real user),是实际运行(拥有)这个进程的用户,后者对应的是「有效用户」(Effective user),对应进程拥有的权限。在运行 passwd 的时候,有效用户是 root,所以可以修改 /etc/shadow;而实际用户是你,所以它不会让你修改别人的密码。
对用户组来说,也有实际用户组 (GID) 和有效用户组 (EGID) 的区别。
登录 Shell和非登录 Shell
「登录 Shell」是属于你的当前会话操作中的第一个进程,一般是在你输入用户名和密码之后打开的 Shell。常见的场景有:
su -之后的 Shell。- SSH 登录机器后的 Shell
- Ctrl + Alt + F[1-7] 之后 TTY 中的 Shell
而「非登录 Shell」的常见场景:
su打开的是「非登录 Shell」- 在桌面环境中打开的终端(模拟器),启动的也是「非登录 Shell」
一般地,「登录 Shell」会额外加载 profile 文件(文件名根据你使用的 Shell 的不同而有区别),且它的 argv[0][0] == '-'(相信你已经学过 C 语言了)。可以用以下方法验证:
1 | $ echo $0 # 查看当前 Shell 的 argv[0] 的值 |
fork炸弹
Fork 炸弹有如下的这种形式:
1 | :(){ :|: & };: |
这是一个函数定义以及对其的调用语句,可以格式化为:
1 | :() |
在 Bash 中,:、.、/ 等一些字符也能够被用于函数命名,因此,上面的代码等价于:
1 | func() |
fork 炸弹的核心是函数内容:func | func &
- 第一个 func 代表递归执行这个函数。
- 代表要将第一个函数的数据结果通过管道传输给后一个函数。
- & 代表要在后台执行这一条命令,如果其中一个函数被操作系统回收,其调用产生的子函数并不会被回收。
于是运行一次这个函数就会创建两个 func 函数的实例,并不断地反复调用。实例的数量会指数爆炸式地增长,最终耗尽系统的资源。
防范方法
一个有效的方式(https://101.lug.ustc.edu.cn/Ch06/supplement/#fn:1)是通过修改系统配置,限制一个用户能够拥有的进程数量多少。ulimit -u 30 可以限制当前用户能够拥有的进程数量为 30。
动/静态链接
1 | gcc -o hello hello.c |
使用到第三方的库需要加上 -l 参数指定在链接时链接到的库。 对于复杂的应用来说,下载后可能会因为没有动态链接库而无法运行。 而静态链接则将依赖的库全部打包到程序文件中。
1 | $ gcc -o hello-static hello.c -static # 编译一个静态链接的应用 |
此时编译得到的程序文件没有额外的依赖,在其他机器上一般也能顺利运行。代价则是消耗更多的空间,并且可能产生性能损耗
交叉编译
有时需要开发另一个系统的程序,此时就需要交叉编译来实现,比如使用mingw编译windows程序 1
2
3
4
5
6
7
8
9
10
11
12
13$ sudo apt install gcc-mingw-w64 # 安装 mingw 交叉编译器
$ sudo apt install wine # 安装 wine Windows 兼容层(默认仅安装 64 位架构支持)
$ x86_64-w64-mingw32-gcc -o hello.exe hello.c # 编译为 64 位的 Windows 程序
$ file hello.exe # 确认为 Windows 程序
hello.exe: PE32+ executable (console) x86-64, for MS Windows
$ wine hello.exe # 使用 wine 运行
it looks like wine32 is missing, you should install it.
as root, please execute "apt-get install wine32"
wine: created the configuration directory '/home/ubuntu/.wine'
(忽略首次配置的输出)
wine: configuration in L"/home/ubuntu/.wine" has been updated.
Hello, world!
docker
Dockerfile 是构建 Docker 镜像的标准格式,下面会举一些例子。我们会基于这些例子简单介绍 Dockerfile 的语法。
构建简单的交叉编译环境
这个例子尝试使用 Debian 仓库中的 RISC-V 交叉编译工具链与 QEMU 模拟器构建一个简单的用于交叉编译的环境。
1 | FROM debian:buster-slim |
通过使用 docker build,我们可以构建出镜像。
1 | sudo docker build -t riscv-cross:example . |
Docker 在根据 Dockerfile 构建时,会从上到下执行这些指令,每条指令对应镜像的一层。Docker 容器镜像的独特之处就在于它的分层设计:在构建镜像时每层的更改会叠加在上一层上(这意味着,上一层的所有数据仍然会保留,即使在新的一层删除了);如果某一层已经存在,Docker 会直接使用这一层,节约构建的时间和占用的空间。 因此构建镜像应尽量减少层数避免空间浪费