具身智能论文阅读笔记
关于具身智能领域的论文
- Semantic Mapping 语义地图
- survey
- DualMap: 在线开放词汇语义建图助力智能体自然语言导航
- ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
- Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
- Open Scene Graphs for Open-World Object-Goal Navigation
- stage 1 summary
- Map-SemNav: Advancing Zero-Shot Continuous Vision-and-Language Navigation through Visual Semantics and Map Integration
- Multimodal Data Storage and Retrieval for Embodied AI: A Survey
- Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
- Embodied-RAG: General Non-parametric Embodied Memory for Retrieval and Generation
- Context-Aware Graph Inference and Generative Adversarial Imitation Learning for Object-Goal Navigation in Unfamiliar Environment
- Meta-Memory: Retrieving and Integrating Semantic-Spatial Memories for Robot Spatial Reasoning
- ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
- 3D-Mem: 3D Scene Memory for Embodied Exploration and Reasoning
- GraphPad: Inference-Time 3D Scene Graph Updates for Embodied Question
- RACCOON: Grounding Embodied Question-Answering with State Summaries from Existing Robot Modules
- Unleashing Cognitive Map through Linguistic-Visual Synergy for Embodied Visual Reasoning
- RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Learning in Physical Embodied Systems
- E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
- stage 2 summary
- DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
- Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
- Semantic Visual Simultaneous Localization and Mapping: A Survey on State of the Art, Challenges, and Future Directions
- Semantic Enhancement for Object SLAM with Heterogeneous Multimodal Large Language Model Agents
- Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
- DynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
- Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
- RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
- IROS: A Dual-Process Architecture for Real-Time VLM-Based Indoor Navigation
- FSR-VLN: Fast and Slow Reasoning for Vision-Language Navigation with Hierarchical Multi-modal Scene Graph
- RAG-3DSG: Enhancing 3D Scene Graphs with Re-Shot Guided Retrieval-Augmented Generation
- 语义点云/slam总结
- Vision-Language-Action Models
- 实例
具身智能: 集成了物理上的机械以及 ai(一般是常用的机器学习模型)的一种智能体, 这个词与 robotics(机器人学)的区别是, 后者较为关心硬件上的很多问题, 以及操作系统等偏底层的问题; 而具身智能较为关注抽象层面的智能, 暂时屏蔽掉底层的一些细节
Semantic Mapping 语义地图
survey
前言
语义地图以结构化的方式捕获环境信息, 让代理能够利用这些信息进行推理
由于具身智能面对的现实问题复杂性, 它会需要很多种 ai 技术, 单单是抓取一件物品, 就需要包括视觉辨识, 自然语言的理解与推理, 导航, 操控机械臂的能力等等
在这一系列任务中, 辨识理解环境是第一步, 在认知科学中, 研究者发现人类和动物实际上也会将现实的空间抽象化为一种“认知地图”, 也就是说, 对我们的大脑来说, 一处地点在脑中的印象不只是一些有长宽高形状的障碍物, 还有名称, 物理性质, 用途之类的“语义”, 这一定程度上启发了研究者使用类似的机制让 ai 理解环境, 也就是语义地图
为了方便, 将建立(语义)地图的过程简称为映射(mapping)
对于导航, 寻物等任务, 当前主流的流程可分为三步:
- 将当前的环境合理地建立数据模型
- 定位自己的当前位置
- 路径规划
智能机器人可以分为很多种, 我们只考虑不联网(用不了 gps), 没有复杂传感器的一类, 就叫 bot 吧, bot 想建立地图, 最直观的方法就是以自己为中心开始认知环境, 这就有点类似人类的认路, 对这种机器人来说,1. 2.其实可以视为一体, 因为在对当前环境建模的过程中可以自然地知道自己的位置, 主流的技术也是这么做的, 称为 simultaneous localization and mapping (SLAM)
总结一下, 接下来要讨论的 SLAM 是一种对环境的不断认知地同时进行地图制定及定位的一种技术
现在设想一个传统印象里的机器人, 它可能有光学或者声学的某些传感器, 这些传感器能很容易地捕捉到附近的障碍物, 这和初中生物讲的蝙蝠超声波定位也没什么本质区别, 但这些障碍物信息并不包括语义信息
附带语义的 slam 称为 semantic slam, 常见的做法是对传感器画面做特征提取, 例如可以提取成一系列词汇, 这称为 Bag of Visual Words, 得到这些词后, 查找词典匹配到一个具体物品; 如果想要更好的效果, 则可以进行深度学习
名词介绍
如果我们想要真正能用的机器人, 就不得不想办法让它能理解概念性的东西, 例如自然语言里的上下文, 词义向量, 而在具身智能的问题场景中, 则需要带有语义的地图, 例如客厅和餐厅都摆着大桌子, 要区分这两种房间就需要很多上下文信息
以下开始介绍一些细节, 首先是地图的表示方法(结构), 考虑室内这个场景, 由于其最大高度是固定的, 因此可以比较方便地使用 2d 的拓扑图, 网格来表示, 除此之后也可以使用 3d 的点云或者其他混合结构
我们首先做的是物体辨识和分类问题, 在室内, 例如普通住房中, 房间、家具的种类都是有限且数量级很小的, 对于机器人, 用内置芯片的算力可能就能做出来, 在机器人探索的过程中, 得到的各个空间、物体关系可以不断存入语义地图中供之后调用, 例如让机器人找一个苹果, 它能发现苹果在冰箱里面, 拓扑关系上可能就是客厅-冰箱-苹果, 这样之后找苹果也可以跟着这条路径走
开放词汇语义地图(Open-Vocabulary Semantic Maps): 系统能够识别和处理未在训练中见过的新对象或特征, 而不仅仅局限于预定义的类别; 与其相反的情况就可以视为是一个分类问题Embodied AI tasks: 大致可分为: 探索、导航、操纵, 更细粒度的划分可以使用目标的类型, 例如图像目标比定位上的目标需要更细的信息End-to-end | Modular approaches: 前者直接用传感器信息生成行动, 优点是对中小型任务效果不错, 但复杂的 3d 空间, 长期路径规划等任务中表现不佳, 此外也无法复用; 后者会将输入信息投入不同模块中处理例如编码器, 映射, 探索等, 最后生成行动, 优点是各个模块可以分开训练或者使用预训练模型- e2e 相关
intermediate map representation: 输入和输出之间的中间数据, 一般用于提取关键信息egocentric map: 从个体的视角(通常是观察者或移动体的视角)表示环境的地图
- 模块化相关
- 一般包括:
visual encoder、mapper、exploration(决定去哪探索)、planner(决定机器采取什么动作), 以上提及的这些是顺序关系 - 视觉编码器: 将观察转化为带有语义的编码, 一般使用预训练的模型, 最后可以将检测到的物体放入标好名字的 box
- 映射器: 接受编码器的特征信息, 构建语义地图
- 探索: 类似红警 2 的探图能产生信息优势, 由于知道越多的地图信息应该是越好的, 因此设置这个模块鼓励智能探索未知区域, 优先探索哪边可以选取合适的方法, 例如图文相关型, VLM 输出的最佳方向
- 计划: 在地图建后, 需要指定导航路径, 这部分取决于机器的运动方式等细节
- 一般包括:
Active SLAM: 强调机器人自己能选择以某种方式主动收集地图信息用于映射, 比如自己走几步, 让摄像头拍到更多画面, 也就是相比 ALAM 增加了 planning 部分
具体环节:
localization: 非常依赖于传感器, 由于本领域相对不关注底层细节, 一般假设每次采样都获得了最佳结果或者每次行动都实现了理想的位移- 由于现实中不可能有理想情况, 我们有
Loop Closure(闭环检测)这样的算法来矫正误差, 该算法会利用再次访问之前访问过的地点时的数据矫正对行为位移的估计值
- 由于现实中不可能有理想情况, 我们有
feature extraction: 关键部分, 后文详细介绍projection: 存储 3 维地图是一件非常难的事, 而且常识上高度轴上的物体关系较简单, 因此我们常用 2 维地图, 学习时将 3 维信息添加到 2 维地图上, 如果我们通过相机来获取空间信息, 那么过程就是, 根据相机的内置功能算出物体的世界坐标(X, Y, Z)将世界坐标投影到 2 维地图坐标(x, y),Accumulation: 上一步中可能遇到不同的物体堆到同一个二维点的情况, 为此有很多方法, 例如取最大, 取平均, 等, 其中可学习的方法可以有带有 LSTM 或者 GRU 的 RNN
此外还有一些权衡的地方:
- Egocentric vs allocentric
- Tracking visited areas
- View point selection: 固定视角的摄像头或者全局摄像头
- Online vs offline map building: 考虑到盲点等问题, 一般 online 是更好的
- 现实世界的复杂性: 例如我们以上提到的 localization 假设与现实肯定不符的
总结一下常见的问题:
- 计算量较大: 尤其对于本地模型来说, 更需要优秀的算法, 部分任务还会要求低延迟
- 容量需求: 对复杂的场景, 传统地图已经很庞大了, 加上语义, 复杂度更高, 储存和更新都是个问题
- 噪声: 现实世界的噪声很多, 还有各种随机因素, 学界目前没有很好的过滤方法
- 动态的环境: 如果环境不断变化, 现有的方法可能无法有效地更新
- 语义理解: 这部分较为依赖 clip 之类的视觉语言模型或者 llm
- 可用性和可靠性: 事实上, 目前的 em-ai 都很难落地
- 标准化: 目前的机器人或者 ai 社区使用不同的系统或者平台
地图结构
- Spatial map building
我们将地图做成一个(M×N×K)的网格, 其中(M, N)是空间上的维度, K 是语义上的 channel, 一般来说过程是这样的: 划分输入图片-> 把图片投影到自我为中心的地图 ego_map -> ego_map 注册进外部坐标系的 allo_map -> 降噪
- Topological map building
类似图论, 用(v, e)两个集合就可以表示一个图, 节点和边可以各自携带语义, agent 在更新中定位或者新建自己所处 node, 并可以根据一轮中学习的信息对整个图进行修改
- point cloud map
由于成本较大, 这方面应用有限
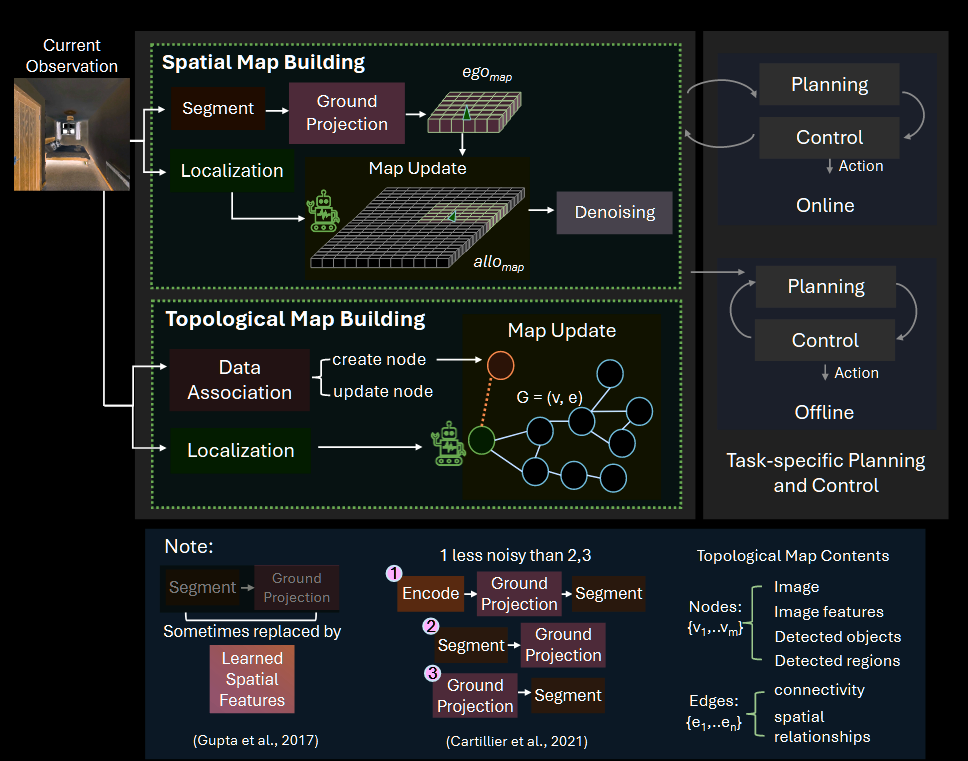
下面对各个结构详细介绍
Spatial grid map
现在对室内具身智能的研究通常用 MP3D, HM3D 等数据集, 这些都是对现实空间的 3d 建模, 都小于 1000 平米, 一个 cell 表示 400-900 平方厘米的空间, 有时也会再拓展一个高度维
早期研究直接使用自我中心的映射, 并直接端到端训练, 这样的缺点是无法认知到全局的空间结构, 甚至还会忘掉过去的学习结果, 于是就需要得到外部坐标系的空间地图
但由于智能体只能观察到自己传感器的部分, 也就是其观察内容是自我中心的, 所以想要得到外部坐标系的空间模型, 就需要有一种办法通过一次次的观察结果一笔一笔“画”出全局的地图
我们将这种办法称为 registration 注册, 也就是将每次的自我中心观察提取到的图像特征一点点放进全局地图, 这其实和人类画地图的方向比较像
每一轮中, 将观察信息融入到一些特定的 grid cells, 如果有重叠, 则通过某种方法把两个值叠加为一个结果值, 这种叠加称为 aggregation(聚合)
有一种基于注册的方法叫做 MapNet, 即通过使用已知的相机内参和对深度的测算, 将 egocentric 图像特征投影到一个 2D 俯视网格上
它执行 注册 的方法是: 首先获取一系列旋转多次后的 egocentric 地图, 然后与之前 allocentric 地图进行 密集匹配, 以确定代理在地图上的当前位置
另一种方法是: 直接通过相机内置函数将图片像素转化为(相对于相机的)3d 坐标, 由于相机的 pose 我们是知道的, 所以可以直接将其转化为世界坐标, 并将其体素化, 投影到 2d 平面时, 我们可以把这些体素的 weight 也压上去
这样的缺点就是太依赖相机功能, 对于现实的噪声敏感, 需要额外的降噪步骤, 使用这种方法的 Semantic MapNet 和 MOPA 都各自用了一些降噪算法, 前者还发现, 先对图像编码, 然后投影, 最后执行分割会减少噪声, 甚至可以不去降噪
总结: 使用 grid 能比较方便地表示空间, 也能方便 agent 学习, 但固定的宽高对于变化环境不太方便, 而且内存占用较多
- 密集匹配(dense matching) : 计算机视觉和图像处理中的一种技术, 用于在图像或视频序列中找到像素级别的对应关系。与稀疏匹配(只在特定特征点上进行匹配)不同, 密集匹配试图为图像中的每一个像素找到对应的像素
- pose: 物体在三维空间中的位置和方向
- 体素(Voxel): 是“体积像素(volume pixel)”的缩写。它是三维空间中的最小单元, 具有位置、大小和属性(如颜色、密度等)
- 体素化(voxelized): 将三维空间中的物体或场景表示为一组 体素(voxel) 的过程
Topological map
拓扑图更注重节点(地标)之间的关系, 这其实也是人类认路的一种方法, 符合常识, 但缺点是抽象层级较高
首先考虑怎么表示给出一个空间, 怎么画它的拓扑图, 什么是节点, 什么是边呢?符合直觉的想法是, 节点有较为重要的语义信息, 例如是一种房间的典型物体, 而边描述节点之间的连接性, 常见方法中节点通常存储图像特征或时间信息 (访问时间戳) 等信息, 而边缘可以存储一对节点之间的相对 pose
实际训练中, 可以让模型预先跑几遍结合这几次的轨迹画出一个 graph, 然后的规划过程寻找 graph 中最接近的节点, 这称为 Semi-Parametric Topological Memory (SPTM), 这种做法有很多缺点, 例如预探索可能有很多没走到的路, 不适合未知场景等
为了解决这种问题, 我们需要让 agent 能实时地感知到自己有哪边不了解, 应该先探索那边, 也就是 online 学习, 一种做法叫 Neural Topological SLAM (NTS), 它使用 Graph Update 模块更新 map, Global Policy 模块对 map 采样, Local Policy 模块输出离散的导航行动; 其中图更新模块作用如下:
- 定位: 尝试将智能体在前一个时间戳的图中进行定位
- 对已存在节点:
- 如果智能体成功定位到一个现有节点, 便在该节点与上一个时间戳的节点之间添加一条边
- 存储两个节点之间的相对 pose
- 如果智能体无法定位, 则在图中添加一个新节点
这就产生了另一个问题, 什么情况下是在已有节点, 什么情况下要新增节点呢?这需要判断两个观察值是否相似, 可以视为一个分类(二分)问题, 用一个既有的分类器计算, 也可以用可达性估计或者一些预训练的无监督网络处理(附近拍的观察可以视为一类, 这样就不用手动标注)
与网格地图相比, 拓扑的空间占用少, 但也因此可能漏掉细粒度的信息
Point-cloud map
用过建模软件的都知道, 出于优化性能考虑, 复杂的模型经常用三角形 mesh 表示, 由于训练智能体大多是在虚拟环境中, 点云与 meshes 有不错的适配性
而对于语义信息, 可以直接为每个点赋予一定的寓意, 最后我们就得到了一个不那么传统的 map, 我们一般用一个神经网络来赋予每个(x, y, z)点一个语义向量, 这个网络称为 neural field
这方面的应用暂时不算多, 点云更多被用在场景理解或者分类上, 这里暂且略过少数几个例子
光看简介就能看出来, 点云的计算和存储成本都很高, 并且对于稀疏的场景, 提供的信息可能也不足, 是一种有待探索的结构
Hybrid map
混合方法也是常见的思路, 一些相关的应用有:
- 拓扑更能捕捉空间之间的关系, 而 grid 更有距离上的细节, 两者结合称为
topometric map- 例如, 先生成一个粗糙的拓扑图, 根据拓扑图完善一个细粒度的 grid; 实验发现, 拓扑图能修正一些巨大的测量问题, 也就是全局问题, 而网格则能更好地解决局部问题
- 另一篇文章中, 为了处理紧凑的环境, 作者将转角和走廊用拓扑表示, 房间则用网格表示, 由于一般来说我们只需要房间里有详细的信息, 而对交通空间不关心具体情况
- 以上两篇都比较古早, 最近的一种基于 bert 的文章离线训练 hybrid maps, 然后训练一个多模态模型进行语言指导式的空间推理
- 还有结合三者的, 网格存储 occupancy(障碍物)信息, 拓扑图存储地标及其连通性, 点云则存储详细的语义信息
- 构建能够捕捉场景语义层次的地图可以实现不同层次的推理, 例如不同的节点实际上在不同层级(坐标系)中而, 边表示坐标系的转化关系; 除了分层, 还可以额外存储物体, agent 之间的时空关系, 实验证明分层的场景表示对复杂的环境效果更好, 这样的技术甚至可以用来对城市的交通系统进行建模
混用这些地图结构时需谨慎考虑各自的特点, 例如拓扑和点云地图在大环境中比网格地图更具可扩展性, 但点云需要更多存储空间, 拓扑地图所需的存储空间最少
地图编码 map encoding
地图编码是指将信息通过某种方式存储在语义地图中, 而这些信息可以分为隐式和显式的, 显式指的是可以被直接解释或者理解的信息, 例如像素的颜色, object 所属的类别等; 隐式则指一些提取出来的特征, 无法被直接地理解
显式编码
那么根据常识, 至少障碍物信息, 也就是 occupancy information 信息是很值得显式存储的, 并且可以用一个 bool 就能表示是否占用的二元关系
此外, 为了鼓励 agent 探索未去过的区域, Active Neural SLAM 方法会存储一个 bool 值表示是否已探索
而对于更复杂或者更长期的任务, 例如针对语义目标的导航任务, 就需要额外存储语义信息, 例如 SemExp 会额外存储 agent 认知的语义类别标签, 这些标签通过 MaskRCNN 产生, 在 aggregate 时使用 element-wise max pooling(取各个子区域里的最大值), 且保留最新的预测值
首先将图像分割再投影会造成 label splattering 现象, 也就是一些噪声标签会散布到多个 grid cells, 这是因为对深度的观察会受到环境噪声的影响; 但首先投影编码后的特征再分割能实现一定的降噪效果(需要预探索)
此外, 图像, 文字, 目标检测概率(对目标属于某个类别的置信度评分)等值也可以作为存储标签, 近年一些图文, 图图匹配也有不错的效果; 存储音频信息(例如声音强度)的地图在视听导航任务中也有作用;
以上都是网格地图的应用, 拓扑图中, 可存储每次都会替换更新的访问时间戳, 用来表示地点之间的时间相对关系
总结: 显式编码的优点是其可解释性, 对于具体的任务, 我们可以选择常识上有益的信息类型并编码存储, 但是这较为依赖人类对问题的理解
隐式编码
大部分的早期工作使用预训练的基于封闭词汇表的视觉模型提取特征, 例如 cnn, 近年来, 更多使用预训练的基于开放词汇表的大型视觉-语言模型
封闭词汇表:
可以使用 cnn 或者流行的 vision model 例如 ResNet 除了图像以外, 也可以根据可微分的映射器和 planner 进行非监督学习, 通过计算微分, 模型可以不断优化性能, 地图则可以通过 differentiable warp 不断集成
开放词汇表:
封闭词汇表最大的漏洞是: 无法编码不认识的特征, Large Vision-Language Model (LVLM) 如 CLIP 可以缓解这个问题, 这些模型有庞大的训练资料, 对于不认识的物品, 可以通过已有知识建立新的类别
CLIP 有强大的图文匹配能力, 利用这点, 可以在 2Dmap 中存储图文相似得分(value maps), 这在下游应用例如 zero-shot 的语言驱动的导航中表现良好, 也有论文将其拓展到 3D
尽管其匹配能力相比封闭词汇表十分强大, 但仅限于图片和文本的匹配, 依旧缺乏更详细的语义和空间信息, 因此空间推理能力欠缺
为了增强推理能力, 需要找到判断物体在图片中的位置, 以及提取特征的方法, 一个思路是对图片的所有像素嵌入一些特征, 根据摄像头的深度信息, 可以得知这些像素对应 3d 空间的坐标, 随后投影(聚合)到 2d 网格上, 在查询时, 先从输入提取出物品名, 再和这些像素匹配
这个方法的缺点是, 并没有做到物体级别的语义, 可能忽略了空间上的一些关系, 此外很多像素可能就是空气, 毫无语义信息, 没有必要存储。24 年(OneMap)的一种方法使用分层的编码器缓解了这个问题
NLMap(grid): 如果想直接辨别图像里的物品, 则可以使用 class-agnostic region proposal network 来划分出感兴趣的图像区域(region), 对于这些 region, 提取特征并将其存入 3d map(携带坐标和估计的大小信息), 这样一来, 对每次查询(会被先转化为物体名), 只要查找匹配度最高的 region 就可以了
ConceptGraphs(topo): 使用无类别的 2d 分割算法划分出物体, 这些物体可以直接作为拓扑图的节点并存储一些信息, 除了特征信息外, 例如对其的描述, Candidate Masks 的点云等也可以存储。接下来考虑边, 在这种方法中, 考察物体的点云是否有几何相似性或者重叠部分, 有两个物体的点云重合度到达一个阈值, 则认为它们是空间相关的, 从而建立边。边也可以额外存储信息, 例如大模型对链接方关系的描述
开放词汇表映射编码的优点是它可以一次构建, 然后复用到不同的下游任务。它可以有效地使用开放词汇表进行查询, 并且具有较高的可解释性
缺点是, 当前阶段大模型的训练开销和计算开销都极大
Zero-Shot Manner(零样本方式): 在机器学习和人工智能中, 模型能够在没有针对特定任务或类别进行微调的情况下, 直接执行任务的能力class-agnostic region proposal network: 一种用于目标检测的网络架构, 旨在生成图像中潜在目标的区域分割, 而无需事先知道目标的具体类别, 如ViLDCandidate Masks: 计算机视觉中的一种概念, 通常用于目标检测和图像分割任务。它们代表了图像中可能包含目标的区域或对象的区域
地图评估 Map Evaluation
很明显, 对智能效果最直接的评价标准就是 agent 执行任务的效果, 因此目前对 map 的评估较少, 本文讨论如何从准确性, 完整性, 一致性, 健壮性以及实用性的角度评价地图对于下游任务的功效
- Utility 实用性: 大部分工作将语义地图作为一个中间步骤, planner 使用它来规划路径, 产生动作指令, 如果我们只用地图做这一件事, 那么直接看任务完成地怎么样就是最好的评价标准了; 但对一些和地图有关的任务, 例如导航、勘探, 则也可以用覆盖率, 导航准确性等作为指标
- Accuracy 准确性: 地图准确度是指与现实地形进行比较时, 地图捕获语义信息的准确度, 问题在于, 很多时候现实的地理信息较难获取。如果只论语义的比对, 则可以使用一些语义分割上的指标, 与智能的语义划分进行比对; 还有一个问题是, 这种比较对常常种类有限的显式特征较为方便, 但对隐式的特征则无从下手, 对此只能再用一个分割器将隐式转化为显式, 又或者人工评估
- Completeness 完整性: 地图是否完整地表示环境, 这包括了几何和语义层面。这点很大程度上取决于机器人在下游任务中探索环境的彻底程度, 并且与 “停止标准
stopping criteria” 密切相关, 一般来说, 会在任务完成或者达到时间限制时停止; 而语义上的完整则很难测算, 几乎没有成熟的方法 - Consistency 一致性: 几何一致性指的是地图的空间结构能反映环境物理布局的准确性, 不严谨的说可以视为地图局部细节(距离, 角度, 物体相对位置)的准确性, 模拟环境下不存在传感器噪声, 因此几乎可以不考虑, 但实际情况中, 由于各种因素影响, 代理可能错估自己走过的距离, 相对位置等, 从而破坏一致性; 语义一致性则指随着机器人运动, 语义信息和物理位置能否对齐。由于当前还处于理论阶段, 这方面的研究尚且不足
- Robustness 健壮性: 在不可预测或动态环境中的可靠性, 由于现在大量使用预训练模型, 可以用预测的置信度来评估; 此外也可以使用模型预测的方差来评估, 但由于能落地的应用有限, 这方面的研究也比较缺乏
展望未来与结语
当前的趋势为创建灵活、通用、开放词汇和可查询的地图, 以支持多种任务; 为了提高空间推理能力, 密集, 可扩展和内存高效也是一种方向
- General-purpose maps: 由于机器人任务多样化, 通用的模型明显有着重要意义, 更有通用能力的开放词汇表也可能是趋势, 这需要对计算成本和内存消耗的平衡
- Dense yet efficient maps: 为了更好的空间推理能力, 需要高密度的地图, 但又为了计算效率, 需要其尽可能节省内存和算力, 常用方法中拓扑图过于稀疏难以捕捉细粒度信息, grid 难以处理多层面信息, 点云则过于密集, 性能消耗大, 可能需要一个更好的结构
- Dynamic maps: 当前的地图技术基本都是基于静态环境, 对动态环境如室外的交通, 则很难有高效地建模方法
- Hybrid map structure: 上文已经提到过混合结构的优点, 但如何融合或者切换也是值得研究的方面
- Devising evaluation metrics: 与下游任务中代理表现的评估相比, 语义地图的评估在具身 AI 研究中受到的关注较少。为了推动该领域的发展, 需要强调使用准确性、完整性、一致性和健壮性等指标对地图进行评估
DualMap: 在线开放词汇语义建图助力智能体自然语言导航
背景
鉴于近年 ai 领域的发展, 机器人领域逐渐开始研究对于自然语言理解能力的集成, 对此可以分为 3 种任务:
- 开放词汇理解
- 高效地在线建图
- 动态环境导航
一些经典方法如 yolo(深度学习的对象检测模型), 虽然表现较为不错, 但鉴于它基于封闭的词汇表, 对于 "不认识" 的类别是没有辨别能力的
而所谓的开放词汇, 就是需要让模型能够理解没见过的类型, 并逐渐学习怎么更好地分类和认知, 常见的方法有:
- 通过图像标注模型标出标签, 再根据标签使用基于封闭集合的检测器, 不过图像模型成本较为高昂, 很难在线学习
- 类别无关分割: 使用一种不依赖具体类别的专用分割模型, 再借助视觉基础模型(VFM)提取语义特征, 开销也较大
其主要的创新点正如其名, 在开放词汇的基础上使用两种地图, 空间占用较低的抽象地图用于导航任务, 具象地图在需要更多细节时用于参考
DualMap 的改进
开放词汇的目标分割
利用 llm 提供类别, 让 yolo 快速生成粗略的目标检测结果, 并通过 mobileSAM 生成分割掩码; 同时让 FastSAM(开放词汇表分割模型)捕捉 yolo 的封闭表外的对象(这步可能会过度分割, 之后还会进行合并操作); 对两者进行融合时 yolo 优先, 补充不重复的 FastSAM 片段; 这样的设计主要是为了使用成本较低的 yolo 和 fastsam, 从而实现在线学习
这里补充一下对每一帧 I 的处理, 事实上有三个模块会并行地使用 I, 即上述的 YOLO, FastSAM 以及一个点云生成器, 点云地图和语义信息无关, 只是用于提供空间布局语义特征处理
由于我们希望能让机器人做到能理解模糊的指令, 就需要让地图也携带语义信息, 这方面也有很方便的图文嵌入模型例如 CLIP, CLIP 提供对图像的编码功能, 在第一步的分割后, 对裁剪出的图像区域编码为 \(f_{image}\) , 如果之前的分割给出应该类别标签, 对标签编码为 \(f_{text}\) , 最后通过加权求和得到总的特征
\[\mathbf{f}=w_{\mathrm{image}}\mathbf{f}_{\mathrm{image}}+w_{\mathrm{text}}\mathbf{f}_{\mathrm{text}},\qquad\mathbf {f}_{\{ {\mathrm{image,~text}\}}} \in\mathbb{R}^{d}\]
对于 FastSAM 标记为“null”的对象, 用所有已知类别嵌入的归一化平均文本特征替换 \(f_{text}\) , 以消除语义偏差观察结构
摄像机拍到的一帧为 I, 每个 I 提取出一个观察集 Z, Z 由 N 个片段 \(z_i\) 组成, z 称为观察 , 可表示为: \(z=(P_{z},f_{z},y_{z},t_{z})\)
其中 P 表示分割区域从深度图投影到世界坐标系中生成的 3D 点云; f 表示之前我们得到的语义特征; y 表示 yolo 检测的对象类别, 对于 fastSAM 分辨出的则设置为 null; t 为观测的时间戳场景建模
本模型使用点云对场景建模, 但为了减少性能消耗, 只在遇到姿态变化大的帧时通过投影(相机带有深度信息)更新点云(这个更新线程并行低频运行)
dualmap 最大的特点正如其名, 使用两种 Map, 下文分别介绍
具象地图
地图初始化
地图有一系列对象组成, 每个对象, 这里称为 o, \(o=(P_{o},y_{o},f_{o},L_{o})\)
其结构类似于观察 z, 但其中的 L 记录与对象关联的观测集, 即L=set{z}地图更新
当新的观测集合到达时, 系统开始新一轮匹配(第一轮所有观测 z 都会分配一个对象 o), 定义一个相似度矩阵 \({ S}\in R^{\mathbb{N}{\times}\mathcal{M}}\) , 从点云重合度和语义相似度两个角度衡量
\[S(z_{i},o_{j})=\mathrm{cos}(f_{z_{i}},f_{o_{j}})+\mathrm{Overlap}(P_{z_{i}},P_{o_{j}})\] 而更新条件用一个简单的阈值 \(\tau\) 表示, 超过阈值认为是相同对象, 更新过程则是对 f 求新增一个 f 后的平均, 扩充点云, L 内部新增加一个观察 z; 否则新建对象地图维护
一般来说, 语义地图最“昂贵”的地方就是对 3d 物体进行合并, 为了避免这种开销, 通过轻量级的内部对象状态检查来维护地图的保真度, 可分为:
- 稳定性检查: 对一个较长时间未更新的对象
- 如果有足够观测次数, 至少有 2/3 的类别是同一个, 则保留
- 否则删除
- 分割检测: 如果有若干连续帧(每一帧产生一个观察集)中在同一时间步内出现具有不同类别 ID 的观测, 例如对象 chair 连续 3 帧对应的时间步内有两个类别标签 chair 和 cushion
- 触发分割操作, 将对象的观测列表按类别 ID 分割并创建新对象
抽象地图
上一节我们讨论的地图依然是不包含全部语义信息, 只有对象(包括一些类别 id)信息的具象地图
而相比前者, 抽象地图牺牲易变对象, 只存储锚点对象, 且新增一些语义信息与空间关系信息, 具体包括:
- 锚点对象
- 首先使用两个代表性的锚点, 易变类别列表(list)对现有对象分类, 使用 CLIP 对对象编码得到特征 f, 如果 f 和两个列表的近似度相差达到一个门槛值, 则分到相似度更高的一类, 此时的门槛值较小, 仅设 0.05
- 除了 1.中的两个列表, 典型锚点对象的列表还有一个存储对应描述信息的列表, 对 1.中没有决定的对象, 计算其特征与描述列表的相似度, 这里设一个较大的门槛值 0.5, 并且强制二分
- 丢弃易变对象的非语义属性(因为对导航任务没用)
- 空间关系(易变与锚点对象之间), 以 on 关系为主:
- 以锚点对象点云的 Z 轴直方图以提取其支撑平面, 计算对象与锚点 2d 投影的重叠比例, 如果两者重叠且对象底部到支撑平面的垂直距离小于阈值, 则存在 on 关系
- 建立空间关系后, 易变对象的语义特征 f 将存储于对应锚点对象的特征列表 L(L 存储于其关联的易变对象语义特征), 对每个锚点对象 a, \(a\,=\,(P_{a},f_{a},y_{a},L_{a})\)
- 场景布局
- 将点云投影到鸟瞰平面, 划分出单元格, 对最密集的地方, 视为墙壁等结构物, 这种结构物只在新的查询请求到来时更新
导航策略
- 候选检索
对查询语句, 用 CLIP 编码为语义特征, 并与我们现有的锚点以及易变对象的特征集比较, 得分最高者作为候选, 候选锚点称为 a*
锚点得分的计算公式:
\[s(a)=\mathrm{max}\Biggl(\mathrm{cos}\big(f_{q},\,f_{a}\big),\,\mathrm{max\underset{i}\,cos}\big(f_{q},\,f_{v i}\big)\Big)\] 其中 q 下标表示查询, a 下标表示锚点对象, vi 下标表示易变对象
- 导航策略
- 全局路径规划: 使用基于 Voronoi 图的规划器在抽象地图上规划一条通往候选锚点的全局路径; 智能体移动时, 会逐步构建局部具象地图, 局部地图中的对象也可以用于匹配
- 局部路径规划: 对局部具象地图中的对象, 计算其特征与查询特征的余弦相似度 s, 如果 s 接近之前的全局候选相似度, 且正好在去之前的候选对象的路上, 使用 RRT*算法规划局部路径
- 动态环境导航: 如果 a*附近没有可信匹配, 那么环境可能变化, 系统会更新抽象地图 Ma'重新寻找候选
- Ma'会将局部具象地图中的稳定对象合并, 详解下文
- 更新地图后, 全局相似度分数依旧使用过去的版本, 即保留历史上下文信息
- 抽象地图更新
- 对局部具象地图中的稳定对象, 进行一轮抽象化得到新的锚点 \(a_{new}\)
- 每个 \(a_{new}\) 与现有的 a 比较, 计算重叠率
- 如果重叠率超过门槛值, 说明 \(a_{new}\) 和 a 有一定关系, 更新: \(f_{a}~\longleftarrow~{\frac{\left|P_{a}\right|\cdot{f}_{a} + \left|\mathcal{P}_{a_{\mathrm{new}} }\right|\cdot\ {f}a_{\mathrm{new}} } {\left|\mathcal{P}_{a}\right|\ +\left|\mathcal{P}_{a_{\mathrm{new} } }\right|} }\)
- 如果超过更严格的阈值, 则用 \(L_{a_{new}}\) 替代 La
- 如果以上都不满足, 将 \(a_{new}\) 作为新节点插入抽象地图中
RRT*(Rapidly-exploring Random Tree Star)算法: 一种用于路径规划的优化算法, 尤其适用于高维空间中的移动机器人和其他自动化系统; 使用随机采样的方法在配置空间中探索路径, 逐步构建一棵树, 与基本的 RRT 算法不同, RRT* 在扩展树的过程中, 会不断优化已有路径, 尽量减少路径的成本平均交并比(mIoU): 计算分割或检测任务中预测区域与真实区域交集与并集之比的平均值频率加权交并比(F-mIoU): 对 mIoU 的一种加权版本, 考虑了每个类在数据集中出现的频率, 将每个类的 IoU 乘以该类在数据集中出现的频率, 然后求和, 最后除以总频率
测试结构与总结
定义两种典型的变化: In-anchor relocation(和一个锚点有关的对象移动位置但不改变和锚点关系, 例如桌子上移动水杯)、Cross-anchor relocation(易变对象转换锚点, 例如从桌子移到架子上)
对锚内变化, dualmap 可以通过更新局部具体地图找到目标; 对于跨锚点变化, dualmap 可以通过更新抽象地图解决
与 ConceptGraphs 和 HOV-SG 相比, dualmap 在表现提升之外, 内存使用量大大减少, 相比 HOV-SG 减少了 96%以上, 这是因为其避免了 3d 合并开销, 抛弃了多余的易变对象非语义数据, 并执行稳定性检查减少噪声数据等
消融实验中, FastSAM、YOLO 细化、加权特征合并和对象分割检测等组件对性能有显著影响
附录
实验中存在一些问题:
- YOLO 可能会将不一致的类标签分配给同一对象的不同部分, 基于类别的合并将无法将它们识别为一个对象
- 对多个堆叠关系或者离得很近的类的对象, 容易导致错误合并
对合并问题, 在合并前使用一次额外的 rgb 检测尽可能经济地解决, 也就是对待合并对象画出 rgb 三个 channel 的直方图, 根据直方图计算余弦相似度, 超过一个阈值时才合并
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
来自 ICRA 2024
这篇论文写得比较早(2023), 所以前言部分这里写得简略一点, 在当时主流的技术往往是封闭词汇或者一些性能消耗大的开放词汇表(也就是携带语义特征的点云); 此外还有个痛点是难以表达结构信息
本文提出的感知图是一种以对象为中心的语义地图, 其几何信息由 3d 形式存储, 语义信息由 2d 形式存储
3d 对象生成
- 类别无关的 2d 图像分割: 当传入观察帧后, 使用分割模型得到一个掩码集合 { \(m_{t,i}\) } , 每个掩码得到图片片段, 将这个片段传入视觉特征编码器如 CLIP, DINO, 从而得到视觉特征向量; 此外对片段中的点, 根据深度形象投影到 3d 坐标系中, 对投影后的点云使用聚类算法降噪, 最后放入地图中; 最后我们得到了点云以及对应的单位归一化后的语义特征向量
- 对象中心的 3d 图: 令观察帧(rgbd)为 \(I={I_t}\) , 其中 \(I_{t}\ =\ \langle I_{t}^{\mathrm{rgb}},I_{t}^{\mathrm{depth}},\theta_{t}^{*}\rangle\) (color image, depth image, pose) 类似的, 图 M ={O, E}中的对象集合为 O, 边集合为 E
- 对象关联: 对每个新检测到的对象 \(o_t\) 即
<p,f>(点云和特征向量), 计算它与在 3d 图上有空间重叠的对象 \(o_{t-1,j}\) 的几何以及语义相似度- 几何相似度 \(\phi_{\mathrm{geo}}(i,j)\;=\;{\mathfrak{n}}_{\mathrm{nnratio}}({\bf p}_{t,i},{\bf p}_{oj})\) 也就是 \(p_{t,i}\) 中的最近的邻居点在 \(p_{oj}\) 中的点所占比率(有一个门槛值)
- 语义相似度 \(\phi_{\mathrm{sem}}(i,j)\,=\,\mathbb{F}_{t.i}^{T}\mathbf{f_{oj}} / 2+1/2\)
- 以上两种相似度的简单相加作为总体相似度, 权衡计算花费和表现后, 贪心地选择相似度最高的对象匹配(如果超过一个门槛值), 而如果不到门槛值, 创建一个新对象
- 几何相似度 \(\phi_{\mathrm{geo}}(i,j)\;=\;{\mathfrak{n}}_{\mathrm{nnratio}}({\bf p}_{t,i},{\bf p}_{oj})\) 也就是 \(p_{t,i}\) 中的最近的邻居点在 \(p_{oj}\) 中的点所占比率(有一个门槛值)
- 对象融合: 对上一步关联的两个对象, 进行融合, 融合过程就是一个简单的求平均: \({\bf f_{o j}}\,=\,(n_{o_{j}}{\bf f_{o j}}+{\bf f}_{t,i})/(n_{o_{j}}+1)\) 其中 n 是迄今为止(融合前)被关联到这个对象的观察片段数量, 点云部分则执行一个简单的并集操作, 并进行下采样降低成本
- 节点描述: 很实用主义的一步, 在我们暂时完成了一系列图像处理后, 对得到的对象, 将最好的 10 张图片送给 LVLM 处理, LVLM 生成对应的粗略描述, 再将其送给一个 LLM 生成一个最终描述
简单地概括一下, 上述主要处理空间和语义上的物体(对象)表示, 空间部分是从二维图片提取的点云, 确定点云时和语义类别无关, 直到确认后才编辑语义部分, 提取语义的过程也很单纯, 将图片发给 LVM 和 LLM 得到描述, 每个对象存储一个关于自己的描述
3d 场景图生成
之前已经得到了对象层面的抽象, 这部分主要处理对象关系
对每对 3d 对象, 计算器 3d 边界 Box 的 IoU 生成一个相似度矩阵, 并通过估计应该最小生成树 MST 来修剪矩阵, 从而得到数量可控的候选边
(可能有人好奇为什么之前的描述不进行编码直接存储, 这是因为后面还会对 LLM 会使用描述信息)
对这棵树的每条边, 将边对应的一对 obj 的描述和位置信息喂给 LLM, LLM 生成其可能的关系, 这个关系作为场景图的标签存储, 例如 on, in
之后, 对自然语言类型的查询, 让 LLM 读取一个存储好相关信息的对象列表, 找到最有可能的关联对象并将这个对象交给下游应用
当然还有一个很常见的思路是, 为什么不舍弃描述性信息, 直接使用 CLIP 之类的模型嵌入编码查询语句然后查找匹配对象呢? 答案很简单: 实验者尝试过, 但效果不如 LLM, 准确地说, clip 对描述性的查找表现不错, 但对于比较模糊的查询表现不佳
相比更近年的 dualmap, 这个模型还有一个比较直观的问题, 对动态环境无能为力, 但优点在于 llm 的泛化能力能解决很多导航问题, 例如一开始没找到之后去哪里找, 有障碍物的路径其障碍物能否推开等
场景图对象的 json 表示示例:
1 |
|
简评: 无疑这个系统很实用, 但过于依赖 LLM 了, 文本描述很可能不是最好的空间表示方式
- 下采样(subsampled): 简单地说, 尽可能保留信息地压缩原数据, 上采样与其相反
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
来自 RSS 2024
本文提出的模型简称为 HOVSG, 相比同行最大的特点在于它是分层结构的, 我们之前提到的工作往往只是用拓扑图基于一个简单的图论空间模型表示现实空间, 也就是对象层级的地图, 但对于更加复杂的现实空间例如多层建筑, 其表现力就会受限, 因此本文使用分层的模型增强表示能力
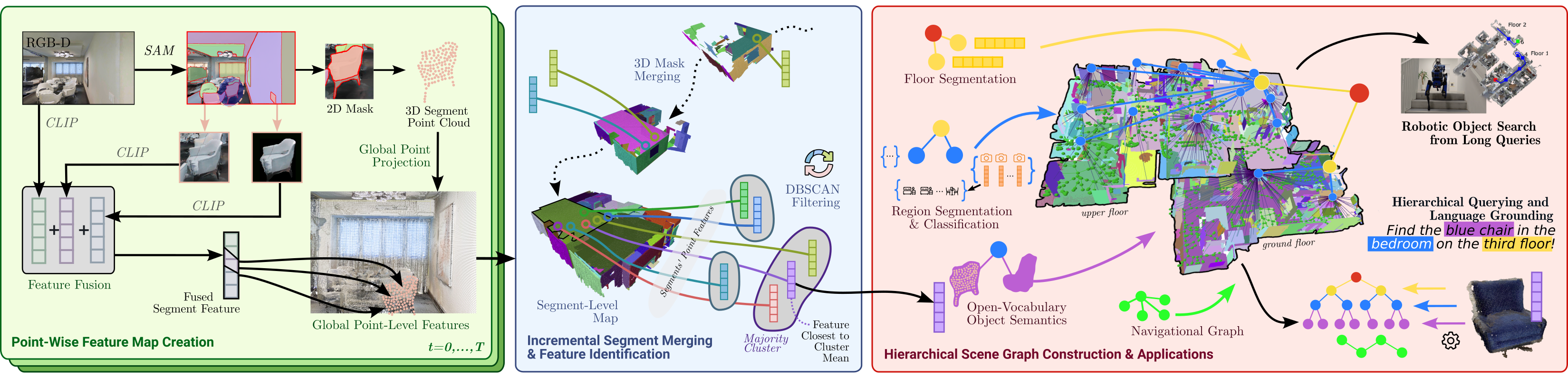
本模型专注于解决对有 rpgd 相机和里程计(里程计用于构建坐标系)的多层环境建图问题, 其最初的 3d 建图和上一章的感知图比较类似, 之后增加分层信息
下面介绍其流程, 和感知图类似的部分会略过
- 进行类别无关的分割, 并将片段投影为 3d 点云, 其合并算法与感知图不同, 重叠度记作: \(R(m,n)=m a x(o\nu e r l a p(S_{m},S_{n}),o\nu e r l a p(S_{n},S_{m}))\) 其中 \(overlap(S_a, S_b)\) 表示 Sa 中的点在 Sb 的邻域内(在一定距离内)的比率, 但合并不是一对对进行的, 而是构建一个全连接的图, 每条边存储连接的一对节点(片段)的重叠度, 这样就能找到一些重叠度较高的子图, 将所有子图一起合并
- 接下来开始计算特征, 这里还是用我们的老熟人 CLIP, 但有一些 trick, 由于之前的分割我们其实是有各个区域的掩码的, 按常识想, 似乎应该只把分割出的部分用来求特征, 但也有些工作会把掩码部分和整个图像都求特征算加权和, 根据本文团队的经验, 其特征也是加权和的形式, 写作: \(f_{i}=w_{g}f_{g}+w_{l}f_{l}+w_{m}f_{m}\) 其中 i 表示第 i 个 2d 掩码, g 表示整个图像, l 表示基于掩码的图像裁剪, m 表示在 l 基础上再去除背景的图像裁剪, 详细可参考上图左侧
- 接下来考虑怎么将算出的语义和点云表示的空间相关联, 这里简单地说, hovsg 采取了计算消耗最大的方法, 用 3d 点云存储语义, 但是会进行一定的优化
- 在准备阶段, 会预计算出大概的点云, 这称为参考点云, 而对在之前一步中得到的掩码区域, 会计算逐点特征并将其映射到(参考点云的) 3d 坐标系中, 映射中片段的各个点会与参考点云中的最近点匹配, 也就是语义特征会关联到那个对应点, 称为参考点, 在映射结束后, 对各个参考点关联到的语义算平均作为其最终语义
- 在 2. 结束后, 我们得到一个有逐点语义信息的参考点云, 接下来反过来从片段内的点出发匹配参考点作为语义, 之后在片段内用 DBSCAN 算法进行聚类(将最密集的聚类中最接近平均值的特征作为片段语义)达到降噪和规避模式崩溃的效果, 以上三步可参考上图中间, 也就是空间上每个片段只存储一个特征
- 在完成语义存储后, 接下来的任务就是构建场景模型, 本文的抽象数据结构是主流的拓扑图, 但在设计上有一些 trick , 准确地说应该是分层图
- 其中 \({\cal N}\;=\;{\cal N}_{S}\;\cup\;{\cal N}_{F}^{\;}\;\cup{\cal N}_{R}\;{ {\cup}}\;{\cal N}_{O}\) 其中 s 下标是根节点, 其他则是 floor, room, object 的简称
- 类似的, 边集合定义为 \({ \mathcal{E}}={ \mathcal{E}}_{S F}\cup{\mathcal{E}}_{F R}\cup{\mathcal{E}}_{R O}\) , 也就是自上到下的树状关系
- 以上的定义都比较常识化, 接下来讨论具体的实现:
- floor: 对目前已有片段的点云画出高度上的直方图, 然后寻找一些峰值(也就是找到点相对最多的高度), 具体来说, 只选择超过最高峰 90%或以上的峰值; 用 DBSCAN 选择每个片段点云中排名最高的两个峰, 用常识想, 应该其中最密集的高度是楼层底面或者天花板; 对最后得到的所有候选高度(存储为一个向量)排序, 文章假设每两个连续的高度对是天花板和地板的高度
- room: 基于划分好的层级, 画一个 2d 鸟瞰直方图, 由于一般墙壁处是最密集的, 用一个阈值就可以分离出大概, 然后用一个 EDF 加上分水岭算法完善分割; 同样基于常识, 房间应该有一些语义信息, 将一些观察帧用于嵌入, 用 k-means 方法选出 k 个代表; 推理时, 将一系列常见房间类别输入 clip 编码, 然后将这些编码和之前的房间代表信息计算余弦相似度, 这里的代表其实是个双关, 每个房间有 k 个代表, 这些代表每人一票投给与其最类似的房间种类, 然后根据票数或者投票分数决定房间种类
- object: 得到房间划分后, 我们其实就能知道之前的片段各自落在什么房间, 而对不落在任何房间里的对象, 将其与欧几里得距离最小的房间相关联, 类似之前的工作, 这部分也会进行重叠度高对象的合并(空间标准前文写过, 语义标准是对封闭词汇表的查询, 或者说分类任务, 有相同标签输出), 每个对象存储自己的 3d 点云, 片段信息, 特征和最大得分的标签
- 互动图: 对机器人来说, 很重要的是整个场景中物件的可交互性, 在本文的模型里, 还涉及对跨层交通的标注, 这使用一个 Voronoi graph(下文简称 v 图)实现; 在此前我们得到了各个楼层的地图, 将相机姿势作为一个个点投影到各层平面, 假设这些轨迹点的两两连线周围(有点像轨迹的描边)是可通行的, 此外, 根据高度范围
[ymin + δ1, ymin + δ2] 其中ymin表示楼层内的最低点高度, 而两个偏移是经验值的点画出障碍物地图; 对姿势区域图和楼层平面区域图做并集并减去障碍物区域图, 就得到了每层的自由空间图; 对跨层交通(楼梯), 将分类为楼梯的片段上的相机姿态点连起来, 然后寻找上下两层中与楼梯最近的点, 将这些点都连起来, 就得到了跨层区域
- 完成以上 3 步后, 现在我们已经得到了完整的语义地图, 对导航任务, 使用 LLM 将其分解为 3 个子任务, 也就是楼层、房间和对象, 分解后是一个常见的处理; 嵌入查询语句并通过比较余弦相似度选择候选
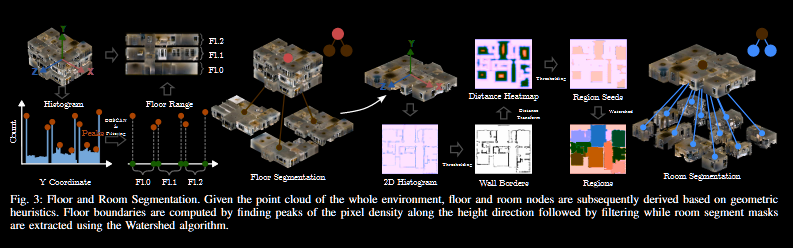
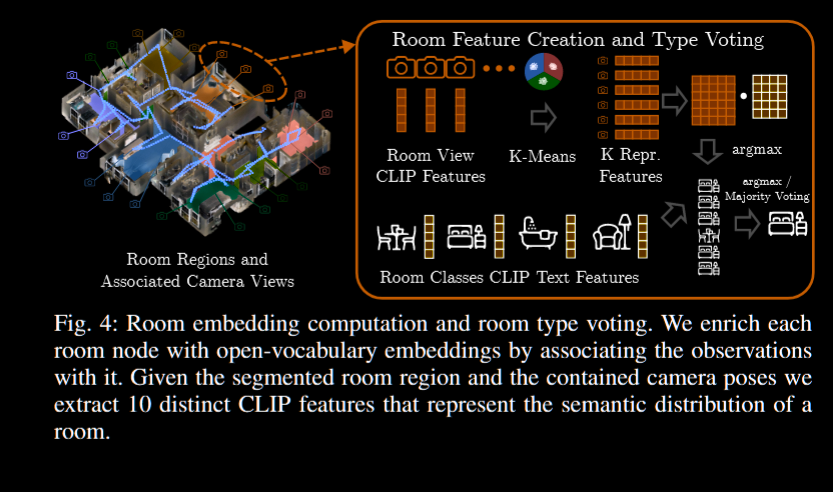
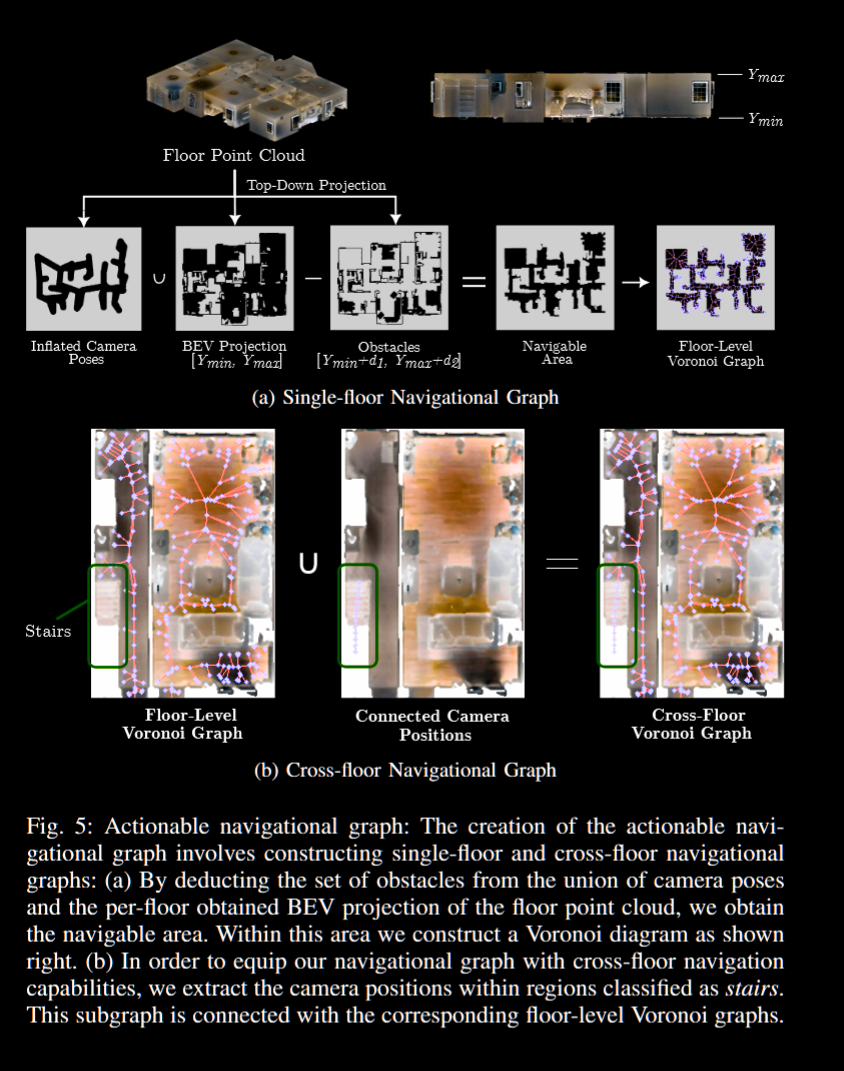
- 分水岭(Watershed)算法: 广泛应用于图像处理的分割技术, 特别用于图像的边缘检测和区域分割
- 欧几里得距离场(Euclidean Distance Field, EDF): 在一个给定的空间中, 欧几里得距离场为每个点分配一个值, 这个值是该点到某个特定形状(如物体边界或目标点)的最短距离
- Voronoi graph: 一种用于将空间划分为离散区域的图形表示方法, 其分割出的一个个单元是泰森多边形
实验
语义分割上, 用 mIOU 和 FmIOU 评估效果, HOVSG 对比基线模型有不错的提升, 作者将其归功于合并策略使用逐点计算的特征以及聚类算法; 此外使用掩码特征的加权和来降低背景图像的影响
对于房间分类, 作者比较了基于使用模型预测的房间内物体分类和真实分类数据为输入的 llm 预测和本文方法(特权和非特权), hovsg 战胜了非特权与基于 gpt 3.5 的特权方法, 惜败于特权 gpt4
对于对象语义信息, 提出一种新的度量方法 \(\mathrm{AUC}_{k}^{t o p}\), 也就是基于类别(为了通用性横坐标设置为 k%形式)画出 top-k 的准确率曲线, 并计算与坐标轴围成的面积
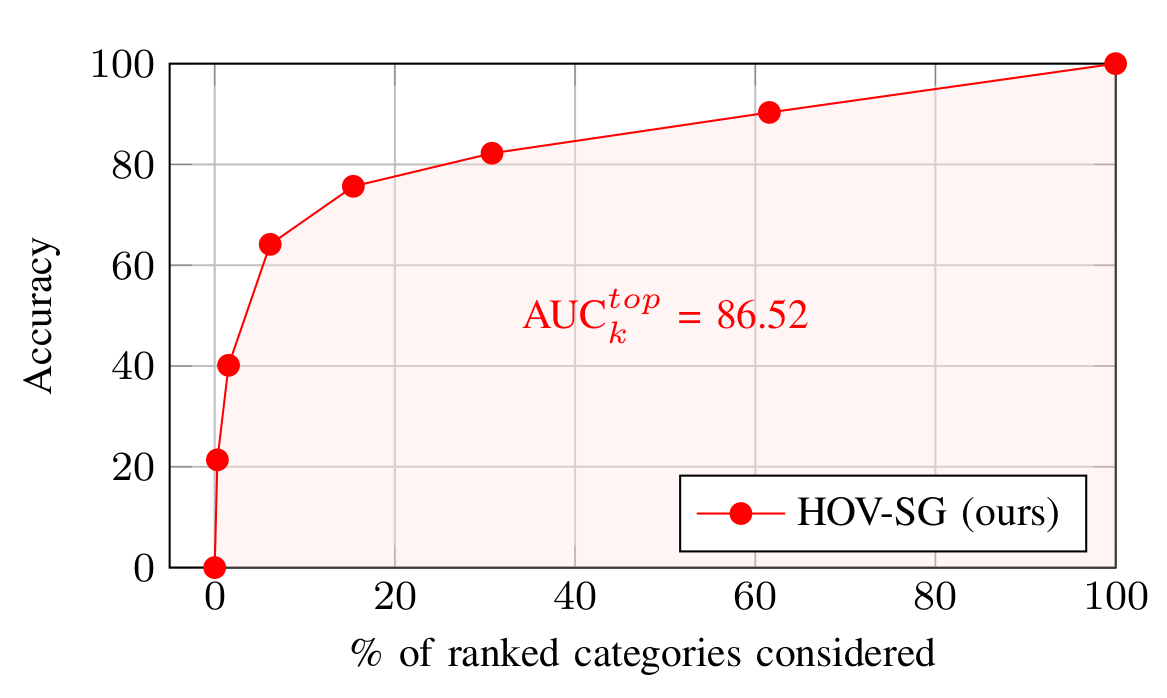
- groundtruth: 一般指机器学习样本中的真实数据
Open Scene Graphs for Open-World Object-Goal Navigation
来自 IJRR 2025 / ICRA 2024
本文引入了 OSG Navigator, 一种开放语义的面向对象, 有较强泛化能力的导航模型
鉴于这是一篇很新的工作, 其泛化能力也超越了以上的文章, 上文的分层模型虽然做到了层次结构的语义地图, 但过于依赖人为规定好的结构, 本文通过 LLM 等模型提供更强的结构模板, 增强对不同环境的适应能力, 此外结构上 OSG 使用模块化设计, 完全用 LLM 这样的基础模型组成
略过相关工作部分, 开始概述这个系统:
- 之前的工作(ObjectNav,2022)输入为 rgbd 信息与无噪声的定位, 而输出是速度命令
- 在 1. 的基础上, 本系统拓展到了开放世界, zero-shot 任务, 面向现实考虑, 输入只限于 RGB, 输出则是线/角速度, 而代理部分接受自然语言的开放词汇表查询
- 本文将上述定义的任务视为一个物体和地点中心的 POMDP(
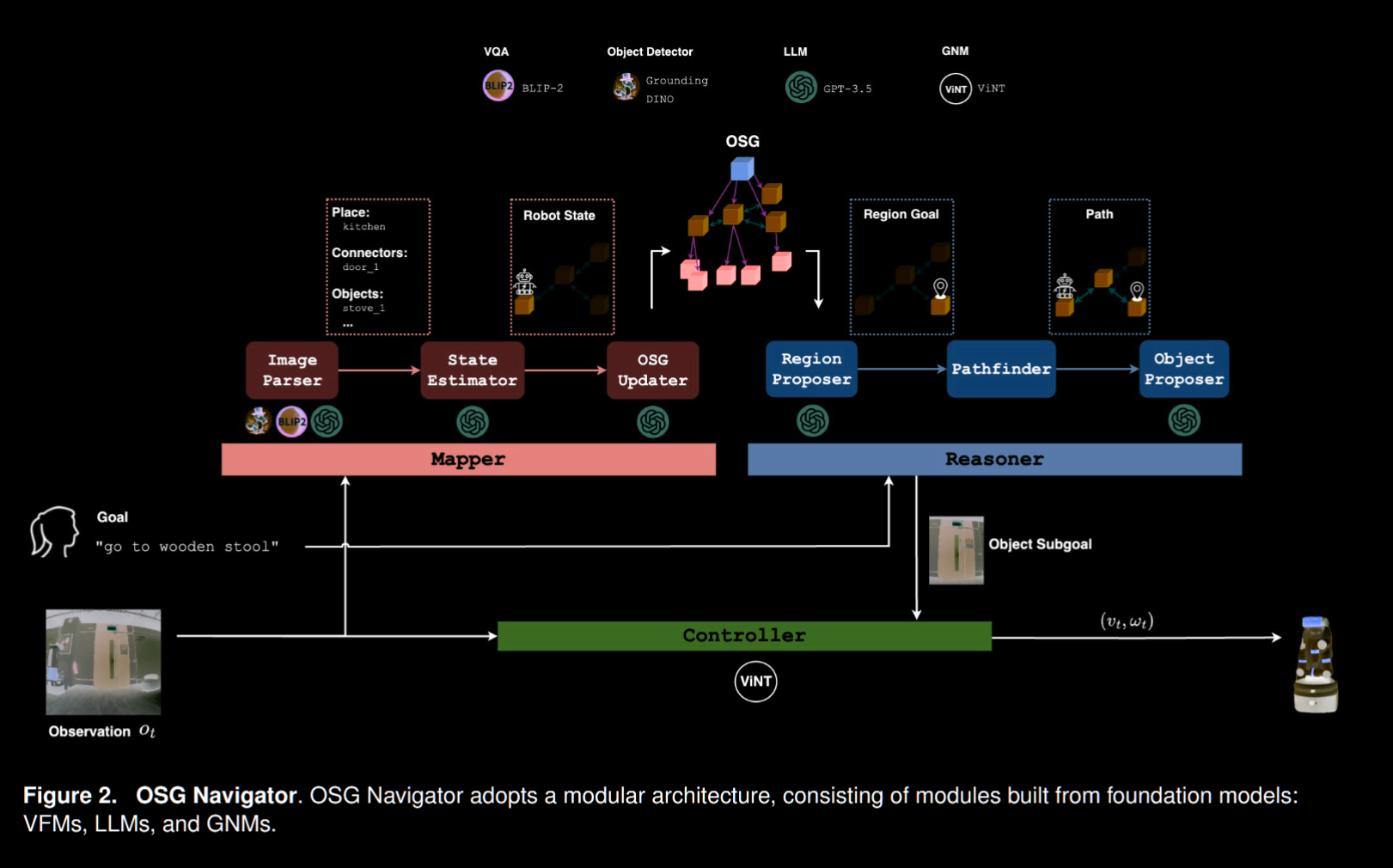
Partially Observable Monte Carlo Planning 部分可观察马尔可夫决策过程) 对此定义以下符号 $ s_a , s_r , s_o, s_e, o, r, , O , $ 分别是: 代理状态, 空间地点状态, 物体状态, 物体/地点的关系(edge), MOVETOOBJECT(动作), MOVETOREGION(动作), 过渡, 观察, 目标(开放词汇的描述) - 具体的模块分为: LLMs, GNMs(General Navigation Model 提供对不同机器人的泛化导航能力), VFMs(视觉基础模型, 即有完成通用性视觉任务能力的模型) for Visual Question Answering (VQA 视觉问答模型) , VF for Open-set Object Detection
- 任务流程上: 开放场景图作为基础, 被高层模块调用进行推理, 产生图像子目标来指导底层导航模块, 细节上, 映射器会从图像中提取出描写其中突出物体的文本, 这些描述数据送给 LLM 用于更新场景图, 推理器则使用 LLM 从场景图中提取子目标并规划路径, 所谓的路径其实是一个图像目标序列, 也就是说其路径点就是图像的经过裁剪的部分(即图像中的某个物体), 由于这些裁剪的物体是中间路径上的, 导航区能使用这些子目标具体地产生动作指令, 同时在导航过程中会动态更新场景与导航计划
场景图
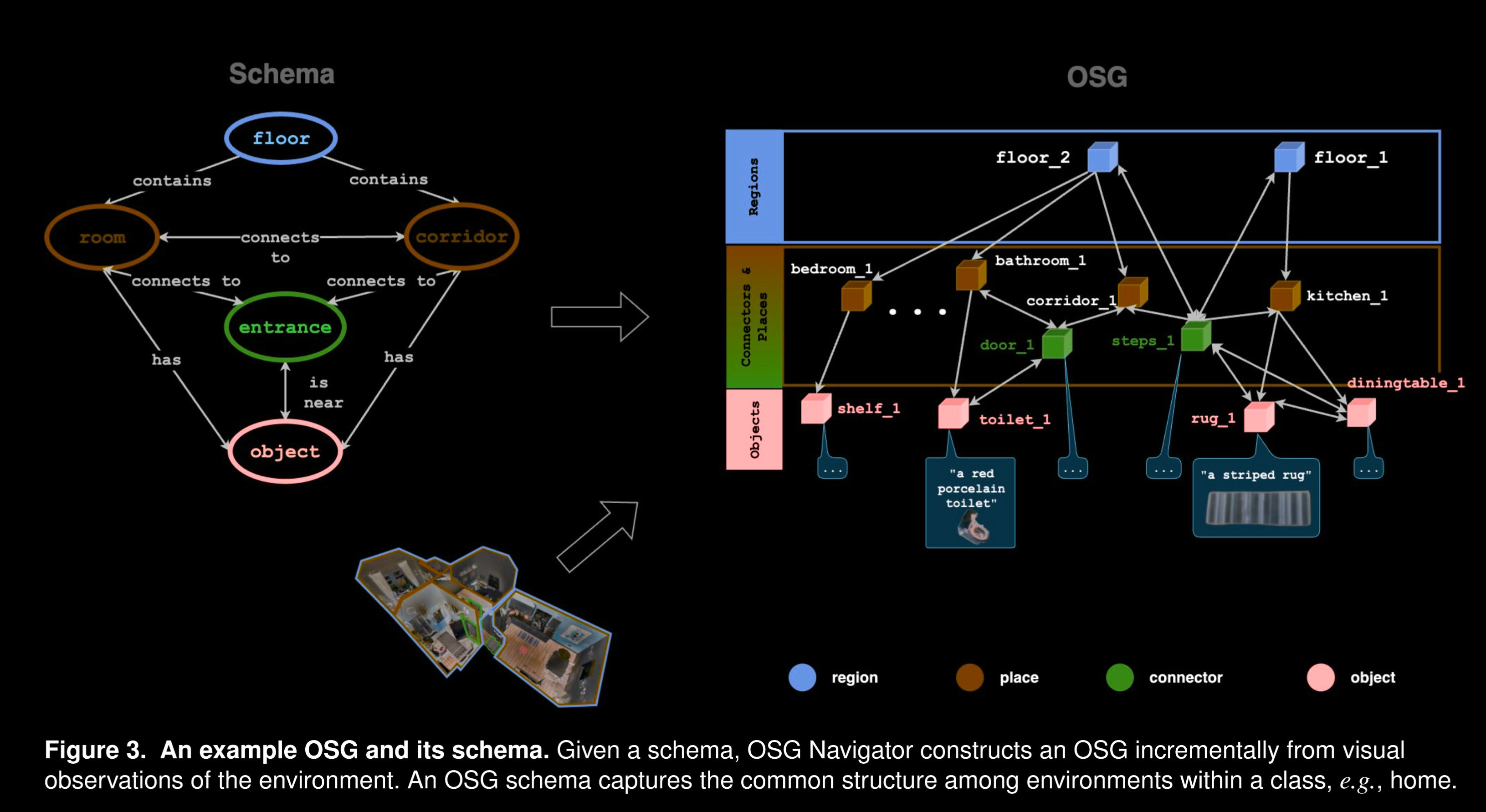
其场景图大体上可以表示为以下的类似 yaml 的形式, 比起只有楼层、房间、物体三级的分层图以及没有分层关系只有物体间关系的双重图都有着更强的抽象能力
可以看到, 其并非是隐变量而是显式的文字描述, 这就意味着也可以根据经验提供一些预设语义, 本文中使用 LLM 来生成
下面介绍细节
1 |
|
- 节点定义: 可分为 4 个抽象类, 除了 Objects 外其他 3 种都可以视为地点(location)类:
- Objects: 占据局部空间的对象
- Places(地点): 较为细粒度的空间, 例如对民居来说可以是房间和走廊
- Connectors: 连接相邻空间的局部元素, 同时有物体和地点属性, 例如大门, 在语义上可以作为路径点或者探索边界
- Region(区域): 比较粗粒度的空间, 可以包含很多局部地点, 例如楼层
- 有向边定义, 也可以分为 4 类:
- Proximity: 空间上的近邻关系, 端点是物体或者连接体, 可用来构建上下文关系
- Connectivity: 即可达性关系, 端点可以是任意节点,
- Inclusion: location 和 object 的单向关系, 表示地点内存在物体
- Hierarchy: region/place-region/place 的关系, 捕获层级关系, 源节点必须是区域节点, 且目标节点必须是树中下一个较低级别的位置节点(region/place)
- OSG 层次定义, 以下是自底向上的顺序:
- Objects Layer: 存放独立的物体, 以及它们之间的关系,
- 每个其中的节点保存四个属性:
- 开放词汇标签, 一般就是物体的名字 \(\mathcal{v}_{label}^o\)
- 对物体外观的开放词汇文本描述, \(\mathcal{v}_{desc}^o\)
- 独特的节点 id, \(\mathcal{v}_{id}^o\)
- 图片剪切, \(\mathcal{v}_{img}^o\)
- 除了属性以外, 还会存储
is near边组成的数组, 例如对有 k 个近邻的节点形如 \([(v_{l a b e l}^{o},\ \ v_{d e s c}^{\mathcal{o}})_{0},\ \ ...,\ (v_{l a b e l}^{\mathcal{o}},\ \ v_{d e s c}^{o})_{k-1}]\), 这个数组可以作为用于区分 object 的特征
- 每个其中的节点保存四个属性:
- Places and Connectors Layer: 捕获细粒度的空间位置信息, 并描述场景中位置之间的连通性, 在导航期间, 机器人的状态被指定为该层的位置节
- 每个
Place节点 \(v^p\) 有三个属性:- 类别信息, \(\mathcal{v}_{cls}^p\) , 来自 OSG 架构, 形式是字符串
- 对地点(place)的开放词汇文本标签, \(\mathcal{v}_{label}^p\)
- 独特的节点 id , \(\mathcal{v}_{id}^p\)
Place节点的边集包括:connects to边(下文也称连接边)指向Place/Connector, 表示联通关系contains边(下文也称包含边)指向Place内的物体, 即 Place 的特征可表示为它contains的物体的特征(标签和描述)集
Connectors节点不同于地点节点的是没有包含边指向物体节点(或者说它自己就是物体节点), 但是可以通过连接边指向其他地点
- 每个
- Region Abstract Layer(可选): 更加通用的抽象空间划分, 例如对多层的住房场景可以是不同楼层, 从这层开始, 对高层对低层只用
包含边, 但是可以被低层的连接体用连接边指向, 详情可见下图- 属性只有 \(\mathcal{v}_{label}^i\) , \(\mathcal{v}_{id}^i\) , 含义类似上文其他节点
- Objects Layer: 存放独立的物体, 以及它们之间的关系,
地图生成和定位
 Mapper 职能如上图所示, 接下来分组件介绍其生成和更新 OSG 的方式
Mapper 职能如上图所示, 接下来分组件介绍其生成和更新 OSG 的方式
自动生成 OSG
为了泛化能力, 本模型的环境图结构也由模型来自动生成, 输入一个环境的简单描述, 生成器就会产生一个 OSG 架构
具体地说, OSG 以 json 的形式被生成, 过程分为三个 Pipeline
- 描述生成: 让 llm 生成无结构, 尽可能长, 包含典型空间抽象关系的自然语言描述
- 规范化(Canonicalise): 让 LLM 将上一步的描述转化为规范图表示, 此外这一步会让 LLM 将节点和边定义为上面提到的类型, 形式上类似于
[Abstraction1, Relation, Abstraction2] - 验证: 根据 OSG 的结构要求检查规范图, 通过一个测试类检验其结构是否满足上一节定义的 OSG, 如果不满足, 将检测到的错误添加到 1. 中的文字描述, 并让 LLM 修正生成的图, 循环直到满足条件, 将其以 json 格式返回
图像解析 Image Parser
使用 VFMs 解析视觉输入, 开放集的物体检测模型来区分标记场景元素, 以及一个 VQA 把图像观察翻译为密集的语言描述(对于 Places, Objects Connectors), 过程为:
- 解析地点: 将机器人周边的 RGB 图像输入 VQA
- 首先提问哪种地点能最好地描述观察帧
- 得到类别后, 继续提问从而获得一个更详细的标签来反映这个地点的语义信息
- 物体/连接体解析: 探测器是区分不出本文自己定义出的两类物体的, 但可以得到基于自然语言的物体信息, 将这些信息输入 LLM 进行分类, 然后让 VQA 模型产生对其图像裁剪的描述, 使用
is near边连接两个体积盒距离低于门槛值的一对节点 - 目标探测: 使用 VQA 或者 LLM 处理上面得到的数据, 如果有和目标很相似的物体, 则直接让代理导航过去
状态评估
 输入上一步得到的文本描述与已有的 OSG, 输出目前的机器人状态即占据的 Place 节点
输入上一步得到的文本描述与已有的 OSG, 输出目前的机器人状态即占据的 Place 节点
流程如上图所示, 其中(P, O, C)指 Places, Objects, Connectors 三种对象, LLM 第一次用于提取一些候选 Place, 这些候选对象根据和上一个 s 的距离被贪心地匹配, 匹配过程中由 LLM 根据两者的描述等信息决定是否匹配成功(优先考虑较大的物体)
OSG 更新
将来自图像解析器的观察结果递增地集成到 OSG 中, 这部分的难点主要在于门槛的设定, 即更新和新建的选择, 在本文定义的 OSG 还有个问题就是节点间关系的选取
这些问题需要近似人类的 "常识", 因此使用强大的 LLM 来处理, 见下图

这部分伪代码比较抽象, 这里简单总结一下:
- 上一步中得到了预估的状态, 于是有两种可能
- 新状态之前没有见过:
- 先将其添加进地点集合, 并增加边关系(依靠 LLM)
- 对 region 层及以上遍历 layer:
- 贪心地让 LLM 推断是否是已有 region 还是不存在, 如果是后者则新建节点
- 新状态之前见过
- 获取新状态对应的叶节点
- 对本轮观察识别到的物体和连接体, 让 LLM 匹配是否也见过, 如果没见过就新建节点, 否则根据 LLM 输出来更新边关系
- 获取新状态对应的叶节点
- 新状态之前没有见过:
基于概率的 OSG
基于 Online Probabilistic Topological Mapping (OPTM 2011), 也就是基于概率的拓扑图
简单地说, 这种方法基于当前的拓扑以及观察来预测之后的拓扑结构, 每个观察都会被连接到一个节点(新建或已有节点), 即计算 \(p({\mathcal{T}}_{t}|{\mathcal{T}}_{t-1}{)}\) 其中 T 表示拓扑图结构, 对本文来说就是 Place & Connectors 层
每一轮中, 实际上做的就是将新的观察链接到新建或者已有节点, 对此有两种可能比较启发性的设置:
- 新的观察 \(o_t\) 倾向于关联到频繁访问的节点
- 新的观察倾向于关联到最近访问的节点
换句话说就是时空局部性原理
对于前者, 使用狄利克雷过程来建模, 对于后者使用对附近节点的均匀分布建模
本模型中可以这样设置:
重要性权值更新方法设置为:
\[w_{t}^{(i)}\propto\mathcal{P}(o_{t}|\mathcal{T}_{t}^{(i)})w_{t-1}^{(i)},\,\mathrm{for \space i \space th \space particle}\]
令 \(v'\) 为当前( \(o_t\) )所属的节点, V 为语义上类似 \(o_t\) 地点的拓扑图节点, 将模型定义为:
\[p(o_{t}|T_{t}^{(i)})=p(o_{t}|v^{\prime})\prod_{v_{i}\in\mathcal{V}\backslash\{v^{\prime}\}}(1-p(o_{t}|v_{i}))\]
这个定义可以视为一种贪心策略, 也就是假设对每对匹配的观察 o 和节点 v, o 最有可能是由 v 处观察的, 是出自其他节点的概率则更低
推理和控制
推理


推理器接受当前 OSG 状态, 目标区域(由区域提议组件生成)以及目标物体, 输出最有可能的子目标, 由 3 个组件组成:
- 区域提议: 对每一层询问 LLM 识别最有希望的节点, 遍历每一层的过程中, 将候选地点标注为子目标区域
- 寻路: 从 OSG 中提取 Places 和 Connectors 的连通性子图, 使用迪杰斯特拉规划从当前位置到子目标节点路径
- 物体提议: 到达子目标后, 查询 LLM 选择其中可能接近目标的对象; 此外, 去子目标的路上也会不断寻找候选子目标, 这是因为机器人大多在地层水使用物体为导航的单位, 该组件用于不断生成
MOVETOOBJECT行动
控制
这是一个底层的目标, 用于不断前进到下一个目标(有点像 rts 游戏里控制单位前进), 具体说就是将 RGB 输入和目标(图像剪切)映射为速度命令, 推理器会不断发送图像剪切目标, 而且都会在机器人传感器能看到的附近位置
本文使用 ViNT GNM 实现
实验与总结
略过一些细节, 本文 OSG 的优点在于, 详细的语义信息如区域划分、连接体等为推理和探索提供了充足的线索
此外 LLM 为 OSGN 提供了强大的开放词汇能力, 对数据集上没有的物体类别也有足够的辨别能力 OSGN 目前在成熟的 LLM, VQA 等模型上取得了很好的成绩, 但主要问题在于, 它使用的是 GPT3.5 这样的成熟大模型, 如果想在不联网的机器人上部署接近性能的语言模型想想就不可能
此外 LLM 也存在局限, 例如对语料库稀少的场景如医院等准确性就会下降, 另一个缺点是由于这些都是基础模型, 除了人为指导或者优化基础模型性能, 几乎没什么改进的办法
stage 1 summary
总结一下目前读过的四种语义地图:
- 概念图(ICRA 2024) : 使用类别无关的分割模型切割对象, 用点云表示空间占用, 对 merge 操作使用 clip 计算一个中间值特征, 但最后存储的是 LLM 生成的描述信息, 由于是早期工作比较粗糙
- 分层图(RSS 2024): 核心想法是构建一个
floor-room-object三层的场景树, 这其中有很多 trick, 这里略过大部分细节, 实际的空间存储是优化(合并)过的点云, 语义存储是每个点云有一个特征向量以及基于封闭词汇的标签, 以占用来说是可控的, 但由于是逐点计算, 我猜想计算量应该偏大, 此外这篇文章虽然确实是开放词汇表, 但其实建图和更新过程中使用了很多封闭词汇表的分类 - DualMap(预印): 以上两个模型都不涉及对地图的动态更新, dualmap 与其区别在于使用两种地图用于节省空间和计算量, 并动态更新地图, 更新过程避免昂贵的 3d 物体合并, 这种双图设计在节省开销方面不错, 但其更新方式比较粗糙, 只是单纯地取平均
- 开放场景图(IJRR 2025): 这是一个神奇的模型, 其输入是 rgb 没有 d, 也没有里程计, 其机器人的导航实现是一个个
move_to_object中间数据都是显性的自然语言信息, 几乎全部的工作是云端 LLM 做的, 虽然有更新算法, 但更新上也是通过 LLM 生成 json 格式的数据来更新拓扑图结构, 这其实可以视作马尔科夫链, 但是使用 LLM 来更新 - 总结: 受限与现实场景规模和成本, 当前语义地图的语义存储主要是对每个对象存储文字描述或者单个特征向量, 更新上其实很难处理, 因为很难找到合适的对先后观察的权重分配, 这点可能还需要继续搜集一些模型
语义级别:
| ConceptMap | HOVSG(分层图) |
DualMap | OSGN(开放场景图) |
|---|---|---|---|
| 物体级别的单图 | 三层的树状空间关系图 | 物体级别的双图 | 层级关系的有向图 |
空间(占用)图表示:
| ConceptMap | HOVSG(分层图) |
DualMap | OSGN(开放场景图) |
|---|---|---|---|
| 点云(降采样处理) | 点云(有一定压缩) | 点云(但导航时只用到锚点对象的点云) | 无(只存储抽象对象, 无距离表示) |
语义形式:
| ConceptMap | HOVSG(分层图) |
DualMap | OSGN(开放场景图) |
|---|---|---|---|
| 描述和标签信息 | 特征向量 | 特征向量 | 描述和标签信息 |
使用的基础模型:
| ConceptMap | HOVSG(分层图) |
DualMap | OSGN(开放场景图) |
|---|---|---|---|
| SAM, Clip, LLM | SAM, Clip, LLM | SAM, YOLO, Clip | GNM,, LLM |
导航(子目标选取)算法:
| ConceptMap | HOVSG(分层图) |
DualMap | OSGN(开放场景图) |
|---|---|---|---|
| LLM 生成 | LLM 分解任务再用余弦相似度选取目标 | 余弦相似度选取候选 | LLM 生成 |
Map-SemNav: Advancing Zero-Shot Continuous Vision-and-Language Navigation through Visual Semantics and Map Integration
来自 ICRA 2025
这是一个 VLN 模型, 用于不使用大模型的 zero-shot 任务
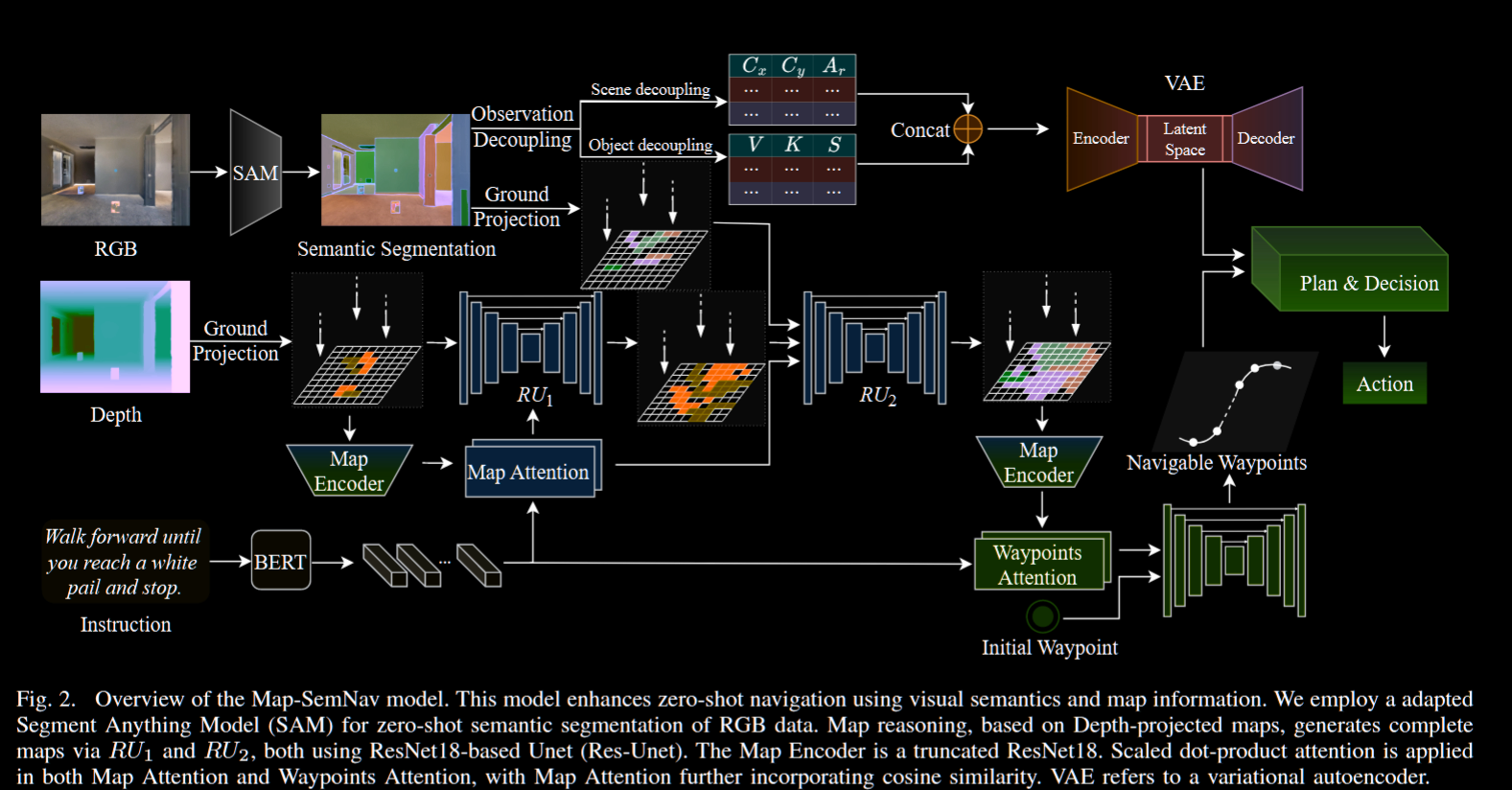
对零训练任务来说, 最大的问题就是泛化问题, 很多使用大模型的文章就是通过大模型解决该问题, 而本模型使用 rl 的思路, 将问题视为在可见和隐藏变量的环境中寻找一个最优策略 π
建图
模型的输入为 RGBD 观察帧, 将其用于生成一个自上而下的自我中心(网格 \({\phi}_t\) )地图, 使用 ResNet18 从网格提取特征, 得到一个特征表示 $ R_t^{} $ 对输入的查询指令使用 BERT 进行编码得到特征 \(\Lambda\)
然后使用如下的注意力机制:
\[Q=R_{t}^{\phi}W_{q},K=\Lambda W_{k},V=\Lambda W_{v}\]
\[\Psi_{t}^{\phi}=S o f t m a x\left(\frac{Q K^{T}}{\sqrt{d}}\right)V\]
综合得分表示为指令地图特征的综合相似度(标准化)和注意力得分的加权和
\[\displaystyle{\mathcal G}_{t}=\frac{(W_{R}R_{t}^{\phi})(W_{\Lambda}\Lambda)^{T}}{\|(W_{R}R_{t}^{\phi})\|\cdot\|(W_{\Lambda}\Lambda)\|^{T}}\]
\[{\tilde {\mathcal{G}}}_{t}={\frac{ {\mathcal{G}}_{t}+1}{2}}\]
\[\Gamma_{t}^{\phi}=\left(\lambda_{1}S o f t m a x\left(\frac{Q K^{T}}{\sqrt{d}}\right) +\lambda_{2}\tilde{\mathcal{G}}_{t}\right)V=\lambda_{1}\Psi_{t}^{\phi}+\lambda_{2}\tilde{\mathcal{G}}_{t}V\]
为了推导代理看不到的部分环境, 使用双重残差网络, 即:
\[\hat{\phi}_{t}=R U_{1}(\phi_{t},\Gamma_{t}^{\phi}),~~~\hat{\Upsilon}_{t}=R U_{2}(\hat{\phi}_{t},\Gamma_{t}^{\phi},\hat{\Theta}_{t})\]
其中 θ 为从 rgb 帧中进行的语义分割片段(带类别信息)后的地面投影, γ 是用于推理的语义地图
场景/对象解耦(decoupling)
这一步主要目的为去除噪声或者不重要的信息, 提取关键信息, 也是本文的主要创新点, 其最大的优点在于, 让对物体的语义表示摆脱对类别等已知信息的依赖, 从而增加泛化能力
- 场景解耦: 提取主要的布局信息, 场景在模型中表示为一个物体空间的信息集合, 但单个物体的信息表示为质心的 xy 坐标加上其面积占视图的比率, 对大量被分为同类的物体, 在导航时面积更大的会有更高的优先级
- 物体解耦: 使用通用性的表示方法来表示物体, 具体对每个物体来说, 存储以下数据:
- V: 可见性, bool 值
- K: 是否为里程碑, 即指令中包含的关键对象, bool 值
- S: 对象的语义嵌入和里程碑的语义嵌入之间的加权平均余弦相似度, 参考之前的 \({\tilde {\mathcal{G}}}_{t}\) ; 已经抵达的里程碑权值为 0, 未抵达的里程碑权值递增
对之前提及的解耦信息, 它们的存储形式为附加在网格上的矩阵, 对其进行 concat 形成一个观察解耦矩阵, 并输入一个 VAE, 这里不使用 VAE 的解码功能, 只使用 VAE 的潜空间来捕捉空间结构关系
推理与控制
在推理和导航过程中, 类似之前的过程计算自我中心地图的注意力表示, 然后将其输入一个 Res-Unet 来得到可以导航的路径点 w(ay)p(oints)
这些 wp 与此前的解耦矩阵是推理模块的输入, 这个过程中会使用 DD-PPO 来产生动作指令(底层上只有移动和转向)
Multimodal Data Storage and Retrieval for Embodied AI: A Survey
这是一篇关于具身智能领域关于数据存储检索方式的综述, 前面比较水就跳过了, 主要讲的是各种领域应用的 em-ai 对数据系统的需求
数据存储
总的来说, 具身智能领域需要的数据是多模态且能实时快速检索到的, 数据存储有五种常用范式:
- 图数据库 Graph Databases: 直接通过节点和边来建模复杂的关系, 其最大的优势是可以与全局数据大小无关的复杂度查询周边节点, 也就是上下文信息, 但是同样的, 对可能变化的环境, 更新图状的知识库以及确保一致性也会非常艰难, 同样的, 在图中嵌入多模态知识也很难实现
- 多模型数据库 Multi-model Databases: 在单一平台上原生支持关系型、文档型、图等多种数据模型, 对此有两种思路, 1 是依旧用不同架构的数据库, 再加一层抽象来统一调用, 2 是搞一个大一统数据库, 可以存各种数据进去; 这样听起来很好, 但实际表现上开销大(包括数据转化, 检索等)是不可避免的问题, 对要求实时性的 eai 来说不实用
- 数据湖 Data Lakes: 采用只读架构保留原始数据, 也就是说基本上只是保留数据并提供高效检索, 而不对数据进行处理, 难以维护上下文之类的语义信息, 对于实时性活动性的 agent, 则用处有限
- 向量数据库 Vector Databases: 针对高维向量相似性搜索进行优化索引; 由于目前的 eai 经常用 clip 之类的模型产生嵌入向量作为语义表示, 提供高效的近似向量检索是一种非常使用的功能, 对于算力受限的情况, 可以使用带有近似最近邻检索的数据系统
- 时序数据库 Time-Series Databases: 针对大量传感器数据流提供高效的写入和查询能力: 对于 eai 常见的传感器数据来说实用性较好, 问题在于, 对多模态数据的支持受限
数据检索
接下来讨论对(多模态数据的)检索, 也可以分为 5 种范式:
- Fusion Strategy-Based Retrieval: 将多模态特征整合到一起, 与 2. 的区别是会保留对不同模态的描述信息、权值信息等, 也就是对多模态数据有一个共享的语义空间, 以及其各自的私有信息, 这样的好处上信息完整性高, 缺点则是难以保持一致性, 实时性, 成本较大
- Representation Alignment-Based Retrieval: 将多模态数据嵌入到一个统一的语义空间, 随后根据相似度检索; 这个方法的挑战是多模态之间的对齐, 但是有 clip 这样非常强大的基础模型, 应用上相对成熟
- Graph-Structure-Based Retrieval: 使用图学习来捕获数据实体以及其相互关系, 其优缺点和之前的图存储类似, 具体可分为:
- 图嵌入: 将给定图所有节点嵌入语义空间中
- 图索引: 对有语义信息的图, 实现索引优化
- 图匹配: 量化查询语句和目标子图的语义一致性, 从而检索子图中的对象
- Generation Model-Based Retrieval: 利用生成模型将搜索任务转化为文本生成问题, 即利用已有的跨模态数据或者其中间表示, 从而直接生成检索需要的信息, 同时可以用 rag 等方法调用外部知识来减少幻觉; 其缺点是, 幻觉或者大型模型预训练知识与 eai 训练中的知识不同的倾向性可能影响准确性
- Efficient Retrieval-Based Optimization: 使用近似最近邻算法这种高效算法或者硬件加速技术来实现高效检索
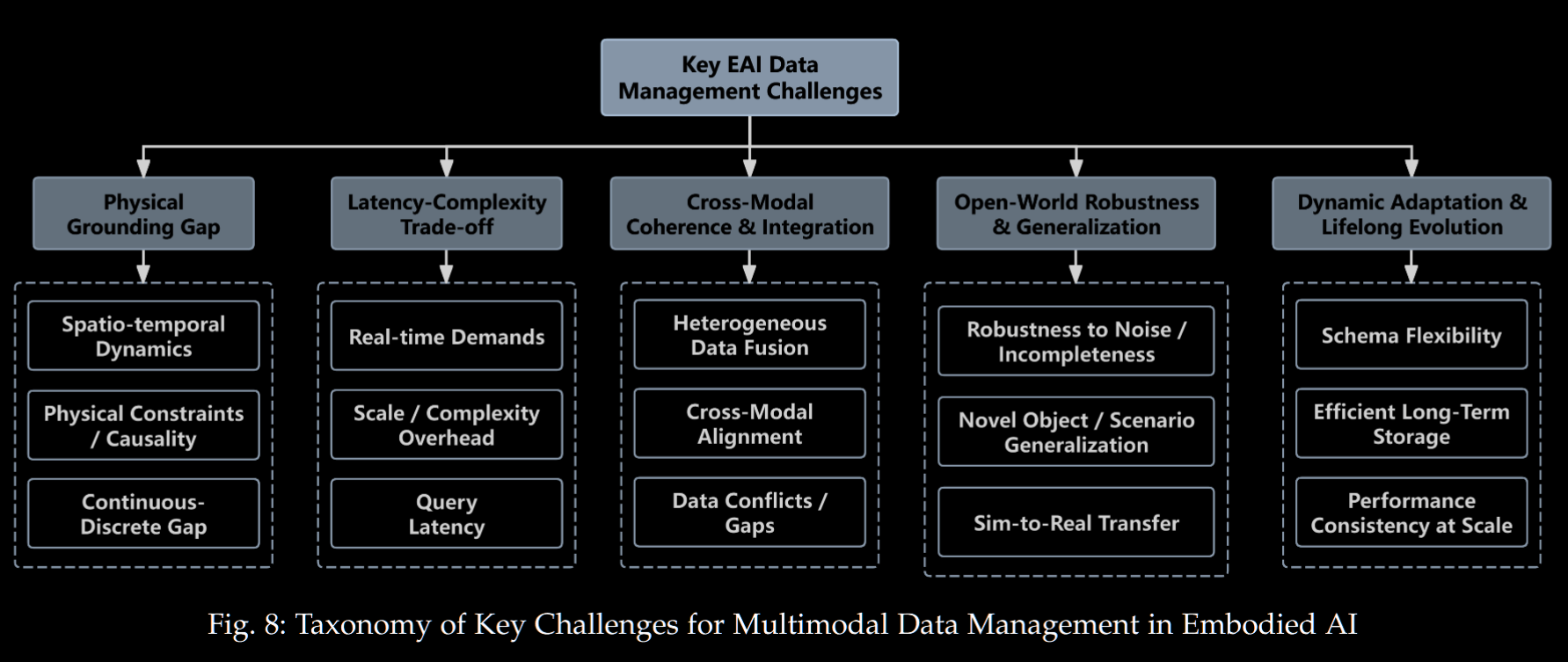
eai 数据管理的挑战
eai 的数据需求需要多模态、高速检索、尽可能准确、计算消耗低、高保真、动态环境中的稳定性以及更新成本可控
满足其中的一两项都很难, 更不用说综合考虑了, 本文对其的总结见下图
Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
TKDE 2024
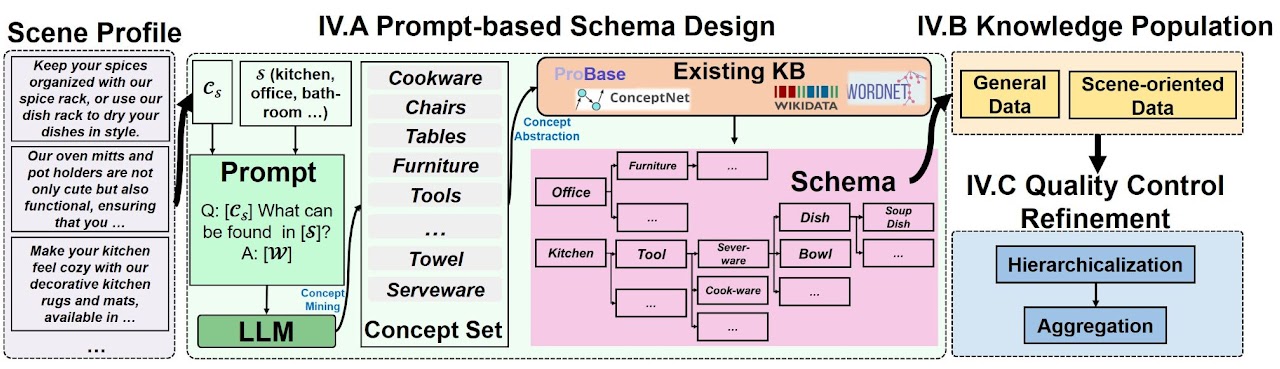
与之前的模型不同的是, 这是一篇数据库刊物上的文章, 也就是说, 会使用知识增强方法
从数据的角度对具身智能能学习到的知识分类, 可分为:
- perceptual knowledge: 感官知识, 也就是能由传感器检测到的知识, 由于依赖传感器输入以及物理设备的算力限制, 传感器数据很难用数据库之类的较为复杂的形式存储, 一般会用 yolo, sam 之类的视觉模型进行处理转为可以被存储的更小的数据
- apperceptive knowledge: 感知知识, 也就是关系性, 描述性的信息, 这些数据通用性强, 可以用知识库来存储, 供机器调用
将现存知识库里得到的知识称为符号(symbotic)知识, 由可学习的模型训练得到的知识称为参数知识(如 gpt), 前者优点在于可靠性强, 但成本高, 后者则相反
本文提出了一种综合性的知识图谱构建方法, 这个知识图谱称为 Scene-driven Multimodal Knowledge Graph (SceneMMKG)
常识中的知识图谱一般是服务于 nlp 之类的任务, 但就具身智能领域而言, 知识图谱只需要存储场景及其物体与机器人交互有关的信息就可以
KG 构建过程
- prompt-based schema: 也就是解决图谱结构的问题, 一般来说可以根据不同领域手动设定, 但在机器人场景下比较难办, 这里使用万能的 LLM 来处理
- 室内场景可以由有限个种类定义, 设场景档案集 Ws 为一系列场景(例如房间种类)的文本描述的集合, 如以下的流程图, 将档案集和一个场景输入 LLM(预训练且不会更新)得到名为 concept 的抽象信息, 形式是文本信息的集合 c
- Concept Expansion: 基于现有的通用 KG, 将之前得到的 c 拓展为原有词汇与其上下位词的并集(例如 color 和 red 互为上下位词)
- Concept Cluster: 简单地说就是去重, 比较每对概念词, 若相似度大于一个门槛值则合并
- Knowledge Population: 也就是知识扩充, 将通用知识库 \(K_g\) 用于构建 \({K}_{\mathrm{scene-KG}}\) (根据现有的通用知识库产生的中间知识库)融入现用的知识图谱(不冲突的前提下), 下面介绍知识来源
- 通用知识来自于已有的知识库, 开始时, 从这些知识库检索, 基于已有的架构, 将检索到的数据逐步挂载, 得到 \({K}_{\mathrm{scene-KG}}\)
- 场景中心的知识 \(K_s\), 这种知识较难获取, 文本领域还有一些数据集, 图像数据则相对稀少
- Quality Control and Refinement: 由于一些属性有复合含义或者不同属性有类似含义, 实际上会出现少部分属性较为集中的情况, 也就是长尾现象, 为此需要进行一些处理
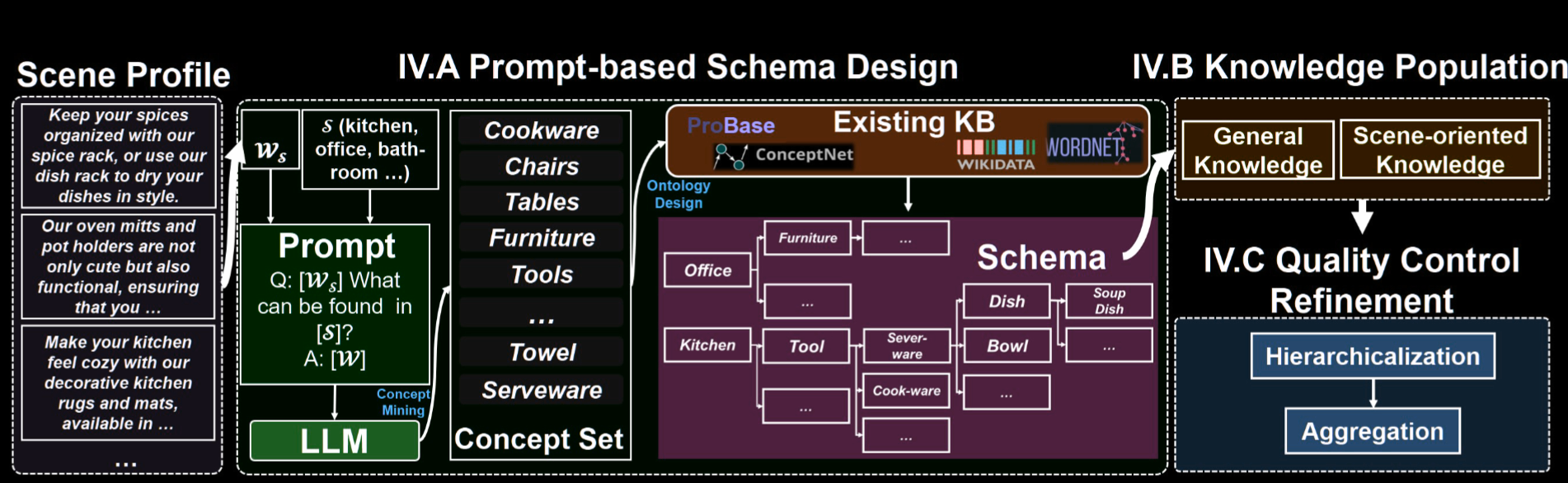
- Hierarchicalization: 如以下的算法所示, 将一个实体的属性集 A 拆开, 即对其属性 a 拆分成部分集合 P 以及通用属性 AP, P 连接到所属实体, AP 的元素 ap 则各自连接到 P 中的元素 p; 这里摘一段原文
a “chair” possesses attributes “frame length” and “foot length”. To manage these attributes effectively, we subdivide the “chair” into its constituent parts, “foot” and “frame”, considering “length” as a general attribute of each part. Attributes that cannot be further subdivided, such as “usage” and “conservation measures”, are directly associated with the “chair” - Aggregation: 使用预训练的语言模型对属性对去重, 达到门槛值则合并, 例如 " measurement” , “size”会被这样合并
- Hierarchicalization: 如以下的算法所示, 将一个实体的属性集 A 拆开, 即对其属性 a 拆分成部分集合 P 以及通用属性 AP, P 连接到所属实体, AP 的元素 ap 则各自连接到 P 中的元素 p; 这里摘一段原文

知识增强
对已有的场景知识, 出于机器人任务需要(即导航或者操纵), 需要更详细的知识, 即 Scene-driven Knowledge Enhancement, 步骤为:
- 知识检索: 这是通过比较查询 mmkg 中实体的相似度选择的, 不断取最佳候选对象, 然后让 SKR(Scene Knowledge Retrieval)模块返回文本与视觉知识 \(H\)
- 多模态降噪: 对检索到的知识, 使用降噪模块优化, 具体则是对每个时间步的观察帧 \(O_t\) 计算与检索到 H 的相似度, 丢弃掉相似度大于一个门槛值的知识
- 知识编码: 详细见以下的流程图, 简单地说就是用 clip 对文本和图像编码, 场景知识则用 n 层 GCN 编码
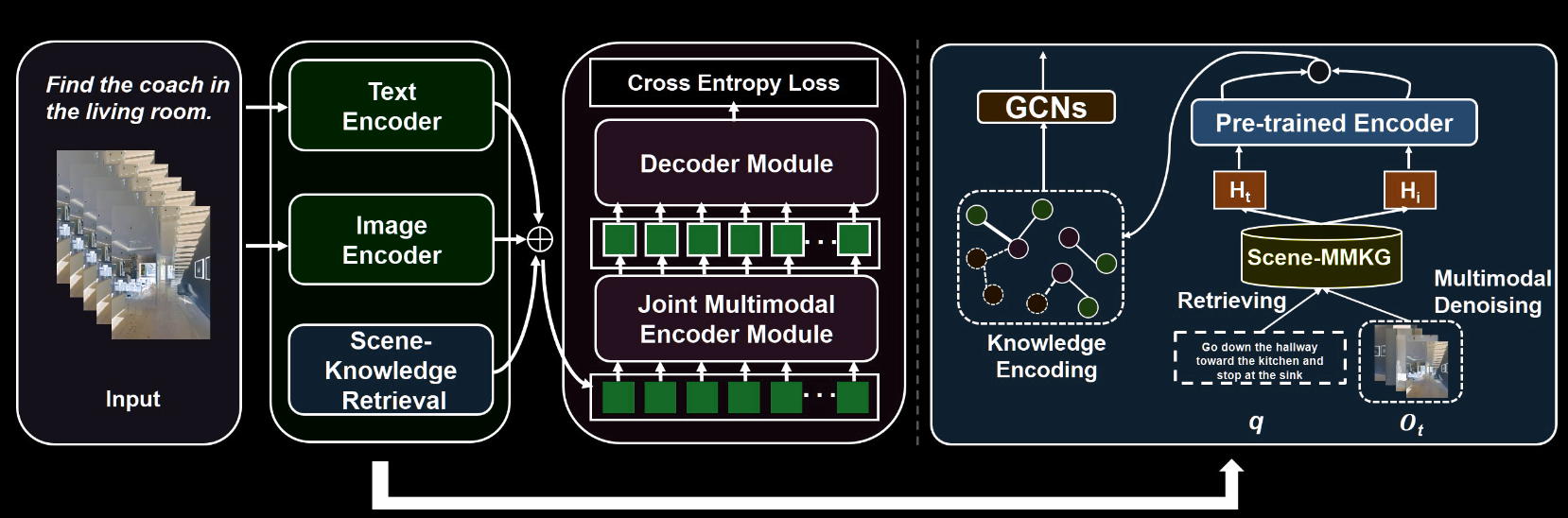
知识注入
即将上一节中得到的知识用于具体任务中
- VLN: 最典型的机器人任务, 对各个时间戳的辨别到的物体使用 R-CNN 编码得到 Fo, 对指令使用 tf encoder 编码为 Fi, 每个时间步的场景知识被编码为 Fh, 也就是我们上一节做的事, 以上这些特征被 concat 为 m, m 作为 token 被输入 tf decoder 来产生隐藏状态 h_t(t 为时间步), 随后可以视为一个(动作)序列生成问题, 使用交叉熵训练
- 3D Object Language Grounding: 指代理根据语言描述辨别现实物体的能力, 是操纵等复杂任务的前置步骤, 其思路和 VLN 也差不多, 将场景、物体、指令特征拼接后用 MLP 计算相似度, 并用交叉熵作为损失函数
Embodied-RAG: General Non-parametric Embodied Memory for Retrieval and Generation
arxiv(cmu)
记忆构建
本模型中的记忆构建是自底向上的, 由两个独立部分组成: 拓扑图和语义森林, 语义森林是分层结构, 会使用部分拓扑图的信息
拓扑图中的每个节点包含信息:
- pose 信息, 即拍照处的姿态信息, 根据代理的历史路径或者距离关联
- 时间戳
- (自我中心的)图像
- 图像描述(由 LLM 生成)
语义森林的概念来自于对具身智能数据的启发式假设: 具身数据在空间和语义上有组织关系, 构建过程:
- 使用 全连接聚类(complete-linkage hierarchical clustering) 对上一步得到的(叶)节点聚类, 但是将两个节点的距离定义如下:
\[S_{i j}=(1-\alpha)S_{i j}^{\mathrm{spatal}}+\alpha S_{i j}^{\mathrm{semanic}}\] \[S_{i j}^{\mathrm{\scriptsize{spatial}}}=\exp\left(-\frac{d_{\mathrm{haversine}}(i,j)}{\theta}\right)\] \[S_{i j}^{\mathrm{semantic}}={\frac{\bf e_{i}\cdot\bf e_j}{||\mathrm{e}_{i}||.||\mathrm{e}_{j}||}}\]
其中 e 表示节点描述的嵌入向量
- 聚类完成后, 对每层的各个聚类用 LLM 产生一个摘要, 摘要会作为一个新节点插入(在聚类的正中), 这样的过程持续到产生根节点或者没有新聚类产生 这其实和 3d 场景图有点像, 但本文出于抽象户外空间的目的考虑, 只用抽象化的机器自生成层级, 而不是人为规定
检索
与构建相反, 检索是自顶向下的, 分为两个阶段
- 语义引导的层级遍历: 并行地遍历语义森林, 即 给定查询 q, 在第 l 层候选节点集 Cl 上, 用基于大模型的选择函数 fLLM 选择 k 个要查找的分支(节点) :Nl = fLLM(q, Cl, k), 不断向下层递归, 直到叶节点, 过程中基于语义相关性进行剪枝, 最后得到的叶节点形成一个集合
- 混合重排序(Hybrid Re-ranking)
- 选出一些候选叶节点后, 用另一个 LLM 评分并降序排行并去重
- 如果有位置信息, 将其也作为前置条件, 以类似构建过程中的空间分数与 1.的语义分数加权和作为排序条件
检索到的节点作为上下文一部分和用户查询一起传递给 LLM, 然后类似一些 VLN 模型, 让 LLM 根据上下文信息寻找候选航路点
总的来说, 目前这个 rag 系统速度上很快, 但可以获得的信息依旧很粗糙, 例如有类似物体的个数这种数据几乎不能构建出来
Context-Aware Graph Inference and Generative Adversarial Imitation Learning for Object-Goal Navigation in Unfamiliar Environment
RAL 2025
本文提出两个主要技术:
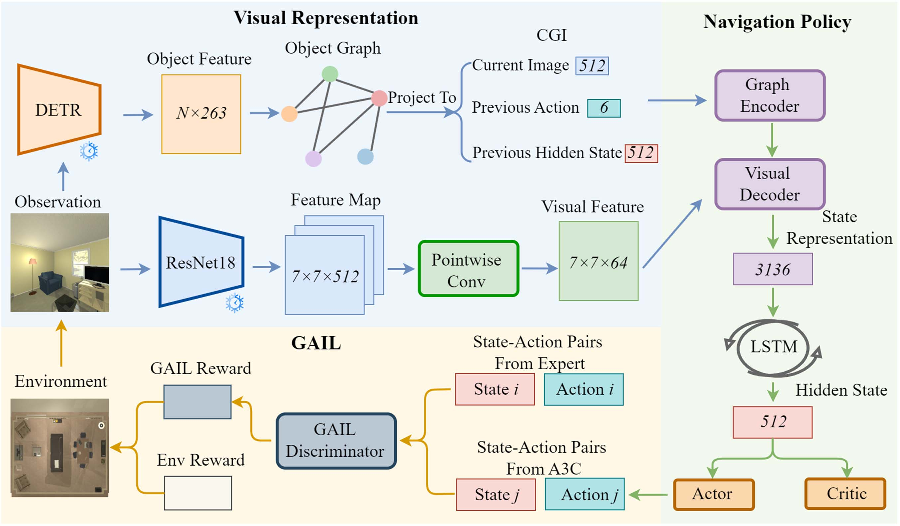
context-aware graph inference (CGI): 学习上下文相关的物体关系, 动态更新, 它使用 TransH(一种知识图嵌入技术)., 将物体嵌入到一个表示空间, 用这个空间统一图像, 动作, 记忆等数据generative adversarial imitation learning (GAIL): 从专家演示中学习动态奖励机制, 与环境奖励结合, 避免模仿学习的固有缺陷(就导航任务来说是容易陷入死锁, 找不到下一个目标点), 并结合asynchronous advantage actor-critic的 rl 方法
CGI
使用 DETR 检测器探测物体, 产生中间特征, 这包括置信度, 碰撞箱, 语义标签, 类别标签等, 将其拼接起来作为节点特征, 并将所有节点做成一个全连接图
我们希望能在导航过程中动态更新节点的上下文关系, 于是使用 TransH 将所有节点转化到一个表示空间中, 这个空间有 3 个维度, 图像、动作、记忆(历史状态):
- 图像维度: 这部分的主要目的是获取物体之间的关系, 对原有的特征集池化得到特征 \(s_t\) , 使用如 \(v_{ {i};s_{t}}\,=\,v_{i}\,-\,w_{s_{t}}^{\top}v_{i}w_{s_{t}}\) 的计算式将物体投影到图像超平面, 其中 w 是用于转化的权值向量, 投影后, 使用如下的计算式计算对每个物体对进行点积注意力与 softmax: \(\alpha_{s}^{t}(i,j)=\mathrm{softmax}\left(\frac{v_{i;s_{t}}\cdot v_{j;s_{t}}^{\top}}{\sqrt{d_{v}}}\right)\) 其中 α 表示物体间边的权重, d 为物体特征的维度数
- 动作维度: 这部分的主要目的是让代理对环境的理解对齐自己的行动(也就是考虑先前行动对环境的影响), \(v_{i;a_{t-1}}=v_{i}-w_{a_{t-1}}^{\top}v_{i}w_{a_{t-1}}\) 其中 a 表示动作超平面中的动作特征, 类似的, 物体间关系定义为: \(\alpha_{a}^{t}(i,j)=\mathrm{softmax}\left(\frac{v_{i;a_{t-1}}\cdot v_{j;a_{t-1}}^{\top}}{ {\sqrt{d_{v}}}}\right)\)
- 记忆维度: 这部分的主要目的是让代理逐渐积累经验, 且理解物体之间的关系, 这里的记忆可以视为 LSTM 的隐藏状态 $m_{t-1} $, 计算式类似上面的维度 \(v_{i;m_{t-1}}=v_{i}-w_{m_{t-1}}^{\top}v_{i}w_{m_{t-1}}\) ; \(\alpha_{m}^{t}(i,j)=\mathrm{softmax}\left(\frac{v_{i;m_{t-1}}\cdot v_{j;m_{t-1}}^{\top}}{\sqrt{d_{v}}}\right)\) ,
得到这三个维度的特征后, 根据先前的隐藏状态 \(m_{t-1}\) (即三个和为 1 的 β 值), 对 α 算加权和: \(\alpha^{t}(i,j)=\beta_{s}^{t}\alpha_{s}^{t}(i,j)+\beta_{a}^{t}\alpha_{a}^{t}(i,j)+\beta_{m}^{t}\alpha_{m}^{t}(i,j)\)
即得到了对象之间的关系
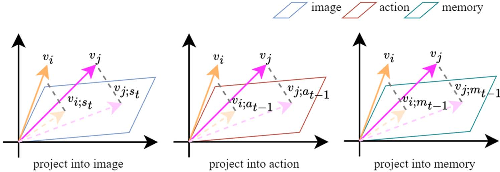
GAT
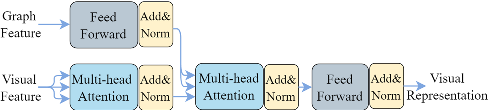
使用一个 graph attention layer (GAT) 对图编码:
\[v_{i}^{(l+1)}=\sigma\left(\sum_{j\in N(i)}\alpha^{t}(i,j)W^{(l)}v_{j}^{(l)}\right)\]
其中 \(v_i^{(l)}\) 代表 l 层节点 i 的特征向量, N 表示邻居, \(\sigma\) 代表 ReLU 激活函数, W 是 l 层的权重矩阵
GAIL
即用一个生成器 G 和分类器 D 对抗, 当 D 无法区分专家数据和生成数据时则训练成功, 让 D 生成一个奖励(也就是当前 s, a 与专家数据的相似度)加权与原有的奖励函数相加
最后的导航使用 A3C 训练
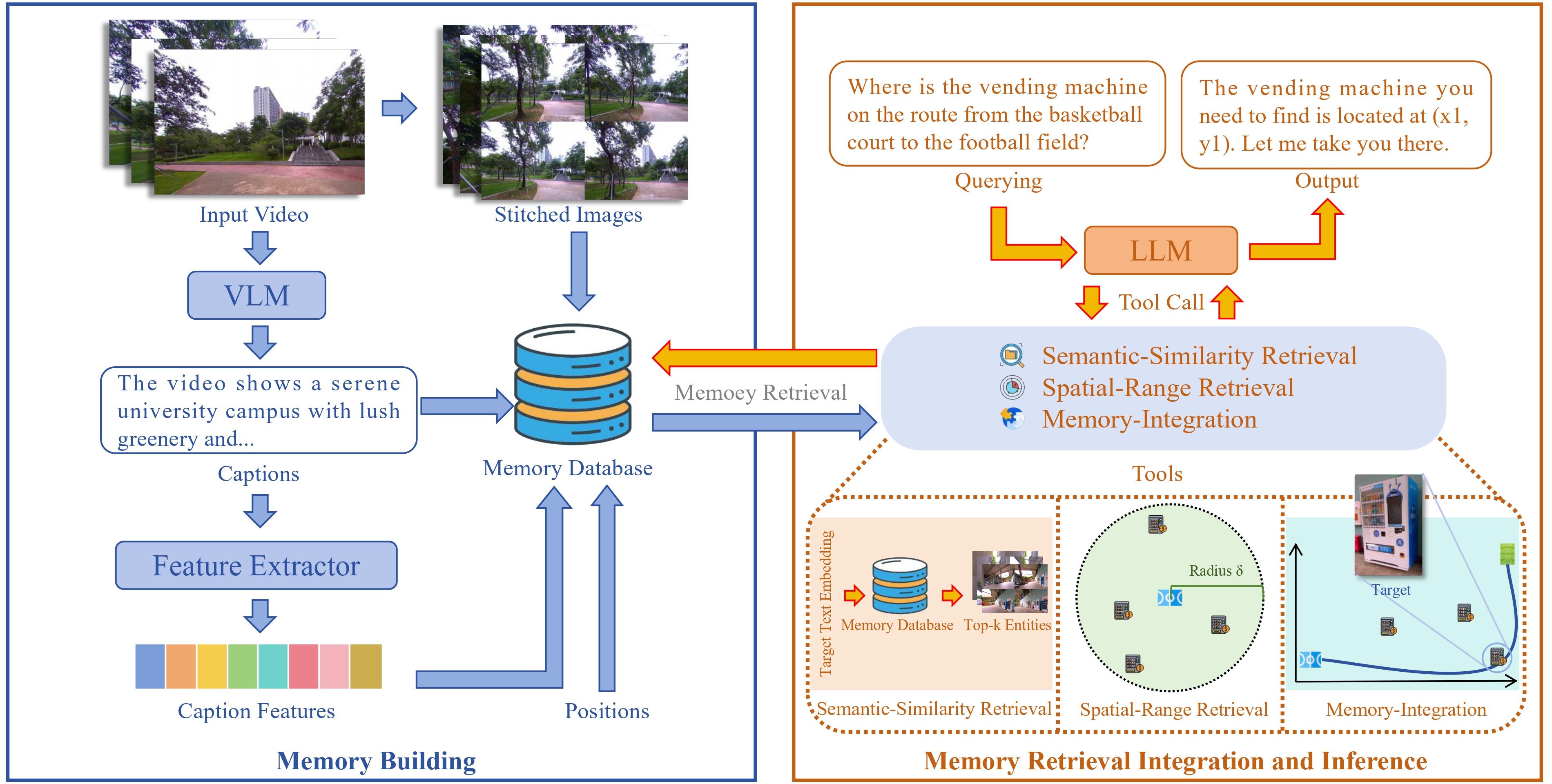
Meta-Memory: Retrieving and Integrating Semantic-Spatial Memories for Robot Spatial Reasoning
arxiv 2025(南科大)
这是一篇使用数据库存储语义信息的文章, 这种架构在 eai 领域比较少见, 因为多了一层与数据库通信的开销, 但相对的, 使用一个空间数据库也会带来更为全面的空间信息存储能力, 这对增强代理的空间理解能力至关重要
记忆构建
与常见的存储描述或者嵌入向量的方法不同, 本文用一个数据库作为机器人的记忆, 这样可以极大增加存储数据的信息量, 具体来说
- 对输入数据(时长为 t 的视频), 用 VLM 产生描述并将描述嵌入为向量
- 以固定的间隔截取一些帧, 拼接为一张大图
- 在数据库中存储描述, 描述嵌入, 拼出的大图, 机器人位置
- 嵌入和位置是向量, 因此可以方便地在之后被检索
记忆检索
给定已经构造好的记忆以及一个空间查询(自然语言的), 根据语义和空间距离查找若干存储条目, 将条目合并为一个统一表示, 即所谓的认知图 cognitive map
与常见的向量相似度匹配不同, 数据库能存储更多数据, 能够根据已有数据优化查询, 可分为语义查询和空间查询
语义查询流程如下:
- 使用 LLM 提取查询目标描述, 将目标描述编码为语义向量
- 以查询语义向量搜索数据库中相似的 top-k 结果
- 用 gpt4o 的视觉功能检验查询与 2. 中结果的图像是否匹配, 生成细化的描述作为上下文给之后的推理
相比之前的向量相似度检索, 这样的流程综合考虑了成本和检索准确度
如果尝试过语义查询的结果后失败, 则进行空间查询, 流程如下:
- 根据目标让 LLM 给出一个检索半径, 并从之前的上下文中选择一个最有希望的位置 pos
- 根据 pos 与半径查找数据库中的对象, 并由 LLM 指定 k 个候选
- 对这些候选, 类似语义查询进行视觉匹配
记忆融合
即根据查找到的记忆构建认知图:
- LLM 从上下文中提取出地标信息, 并得到它们的位置信息
- 数据库中所有实体的位置作为航路点构建拓扑图, 使用迪杰斯特拉算法计算地标之间的最短路径
- 汇总这些信息, 通过规则程序或者生成模型产生认知图
- 将认知图发送给 VLM, VLM 进行细粒度推理, 推理内容也整合到上下文
记忆推理
本文的推理过程类似大部分基于 LLM 的代理, 整个过程就是 LLM 不断调用工具并决定输入输出, 其中除了语义检索外的两个工具是非必须的
ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
icra 2025
这是一篇讨论机器人长期记忆机制的论文, 问题定义为给定传感器历史数据 H, 机器人接受数据并回答问题, 生成导航目标, 传感器数据包括: 图像、位置、时间戳
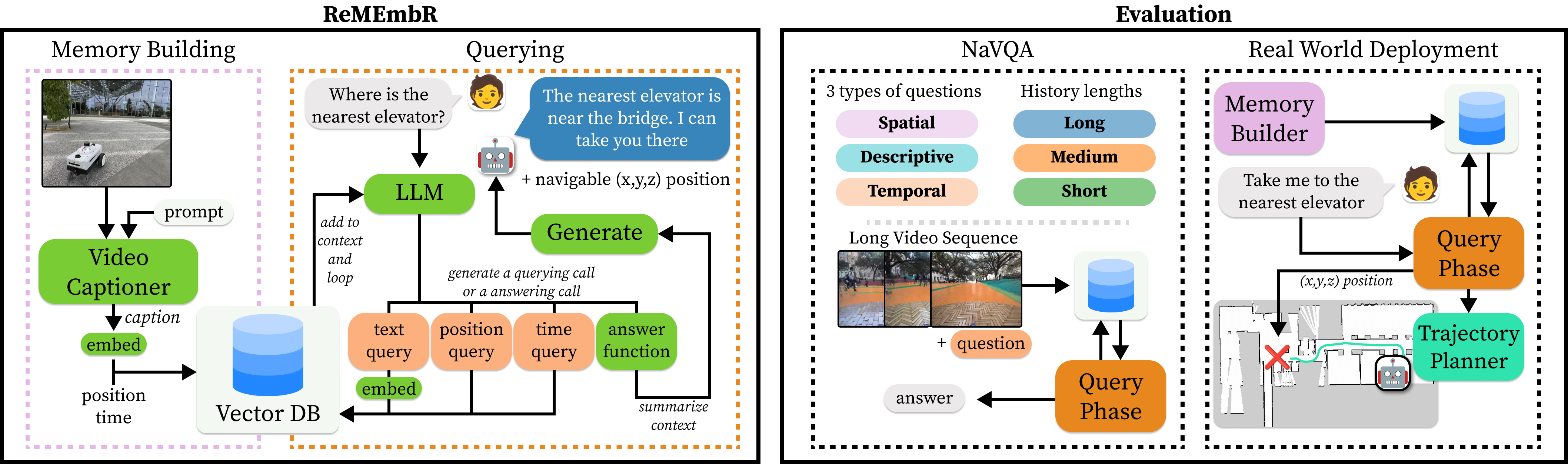
eai 领域最大的难题就是具身智能有限的本地算力, 因此在长期任务中, 每次都输入所有历史数据来产生答案是不现实的, 本文将问题定义出找到一个 H 的子集 R, 让这个子集能产生较好答案的同时尽可能小
将机器人的存储数据定义为 V, 在本文中是一个向量数据库, 将其从中提取 R 的过程定义为 F
对此, 我们聚合 t 秒的图像帧, 用 VILA 产生视频描述, 再嵌入这些描述, 附带位置信息与时间戳
查询时让 LLM 输出需要的记忆窗口, 即上文的 R, 并由 LLM 输出查询语句, 根据查询语句的嵌入匹配需要的图像帧及其时间戳与位置
3D-Mem: 3D Scene Memory for Embodied Exploration and Reasoning
cvpr 2025
这是一篇直接用图像作为语义数据来源的文章, 将多视图图片定义为“内存快照(memory snapshots)”, 直接存储这些快照用于空间推理
此外, 对于快照产生的空间负担, 引入一种预过滤(prefilter)机制, 来快速检索记忆
记忆构建
以下将本文的记忆系统称为 mem, mem 可视为快照的集合,其中的每个快照对象 S ={O, I}, 其中 O 是一簇对象, I 是 RGB-D 帧, 类似其他场景图, 预处理时从每个 I 中提取对象, 对每个对象 o 来说, 它必须被映射到一个唯一的 S 上, 也就是所有 O 的交集为空集
- 初始化:
- 创建一个初始的对象簇 C,只包含一个对象簇 O , O 中有提取出的全部对象
- 创建一个存储快照的集合 S,初始为空
- 获取所有的图像候选对象 I
- 定义一个评分函数 F
- 主循环:
- 当 C 不为空时执行以下步骤:
- 选择 C 中最大的对象簇 O*
- 找出所有包含 O* 的图像候选对象 I*
- 如果 I* 不为空:
- 从 I* 中选择得分最高的对象 I'
- 创建一个新的快照 S*,包含 O* 和 I'
- 将 S* 添加到 S 中
- 否则:
- 使用 K-Means 算法将 O* 分割成两个新的对象簇 O*1 和 O*2,基于 2D 水平位置 (x, y)
- 将新的对象簇 O*1 和 O*2 添加到 C 中
- 从 C 中移除 O*
- 当 C 不为空时执行以下步骤:
- 合并快照:
- 如果存在两个快照 Sj 和 Sk,它们的图像 ISj 和 ISk 相同:
- 从 S 中移除 Sj 和 Sk
- 创建一个新的快照 Sl,其对象集合为 OSj 和 OSk 的并集,图像为 ISj
- 将 Sl 添加到 S 中
- 如果存在两个快照 Sj 和 Sk,它们的图像 ISj 和 ISk 相同:
记忆更新
- 边界快照: 简单地说对未探索区域远远地拍一张照
- 增量构建: 在代理实际运行的过程中, 会不断生成新的观察帧用于提取对象, 对一个距离阈值
maxdist, 阈值内的对象会被添加到记忆中(识别的对象可以是之前见过的), 将对象和观察帧的全集根据这些动态数据更新- 记忆快照更新: 每个时间步 t, 对当前的观察提取到的对象, 以及上一步的 mem 中的对象合并然后聚类, 对新的对象簇进行划分
- 边界快照更新: 每个时间步检查之前的边界快照区域是否已经探索过, 如果已经探索过, 就再拍一张根据当前情况的边界照片
- 预过滤: 在问答场景下, 简单地让一个 VLM 对每个时间步的对象类别根据与给定问题的相关性排序, 只保留有这些类别对象的快照
GraphPad: Inference-Time 3D Scene Graph Updates for Embodied Question
arxiv 2025
本文提出了一种动态更新语义地图(3d 场景图)的系统, 系统最小化存储初始信息, 针对问题来特化地查询与更新, 这样的好处是减少存储和计算的成本
其内存结构分为:
- Scene Graph:
- 节点存储:
- 视觉嵌入
- 语言嵌入
- 描述
- 房间/楼层 id
- 物品可见的关键帧
- 边存储:
- 用于细化的空间关系: on top of, subpart of, contained in, and attached to.
- 节点存储:
- Graphical Scratch-Pad:
- 场景图节点的副本, 但新增一个 notes 字段用于 VLM 模型写入任务特化的信息
- Frame Memory:
- 均匀间隔的关键帧, 如果回答问题时请求相关 api, 会把补充的图像加入
- Navigation Log:
- 结构化存储的索引信息, 用于让 VLM 查找信息
类似其他场景图, 运行过程中会不断合并类似物体, 用 VLM 提示产生边缘, 描述等 提供给 VLM3 个 api:
find_objects: 根据查询尝试找到对应物体analyze_objects: 根据查询分析场景图各个节点的物体信息analyze_frame: 根据查询重新分析图像, 尝试找到之前未检测的物体
VLM 自己选择更新场景图直到认为自己能完成任务
RACCOON: Grounding Embodied Question-Answering with State Summaries from Existing Robot Modules
ICRA 2025
当前的语义地图或者更加宽泛地说, (机器人任务需要的)语义信息的表示和存储, 往往基于 VLM 等成熟的基础模型来编码, 然后导航等任务基于编码出的信息来检索, 这种方法较为依赖 VLM 等外部模型(相对于机器人来说), 从而带来了一个问题, 也就是这个编码过程和机器人无关, 则无法保证机器人能在某种程度上理解问题场景
本文提出的 RACCOON, 下文简称 ra, 一定程度上参考了 RAG 的想法, 虽然其决策依旧使用 LLM, 但将机器人内部模块的状态作为增强的上下文附加到 LLM 上, 这产生了两个问题:
- 机器人的哪些模块的哪些信息应该用于查询的上下文
- 如何将这些信息以文本形式导出
对第一个问题, 这里简单地用一个 SVM(支持向量机)解决, 换句话说这就是一个分类任务, 用一些示例数据训练, 输入的形式是查询的语义嵌入
对于使用多个模块的问题, 使用 KNN(K 近邻)方法解决, 也就是说 SVM 找到一个最重要的模块, K 近邻方法找到若干相关模块
这种方法和 naive RAG 比较类似, 只不过增强检索的是机器人模块信息而不是文档信息
第二个问题也非常简单, 对机器人运行时产生的内部状态, 即使以列表形式直接输入给 LLM, 一般也能被直接理解, 再加入一些描述性的上下文就能很好地实现
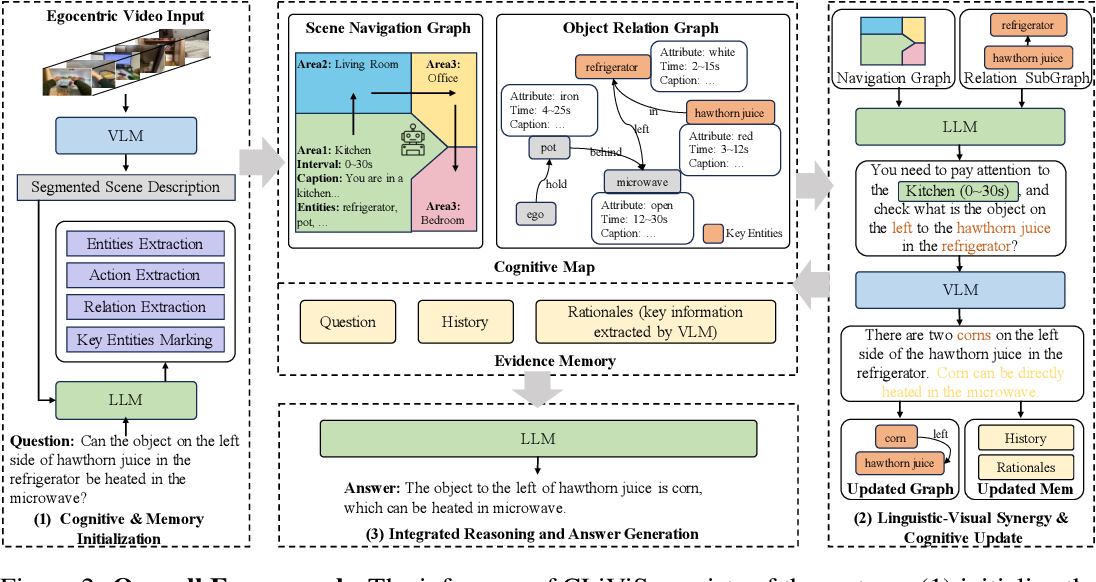
Unleashing Cognitive Map through Linguistic-Visual Synergy for Embodied Visual Reasoning
Arxiv 2025
一般基于基础模型的方法是, 使用图像描述和语言指令作为 LLM 输入来推理, 或者直接用观察帧/视频与语言指令作为 VLM 输入来推理
为了最大程度上利用两种模型的优势, 本文使用语义地图作为 LLM 和 VLM 交互的中间层, 流程可以概况如下:
- 对第一人称视频输入, 切割成固定长度片段
- 每个片段让 VLM 生成粗粒度描述, LLM 提取其实体与其之间关系
- 基于指令, LLM 找出最相关的实体, 初始化一个认知图
- 迭代过程中, LLM 结合已有信息决定何时能回答问题
- 如果 LLM 认为证据不足, LLM 生成指令让 VLM 针对性分析对应视频
- 如果 LLM 认为足够回答问题或者达到最大迭代次数, 让 LLM 生成答案
具体地说, 这里的认知图分为两个图:
- 导航图: 每个节点对应一个独立的时间片段; 边对应片段之间的时间(先后)关系
- 关系图: 包含一些细粒度的语义信息, 节点可以是实体或动作, 边则是节点之间的语义关系
认知图以外, 再定义一个 Evidence Memory(E) 存储 LLM-VLM 的缓冲数据, 例如 LLM 要求 VLM 分析一段视频, VLM 的响应将放入 E 中, 这些证据和对认知图的迭代无关, 只用于辅助推理(也就是问答)任务
也就是说总体程度里模型和数据的交互是:
- VLM 生成描述
- LLM 初始化认知图并产生任务流让 VLM 不断解析对应视频, 中间信息放入 E
- 认知图和 E 不断更新, 每更新一轮让 LLM 决定产生新任务还是回答问题
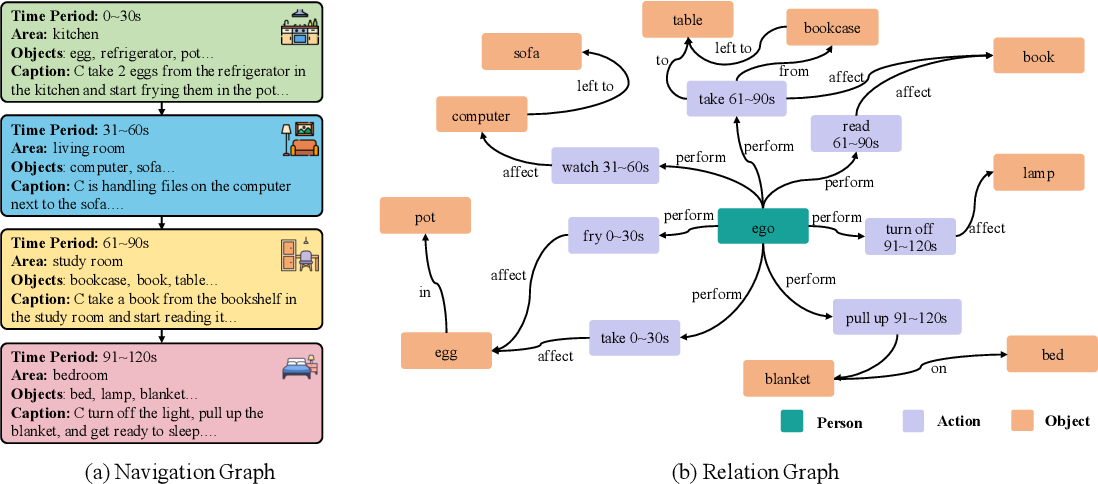
RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Learning in Physical Embodied Systems
这篇文章的亮点是, 参考人类大脑机制, 使用四个可以并行运行的模块来分模块构建语义地图
其记忆机制分为三个模块: historical interaction logs, dynamically updated spatial layouts,accumulated task knowledge 整体流程为:
Information Preprocessor: 处理传感器数据, 具体来说就是rgb图像或者视频, 使用VLM产生描述S和查询Q, 两者形式上都是文本描述, 前者用于当下任务, 后者用于长期记忆Comprehensive Embodied Memory System: 使用RAG,KG技术来提供可靠的存储和检索, 具体分为:Spatial-Temporal Memory System: 分为空间和时间存储, 时间存储由一个环形缓冲实现, 其中的元素是代理的高级计划、低级指令以及环境反馈, 到达上限后会将整个环用VLM压缩为一个摘要再压入环中;空间存储上, 由于我们不需要点云这么详细的地图表示, 使用一个增量更新的KG实现, 更新过程大致为不断搜索位置相关的子KG并插入节点, 让VLM生成边(关系)Interactive Environmental Learning System: 参考脑科学的相关研究, 将记忆分为情景记忆和语义记忆(episodic and semantic memory), 前者存储历史上和环境的交互信息, 后者存储经验性技能型的知识, 实现上两者由RAG实现并不断更新
Closed-Loop Planning Module for Dynamic Environment: 通过Planner-Critic机制来实现闭环控制, 为了避免无限循环, 第一步行动不受批评家影响Low-level Executor
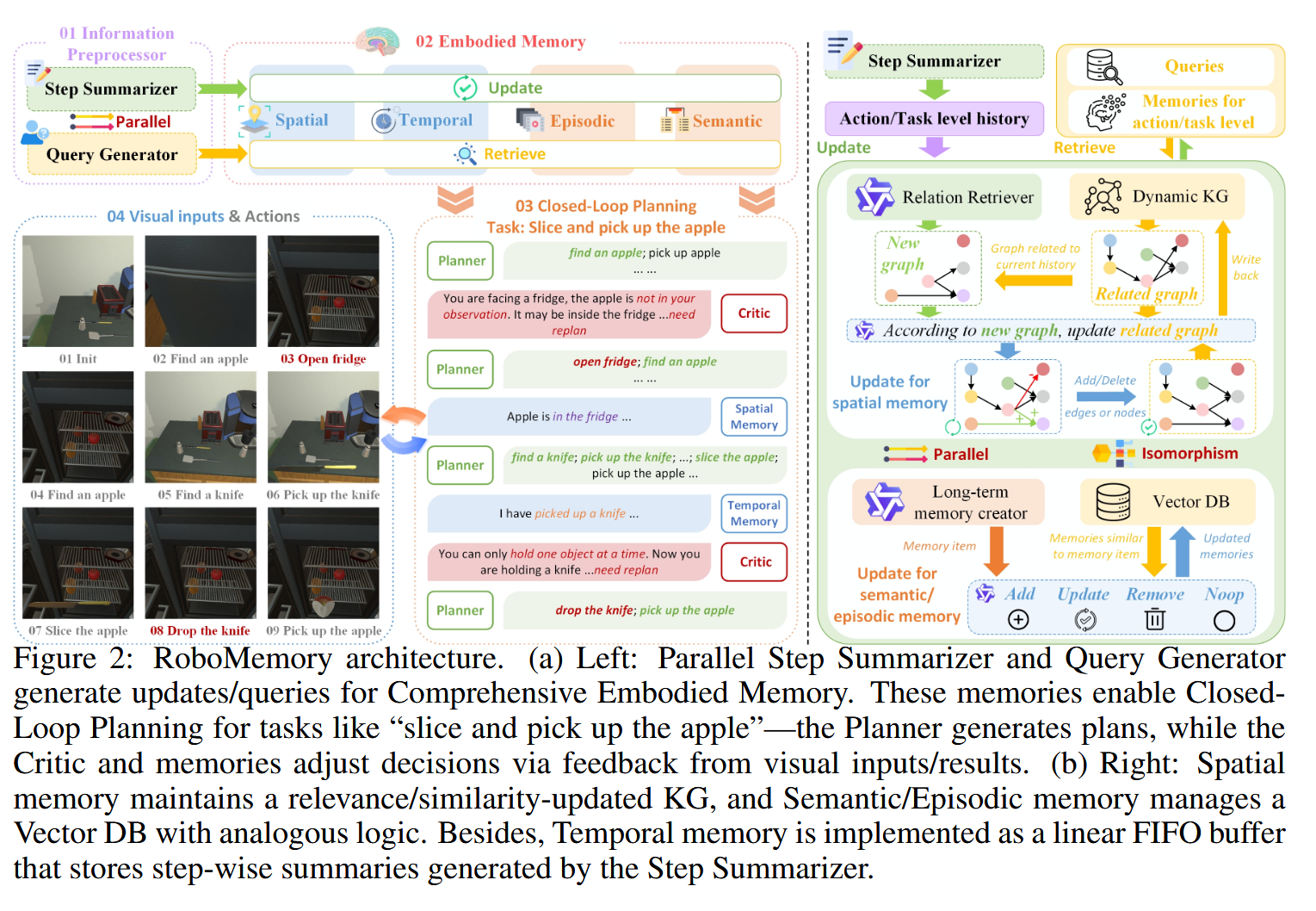
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
2025 ICRA
这篇文章很有趣, 它使用vlm生成的描述, 输入llm分析情感, 情感会作为导航信息嵌入地图中, 并动态更新, 机器人会根据地图中的情感和集合信息导航, 具体来说, 在可行的前提下选择情感成本最低的路径, 例如可能撞到人的路径有较多的情感成本, 因此会倾向于选择不那么可能撞到人的路径
stage 2 summary
这阶段主要查找了一些各种各样的数据存储和检索方式, 包括一篇关于具身智能领域数据存储领域的综述
stage1 中看的文章大多是语义地图中比较常见的拓扑图形式, 拓扑图的节点存储物理位置, 嵌入向量或是文本描述以及点云信息
这样的优点是构建、检索和更新(当然其实大部分都不更新)都很快, 缺点就是信息含量很单薄, 因此只能用于导航, 对动态环境或者一些比较抽象的指令可能语义信息的粒度不够 这阶段看了一些使用知识图谱、数据库、rag 等技术的文章, 与 NLP 领域不同, eai 领域需要与实时环境相关的数据, 因此就知识图谱来说, 如果用一些公开的知识库, 就需要选择性地构建一个和所在场景语义相似度高的知识图, 对 rag 来说也有类似的限制, 即确保检索和当前需求有关的数据
这样的成本应该是比单纯的拓扑图更高的, 但相应地能检索更多的上下文信息, 这些上下文信息一般用于导航以及动作生成中, 有的模型会用来问 LLM/VLM, 有的模型会用作 tf 之类的神经网络输入
这部分的工作可能主要在于数据存储的结构, 需要满足计算和存储成本可控、 高速检索、提供细粒度的数据分类等要求, 如果希望能为导航之外更为复杂的任务, 例如操控任务等提供上下文信息, 则可能需要对原始数据更细致的处理, 将不同详尽程度的信息分层存放, 提高检索效率等
此外, 用于机器人具体任务的语义信息, 例如一些操纵任务, 最简单的情况下需要抓握点之类的 keypoint 等信息, 这种信息可能需要一个比较复杂的神经网络来计算, 并且及其依赖具体的任务场景, 所以很难在探索过程中集成到地图信息中去
关于语义信息存储更新的一些主要问题:
- 在线还是离线构建语义地图? 如果想要能动态更新的在线, 就需要解决计算和存储检索效率的问题
- 用什么形式存储语义信息? 显式的文字描述还是隐式的嵌入向量?
- 给定问题或指令, 怎么检索相应语义信息? 是用余弦相似度还是问 LLM?
- 怎么更新语义地图, 包括更正错误, 对动态环境的更新, 合并重复节点……
DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
由于目前技术上的限制,当前的语义地图往往无法表示实际时空中的连续性,本文提出了一种基于背侧、腹侧的分层机制来实现基于语义地图的导航任务的方式,具体而言,背侧提供语义图的生成和检索接口,腹侧使用相关信息与已有知识,通过vlm进行推理和决策
背侧工作流
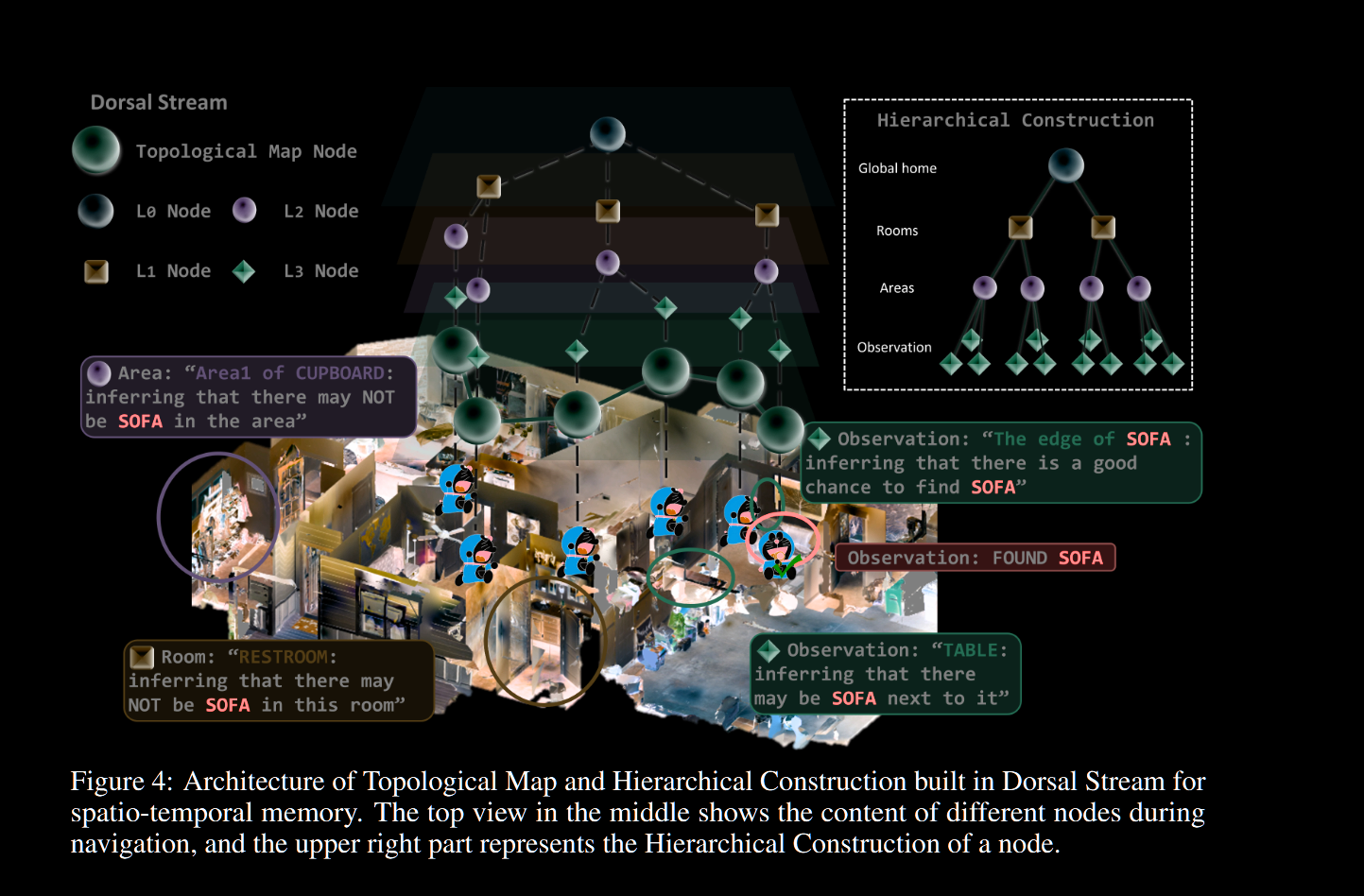 背侧地图如上图所示, 每个结点存储时间戳、位姿、观察、观察嵌入与描述,经过一定时间或欧氏距离超过阈值时创建新节点
背侧地图如上图所示, 每个结点存储时间戳、位姿、观察、观察嵌入与描述,经过一定时间或欧氏距离超过阈值时创建新节点
节点间有层级关系,一共4层,自底向上构建,自顶向下检索,检索使用以下得分函数:
\[S(h_{i})=\alpha_{\mathrm{sem}}S_{\mathrm{sem}}(h_{i},T)+\alpha_{\mathrm{spa}}S_{\mathrm{spa}}(h_{i})+\alpha_{\mathrm{key}}S_{\mathrm{key}}(h_{i},T)+\alpha_{\mathrm{time}}S_{\mathrm{time}}(h_{i}),\]
即节点任务相关性得分、距离得分、关键字重叠度得分与最近时间得分的加权和
构建过程中,先不断生成观察节点,然后运行聚类算法,达到门槛值后产生一个区域节点,区域节点会根据vlm产生一个类型信息,综合考虑空间距离和类型信息再产生更高的层级节点,层级节点被链接到根节点
腹侧工作流
简单地说,使用code-vlm将任务处理为Kg,随后用exec-vlm进行推理决策,使用思想链 Chain-of-Thought(CoT) 来引导这一推理过程。CoT指导exec-vlm将复杂的导航任务分解为可解释的子步骤 即首先生成不受约束的动作建议,随后根据探索价值、安全性、历史信息等信息过滤建议,直至产生最终动作,也就是其输出时离散的动作流
Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
本文提出了一种语义slam, 也就是在slam定位建图的过程中, 对其产生的位姿轨迹,根据其视觉信息计算语义信息,产生语义位姿轨迹,具体来说,其语义就是clip嵌入与房间类别标签
当然,这种分类很明显会遇到边界情况难以处理以及难以收敛的问题,对此,本文提出了一种聚类算法,以及一种闭环检测机制
对房间标签的生成,使用经典的clip对齐视觉语言,即匹配视觉clip嵌入和房间类别的嵌入相似度,边界使用label prop-agation算法的变种, 对每个节点的c个邻居,若其中最常见的标签与该节点不同,则更新节点,每k个帧只进行一次这样的算法
此外,对于同一个类型的房间,可能有多个实例,或者误判为不同、相同实例,为此:
- 对一个新的未遇到过的节点类别,设置一个新簇
- 对一个新节点,若它是已有的房间类并且在簇的平均距离的一个范围内,则将其添加到群集
- 若一个房间内有多个簇,合并没有中间空间(如走廊)的簇
对闭环检测,新的帧计算其房间类别,根据当前定位估计其附近是否有已有的房间簇,比对语义嵌入,视觉相似度(使用pnp)而辅助slam进行位姿优化
Semantic Visual Simultaneous Localization and Mapping: A Survey on State of the Art, Challenges, and Future Directions
语义slam, 也就是利用语义信息辅助传统slam进行定位和建图, 也可以视为语义地图的一种实现方式, 由于slam可以分为端到端基于网络的slam和基于传统算法的slam, 语义slam可以集成在前者的建图过程中或者对后者来说以一个新线程的方式建立语义子图
系统地说,语义slam类似传统slam, 面临的问题包括: (语义)特征信息提取、定位、建图、数据对齐、闭环检测优化
- 语义提取
常用视觉模型,例如对象检测、实例分割、上下文理解等模型, 可以产生语义点云,或者对于特定任务有用的语义信息, 此外如果想做到动态建图, 也需要实时监测实例的能力
此外,也可以实现地点级语义,结合定位能帮助机器人进行闭环检测或执行导航等任务
- 语义定位
现实场景中,imu,传感器等设备带来的误差几乎是无法避免的, 随着slam长期运行,累积误差往往会越来越严重, 因此利用语义信息修正几何层面无法纠正的误差是一个很自然的想法, 例如通过视觉识别, 确定一些稳定的地标(对于室外场景比较实用), 排除一些不适合作为特征点的图像区域(例如人类,汽车等移动物体)
- 语义建图
这部分的关键在于怎么融入语义信息到传统的几何层面slam中,例如在slam构建过程中进行对象级或者房间级的语义分割与标注,或者对作为中间介质的体素图(八叉树)进行标注, 这会不可避免地遇到边界问题,一般用聚类算法处理, 此外,也可以在slam运行中进行"分割", 只保留语义上需要的地图
总之,这一步的主要问题在于,如何处理语义地图与几何地图(例如常见的点云)之间的关系, 一般来说,语义图和几何图是并行构建的, 或者语义信息嵌入在几何图中
近年比较常见的是实例级别的点云划分, 使用IoU标准等进行重叠实例处理, 对于同类别实例的划分问题, 一般会使用各种权重来进行得分计算, 例如对象距离,视觉相似度等, 或者使用基于模型的分类模型
- 回环检测
这一步用于在slam构建过程中识别已有的对象,并用于修正误差,问题在于,对于一个环境,类别一致(外观高度相似)的对象可能同时存在多个,若被误识别反而可能扩大误差, 为此需要特定的检测机制, 例如同时在位姿, 几何形状,视觉上进行判断
Semantic Enhancement for Object SLAM with Heterogeneous Multimodal Large Language Model Agents
本文是一篇比较新的语义slam工作, 使用M(多模态)LLM增强几何slam, 在过程中另外维护对象级语义, 步骤为:
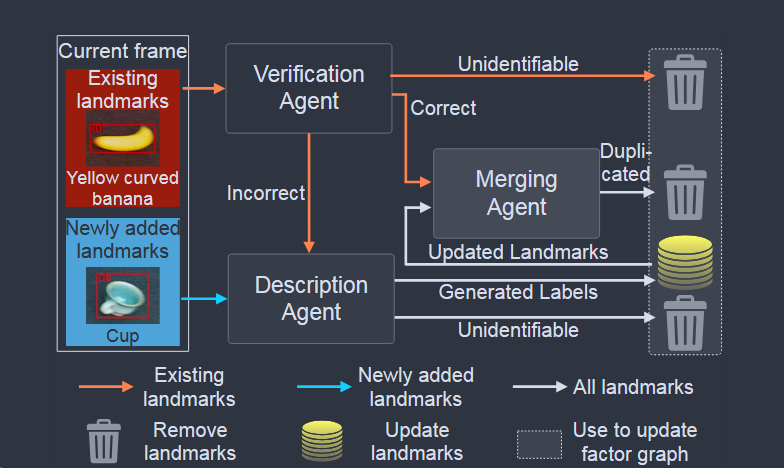
- 对象检测: 使用实例分割模型提取对象掩码(2d), 类别标签,然后计算特征向量, 3d坐标的质心(通过深度图数据)
- 数据关联, 这点主要是检验地标和当前定位测量,具体使用基于先前统计结果的概率估计与卡方校验,以及语义向量的相似度综合处理,将其视为线性分配问题,例如对K个测量, N个地标构建代价矩阵,使用JVC算法求解新测量分配旧地标还是新地标
- 地标投影: 由于未对齐的坐标和图像数据作为输入对MLLM推理的效果不理想,将3d信息投影到图像中产生输入(有点像fastlivo2), 具体来说, 将地标转化到相机坐标系, 若在相机可视范围且深度小于对于深度图, 说明地标可见, 那么将之前保存的地标边框覆盖到rgb图像上, 将处理后的图像作为mllm输入
- MLLM代理: 分为验证、描述、合并代理:
- 验证: 给定3. 中提供的图像, 评估标签准确性, 这步使用一个算力要求较小的分类器
- 描述: 为验证不通过或者新的地标产生新标签, 使用统一标准的语义, 且对近义词优先匹配已有标签
- 合并: 接受整个场景信息与当前帧信息, 合并重复地标
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
这是一篇从信息论角度划分任务粒度从而得到任务相关语义信息的文章
也就是将问题定义为, 给定两组信号XY, 设Y为任务信息, X为感知/语义信息, 目标就是压缩X得到只和Y有关的X子集
信息瓶颈IB(Information Bottleneck)将问题视为 \(\operatorname*{min}_{p(\bar{x}|x)}I(X;\tilde{X})-\beta I(\tilde{X};Y)_{)}\) , 其中 \(\tilde{X}\) 是X与Y相关的子集, I表示两个变量之间的互信息, \(\beta\) 用于控制惩罚奖励项的比重
本文使用Agglomerative Information Bottleneck, 来生成 \(\tilde{X}\) , 这是一种自底向上的合并方法, 从全集X开始,每次迭代使用任务导向的度量来合并不同簇, 合并权值用以下方法计算:
\[d_{i j}=(p(\tilde{x}_{i})+p(\tilde{x}_{j}))\cdot D_{JS}[p(y|\tilde{x}_{i}),p(y|\tilde{x}_{j})],\]
\(D_{JS}\) :Jensen-Shannon divergence, 直观地说, 这个权重度量的是两个变量分布的差异, 优先选择最小权值, 也就是最相似的合并
此外, 计算信息损失度量:
\[\delta(k)=\frac{I(\tilde{X}_{k};Y)-I(\tilde{X}_{k-1};Y)}{I(X;Y)}\]
达到一个门槛值后, 停止迭代
基于直觉和减少计算成本考虑,增量运行该算法时对场景中各个连通分量独立聚类和计算信息损失,且不计算未受新观测影响的连通分量
对XY的相关性度量使用clip嵌入的预先相似度, 且定义一个门槛值, 所有与任务相似度低于门槛值的X不予考虑
DynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
在体素级抽象而非对象级处理动态环境语义建图问题, 这样的好处是省去了昂贵的对象增删合并开销, 具体来说, 对每个体素,存储观察计数、反投影图像id, 语义向量和最近观察时间戳, 运行时, 识别物体并生成逐点特征,反投影到体素, 体素存储所有内部点的平均语义
对物体的移除, 使用一个简单的方法判断: 遮挡关系, 对应当遮挡后面的体素,深度合理且反投影后在相机可见范围的体素, 如果没有遮挡,就视为已经移动,移除该体素
对物体查询任务,先根据语义余弦相似度找到top-k个候选体素的图像,随后让vlm或者专门的物体检测模型查找目标
对探索功能, 由体素地图生成障碍物图(简单地将高于地面一定阈值的体素视为障碍), 未被标记的部分视为探索目标, 对其排序可以使用语义相似度或者最久未探索时间, 若干轮探索后重新执行检索任务
Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
该系统假设运行于半动态环境, 也就是初始化时静态环境, 随后会发生局部变化
类似dualmap, 起初由slam生成位姿用于反投影, 使用实例检测和分割模型生成物体点云, 用clip生成嵌入, 用视觉、类别嵌入相似度以及空间重合度为基准关联对象
地图形式为3d场景图, 为方便存储计算, 关联完的点云进行体素化, 特别之处在于对对象之间的关系进行分类:on,belong,inside, 此后, 为了在动态环境下更新场景图, 舍弃slam, 使用基于模型的方法估计当前位姿, 也就是以此前的数据训练模型,实时rgbd帧为输入产生输出, 使用的ACE模型产生粗略的估计位姿, 再用LightGlue 模型匹配一个最接近的历史图像, 这个历史rgbd的数据生成点云与最新帧对应的点云进行ICP运算,得到一个转化矩阵, 将其与估计的位姿相乘,就能得到一个相对准确的位姿估计
得到最新的位姿估计后, 用于进行动态检测, 例如对体素, 反投影到相机坐标系和像素坐标系, 对投影后可见的点, 取其投影深度与depth图的对应深度, 其颜色和对应像素颜色的差距绝对值, 若超过一定阈值, 则认为其已经移动, 进行删除
对涉及变动的对象(节点), 对其父节点和父节点的所有子节点, 这些节点与变动节点的边被移除, 随后对仍在场景图内的变动节点, 重新计算空间关系
导航目标的选取使用余弦相似度, 对于有空间关系的任务, 例如a在b内,则使用额外的距离约束来查找目标, 对于操作任务, 提供掩码、启发式算法得到的抓取范围、质心等额外信息给机器人
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
实现交互式探索的3d场景图, 在基础的场景图节点及其关系边之间添加“条件动作"边, 与动作节点, 边的类型分为:
- 对象边
- 对象->动作边, 表示对象能执行某个动作
- 动作->对象边, 表示执行某个动作会得到一个对象(例如打开冰箱门会得到一个冰箱门内的对象)
- 动作边, 表示先执行一个动作才能进行另一个动作
上述的图简称为acsg(action-conditioned scene graph), 根据此图的探索视为一个马尔科夫决策过程, 目标是不断更新这张图, 通过设置一个奖励函数来实现这点, 简单来说就是奖励发现新节点、探索旧节点以及随时间增加微弱惩罚项
类似大部分3dsg, 使用目标检测和分割模型提取实例, 不断进行深度检测来实现对动态环境或者测量误差的动态增删, 条件动作边的增改使用LMM实现, 这也是本系统最大的挑战, 这里使用提议者-批评者模式, 批评通过后建立新边
对动作系统, 主要使用启发式方法提取操作点和相关参数
IROS: A Dual-Process Architecture for Real-Time VLM-Based Indoor Navigation
就导航任务来说, 单纯的动作模型(VLA)难以满足长期规划功能, 而基于VLM的导航推理速度较慢, 且有上下文容量限制, 因此本文提出了结合快速反应与长期规划的双系统导航架构
快系统(fast perception)
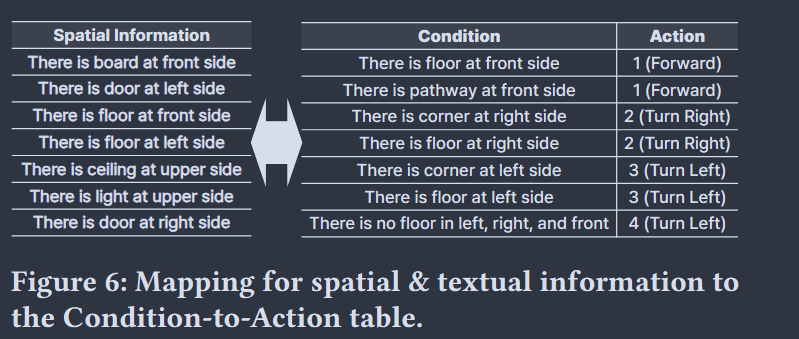
对室内导航任务来说, 例如在走廊场景, 大部分时间的动作决策都是简单的前进, 不需要复杂的vlm系统辅助决策, 用一个条件动作表即可解决这样情景下的需求(表由vlm初始化) 具体来说, 流程如下:
- 关键帧比较(Key Frame Compare KFC): 轻量级门控机制(lightweight gating mechaism), 实时监控视觉编码器的输入, 与上一次触发推理的帧比较, 差异超过阈值后, 激活慢系统
- 具体实现可以有多种方法, 本文基于捕捉局部结构考虑, 使用补丁级别(patch-level)的嵌入, 由此捕获局部结构的变化, 例如拐角, 基于全局语义的视觉模型则可能忽略这些局部变化
- 空间/文本理解: 出于机器人有限的硬件算力考虑, 本地vlm性能受限
- 空间理解使用启发式方法弥补算力不足, 即首先用分割模型得到2d掩码, 随后提取"消失点"(一般为视觉帧的中心), 得到消失点后由此区分场景区域(前后左右、近景/远景)
- 2.1中提取的空间信息表示为文字形式, 与ocr模型识别的文本信息共同构成文本理解的输入
- 条件匹配: 分为目的地到达检查和视觉-条件匹配:
- 目的地到达检查: 计算目标描述与视觉编码器输出的嵌入相似度, 并监控ocr输入, 如果有相关文本以及相似度超过阈值,判定已经到达目的地
- kfc触发后, 进行视觉-条件匹配, 将空间、文本的嵌入与条件匹配,超过阈值的动作插入一个集合,若集合只有一个元素,直接执行,否则由慢系统进一步思考
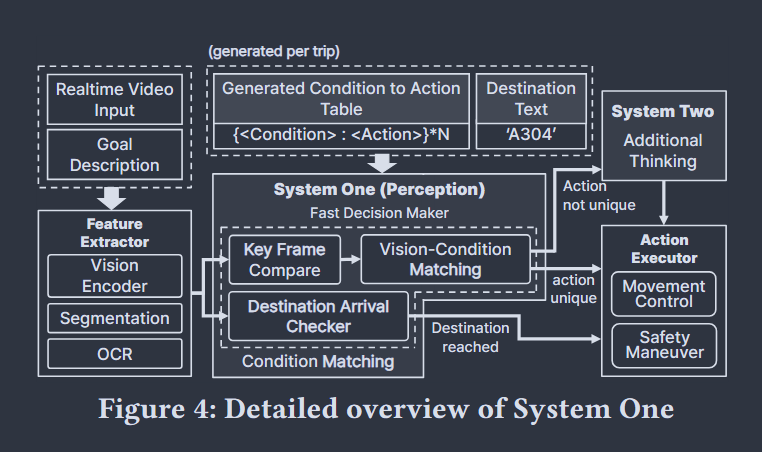
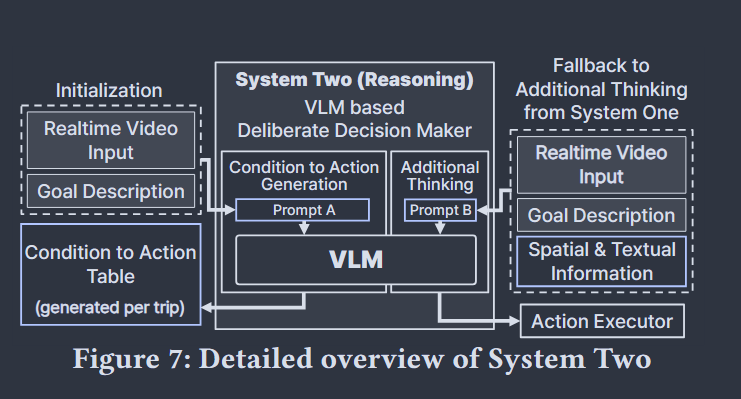
慢系统(deliberative reasoning)
慢系统复杂在初始化时根据初始视觉帧和目标文本生成条件动作表,该表条目数量收到机器人动作集的限制, 以及在运行过程中为快系统难以判断的情况提供裁判
对上述快系统无法判断的情况, 即附加型思考, 此时将目前信息作为输入, 让vlm生成特定格式的动作输出, 为确保实时性, 对token预算进行限制, 快要耗尽时抑制非动作token的logits, 确保模型尽快产生动作输出
FSR-VLN: Fast and Slow Reasoning for Vision-Language Navigation with Hierarchical Multi-modal Scene Graph
本文提出了一种对HOVSG进行改进, 并类似IROS使用动静双系统导航的分层场景图系统
在HOVSG的基础了,引入视图节点来增加视觉信息, 该节点表示房间内的特定视角,存储视觉帧、位姿、嵌入和描述等信息(实时位姿由fast-livo2 生成), 因此能借助位姿信息编码其附近对象的可见性关系
本系统使用图像节点与vlm推断房间名称, 因为相机视图能提供更丰富的语义信息, 对每个对象, 保留一个视图, 让这个视图在所有能见到该对象的视图中拥有最小的深度
检索方案分为快慢双系统:
- 快系统: 给出自然语言输入后, 若llm能提取房间名, 对房间内对象及其关联的视图节点进行匹配; 否则并行地执行下面两个匹配
- 用输入语句嵌入向量与对象节点嵌入向量匹配, 用最佳匹配为候选对象,提取其对应视图
- 用输入语句嵌入向量与视图节点嵌入向量匹配, 用最佳匹配为候选视图
- 用输入语句嵌入向量与对象节点嵌入向量匹配, 用最佳匹配为候选对象,提取其对应视图
- 慢系统: 鉴于clip匹配的精度有限, 需要进一步验证, 首先验证快系统中得到候选对象是否在视图中, 若没有, 则认为目标对象应该在候选视图或相似视图中, 候选视图记为v, 用llm提取描述最相似的视图v', 以语义向量相似度为标准用vlm遍历这两个视图中的目标对象

RAG-3DSG: Enhancing 3D Scene Graphs with Re-Shot Guided Retrieval-Augmented Generation
这篇文章主要解决不同视角下同一个物体识别稳定性的问题, 分为以下步骤:
- 物体实例提取, 类似大部分3dsg, 使用实例分割模型提取物体掩码, 类别标签, 语义嵌入等信息,并通过反投影得到物体点云, 这一步得到的一系列点云构成局部目标列表
- 全局实例融合与降采样: 根据对象box大小进行降采样, 公式为: \(\delta_{t,i}^{\mathrm{voxel}}=\delta^{\mathrm{sample}}\cdot\left|\left|\mathrm{Bbox}(p_{t,i})\right|\right|^{1/2}_2\), 其中 \(\delta^{\mathrm{sample}}\) 是一个常数, \(\mathrm{Bbox}(p_{t,i})\) 是点云 \(p_{t,i}\) 的边界框对角线长度, 大物体的点云会被更稀疏地采样, 小物体的点云则相反 ; 降采样后, 通过最近邻比例(距离阈值由物体大小动态决定)与语义相似度得分进行全局实例融合, 点云增量融合, 语义向量则进行滑动平均
- 描述生成:
- 初始描述生成: 将top-k分割置信度的掩码对应裁剪区域的视觉帧输入vlm, 得到k个初始描述
- "重摄影": 由于机器人运行环境下可能存在的传感器误差、外物遮挡等原因, 用于生成描述等语义信息的各类视图不一定是正确的, 需要对其置信度进行评估, 以及对其进行修正, 修正使用所谓的"重摄影", 也就是对全局点云以另一个合理视角"拍照", \(S_{\mathrm{vis}}={\frac{|p^{\mathrm{visible}}|}{|p|}},\quad S_{\mathrm{horiz}}=1-|v_{i}\cdot g|,\quad S_{\mathrm{prior}}={\textstyle{\frac{1}{2}}}(1+v_{i}\cdot f)\) , 对64个候选视角, 根据以上得分函数的加权和进行评选(分别为点云可见性、与重力向量角度(惩罚俯视仰视视角)、与此前视角的一致性)
- 可靠性评估: 对此前的k个描述与重摄影得到描述嵌入以此计算相似度, 以相似度为标准聚类, 最佳聚类将作为最后的描述参考, 并得到一个可靠性分数s
- 物体级别的rag: 按上一步得到的可靠性分数排序, 前50%的物体视为可靠的环境上下文来源, 对剩余50%的不可靠物体, 其最近的可靠物体的视图、重拍图片、最可靠掩码裁剪作为输入, 由vlm重新生成描述、类别等语义信息
- 用vlm对完成更新的全局节点之间生成空间关系
语义点云/slam总结
如何实现动态环境的建图更新?
slam视角
首先讨论动态环境下slam需要什么, 就slam这门技术的本身特点和当前技术条件下对其的期望来说, 定位功能是远比建图重要的, 而定位功能在静态环境能相对稳定的运行, 通过存储一些特征点也能做到闭环检测, 但遇到动态环境, 假设固定的特征点如果改变,就会对定位估计造成误差
对此一般有几种思路:
- 先假设所有特征点都是静态的,再估计误差
- 不用原有的视觉方法, 使用几何约束来检测动态特征
- 直接用imu估计相机位姿, 从而区分动静特征
即使想办法解决这些问题, 但就动态环境建图这个问题而言, 本身就有很多麻烦之处, 例如存在较多遮挡关系, 或者变化过大导致无法追踪特征
那么如果引入语义信息呢?例如通过实例检测模型提供物体级别的语义, 实现对动态特征点的追踪, 这样的静态检测是可行的,但如果想用于slam, 也就是定位过程中, 不同帧之间物体的运动追踪就是一个难题, 这部分的难点有: 如何维持一个物体在slam运行过程中的稳定性(特别是在被遮挡一段时间的情况下), 以及如何通过这个物体优化相机位姿不出现累积误差
此外, 也可以将语义信息用于特征点选择, 也就是通过语义分类排除动态物体, 只选取静态物体的特征点, 这样的问题在于, 一些模糊的划分反而会减少用于建图的几何信息,例如停着的车仍然可能会被划分为动态物体, 但它实际上可以作为特征点用于定位
还有一个致命的问题是, 由于slam依赖传感器信息, 经常直接运行于机器人本体, 而语义信息检测往往基于一些算力较大的模型, 这会产生实时性问题
一个折中的办法是,使用三维几何体级别的语义, 也就是在slam层面匹配物体框架, 例如长方体或者几何曲面
目前来说, 比较实用的相关方法依旧基于传统的常用slam方法, 例如orb3, 然后使用基于模型/算法的方法检测出动态物体滤除,从而用于slam定位与建图, 举一个近年的例子(2025IROS NGD-SLAM)
该方法试图避免使用昂贵的gpu算力, 从而能在直接部署于机器人本体的同时保持动态环境定位能力, 使用运算简单的算法来进行动态区域排除, 具体来说:
- 另外设一个子线程, 接受一个时间点的视觉帧t0, 使用算力要求低的yolo提取(被视为动态类别的)物体边框(在实例代码中只识别人类),使用前景深度聚类后,提取最大联通子区域来得到准确的掩码M, 在之后的时间点t1, 将掩码M交给异步运行的主进程(我们希望t1-t0的时间差尽可能小)
- 接收到掩码(也有可能模型检测失败,那么直接使用上一次的计算结果)后, 使用光流法追踪区域内特征点的变化, 得到一个更新后的动态对象的掩码区域M'
- 在原有orb3的基础上排除M'区域的特征点进行定位计算, 光流法只用于掩码的迭代和估计, slam部分仍然使用orb3的特征点法
场景(拓扑)图视角
对场景图, 或者说主流的语义地图来说, 定位可以不那么重要, 只有建图是重点, 但就建图而言不需要做到cm级别的精度, 只需要大体上的拓扑关系, 因此可以维护对象级别的语义拓扑图, 用实例检测进程来维护
主流类似于dualmap的方法是, 在运行中使用实例检测和分类模型等检测出场景实例, 对一个特定实例, 如果满足一些特定的动态条件则进行合并/删除/拆分等更新操作, 这样的更新本质上是半动态的, 假设场景的变化只占用很少的时间且占据不大的比例, 这个假设符合大部分实际场景, 如果不需要通过视觉进行精准定位, 应该是可行的 接下来介绍一篇类似dualmap的实现半动态建图的方法(Where Did I Leave My Glasses? Open-Vocabulary Semantic Exploration in Real-World Semi-Static Environments 2026 RAL)
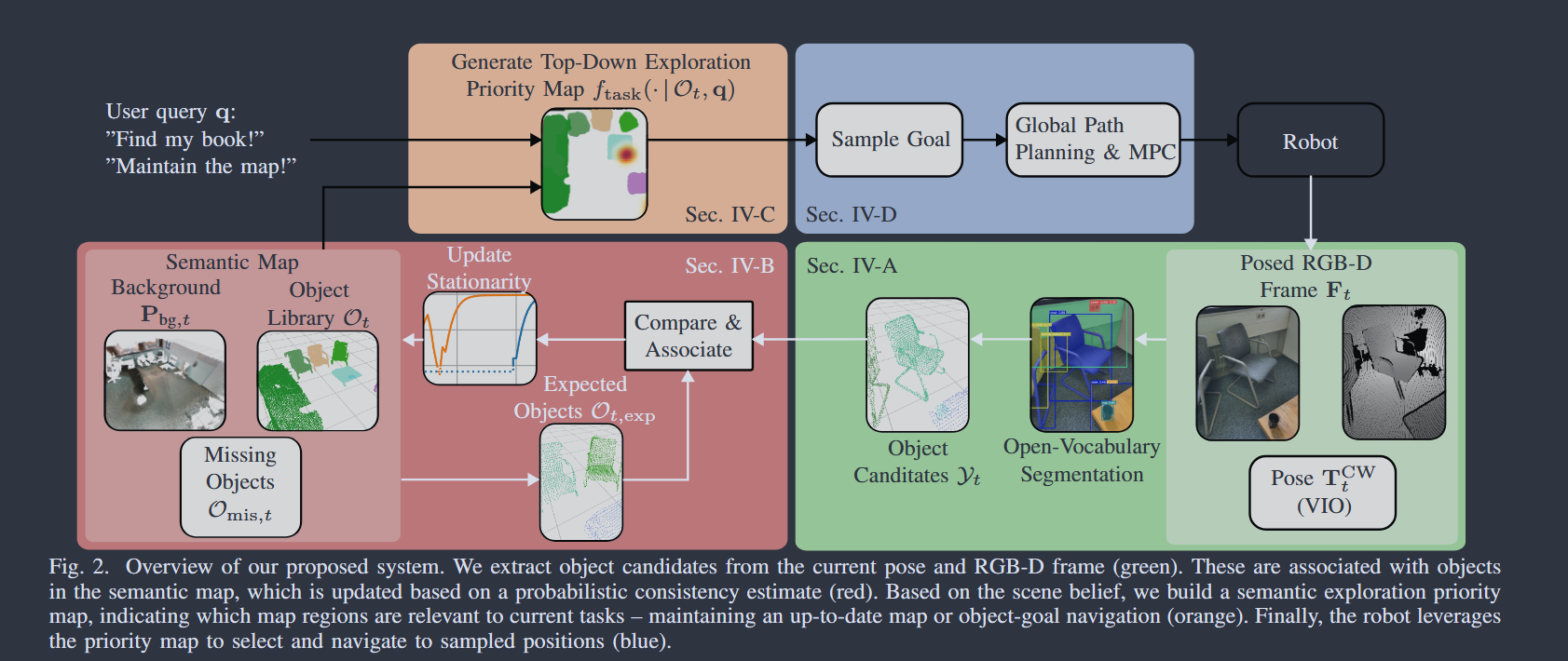
这篇文章假设能通过imu信息直接得到相机位姿, 也就是不考虑用视觉信息修正定位
- 初始化: 类似dualmap, 用sam,clip等模型检测实例, 维护其嵌入, 类别标签等语义信息, 此外还维护一个没有检测到实例的背景点云
- 对象合并: 运行过程中, 目前已有且在相机fov内的对象,过滤深度后进行反投影映射到相机的像素坐标系上, 若投影后可见部分超过一定门槛,设置为候选对象, 对其与当前帧检测到的对象进行匹配, 分数设置为语义嵌入相似度和几何重叠度(两个对象点云中距离在阈值内的点/两者点数的最小值), 先以几何重合性贪心匹配, 随后对重叠度不超过门槛的可能有移动的且语义相似度达到门槛对象,进行相对昂贵的ICP运算(对两个点云寻找一个最合理的运动, 使其能相互转化), 伪代码见下图,其中Y为新检测对象,O为已有对象
- 稳定性评分: 虽然不能实时追踪运动, 但对于已经维护好的动态对象, 可以对其变化的程度进行评分, 标准为 几何移动距离+对位置变化的“信念”, 文中使用贝叶斯概率模型建立对物体类别先验信念、历史移动距离、当前观察等变量之间的模型, 对很久没有观察到的对象, 让其不变的信念自然衰减到一个阈值
- 用整体对象集合的两个子集区分最近可见与不可见的对象, 若静止信念过低, 视为不可见对象, 被标记为不可见的对象后的一段窗口内, 可以在可见对象里查询匹配对象, 防止错误标记为不可见
- 任务: 简单地说, 每个对象根据自身信念产生一个探索优先级的分布, 将任务分为维护和导航, 维护任务根据探索优先级来生成路线; 导航则使用LLM产生候选对象

Vision-Language-Action Models
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
前言
机器操控, 作为机器人学和具身智能的关键领域, 需要精确的动力控制以及内置的视觉和语义信息理解能力的智能, 其传统做法一般局限于使用预定义的动作以及严格的控制策略, 泛用性较为有限
近年来随着算力和研究方法的进步, 基于大量图像文本数据上预训练的大型视听语言模型(VLM)以及基于 VLM 增加了动作能力的 VLA, 可以称为一种新的技术趋向
所谓的 VLA 其实是一件很有野心的事, 它不但有对图像、文本这两种信息量最大的载体的理解能力, 还要有做出合适行动的机械系统, 这几乎涉及了 cv, nlp, em-ai 等 cs 大部分的前沿领域, 理论也相当庞杂
VLA 具体可以定义为:
- 使用 VLM 理解视觉观察和自然语言指令
- 进行推理并直接或间接地帮助动作指令的生成
又可以分为:
- Monolithic Models: 单片模型, 也就是集成度高的模型
- Single-system models: 将环境理解, 视觉感知, 语言理解, 机器状态认知, 动作生成都统一到一个模型
- dual-system models: 将认知环境和动作生成分为两个任务, 分别让 VLM 和一个 action expert 去做, 这是因为相比前者, 后者时效性更强
- Hierarchical Models: 分层模型, 耦合度最低的模型, 一般有结构, 中间输出可解释的中间产物, 例如计划模块产生
keypoint detections,affordance maps,trajectory proposals, 交给策略模块来产生动作; 这样的解耦让不同模块可以并行训练, 使用不同的 loss 和优化方式
Keypoint Detection: 计算机视觉中的一种技术, 旨在识别图像中具有显著特征的点Affordance Maps: 一种表示对象与环境之间交互可能性的图像或图形Backbone: 一个神经网络结构的基础部分, 主要用于特征提取 Backbone 是整个模型的核心组件, 负责从输入数据(如图像)中提取重要的特征信息Internet-scale: 表示很大的数据或者整体性能消耗的规格
背景知识
得益于用于跨领域和多模态能力的 VLM 的出现, 现代的 VLM 模型能执行对能力需求更加多样的任务例如自动驾驶, 图形用户界面交互等
这些模型往往由一个视觉编码器, 一个用于将视觉特征嵌入到文本的投影器(projector), 以及一个大语言模型组成; 这其中, 最为重要的是 大 模型为其带来的泛化能力, 如 GPT4 这种 LLM 能提供极强的过滤输入, 降噪, 处理模糊指令的能力, 从而为 VLA 定下基础, 也就是说, VLA 相当重视泛化、通用性质的能力
V、L、A 可以视为三种不同的任务, 早期的模型往往会将三者分开, 这样的好处是可以并行训练, 但缺点是可能降低一些理解和推理能力; 最近的模型一般会加强集成度, 例如除了传统的大规模(Internet-scale)训练资料外, 把机器人的动作也转化为文本标记并放入训练语料库中, 这能让 action 作为语言任务被语言模块理解, 增强整个模型的理解能力, 其他一些使用动作资料的模型也取得了较好的效果
接下来从单片/多片的角度讨论两种模式的发展趋势
MONOLITHIC MODELS 单片模型
Single-system Models
其经典范式为 Autoregressive Decoding, 将机器人的连续动作空间离散化为 token 序列, 模型能够序列化地生产动作 token, 再由一个 de-tokenizer 转化为具体动作。较为知名的模型有 RT series , OpenVLA
Model Performance Enhancement
- 认知模态(Perception Modalities):
- 3d 感知(perception): 一般能从传感器得到的数据就是 2d 图片, 为了构建 3d 的地图模型, 可以模拟环境并根据图片画出点云; 或者根据图片及其深度信息, 画出自我中心的地图
- 4d 感知: 多出来的 d 指的是轨迹, 也就是时空序列信息, 例如将动作或者轨迹信息添加到图像中, 从而增强模型的时空推理能力
- 触觉和听觉(Tactile and auditory)感知: 触觉信息可以使用视觉编码器, 听觉信息可以使用专用的编码器, 且两者都需要专用的数据集, 这两种能力均可以与语言模块对齐, 然后得到接受听觉触觉指令的能力
- 推理能力: 以下简单介绍一些相关工作
ECoT: 生成一个推理链, 将高层任务规划与视觉特征相结合, 输出最终行动CoT-VLA: 引入视觉链式推理, 通过预测代表计划状态的子目标观察, 增强推理能力LoHoVLA: 采用“层次闭环控制Hierarchical Closed-Loop Control”机制, 解决规划错误、行动失败和外部干扰等问题, 适用于长周期任务ReFineVLA: 通过“选择性迁移微调Selective Transfer Fine-Tuning”策略, 仅微调上层, 增强多模态理解
- 泛化能力: 也就是处理各种场景需求的能力
UniAct: 定义一个Universal Action Codebook, 将所有机器人行动抽象到有限的类别中, 增强泛化能力ReVLA: 使用可逆的训练策略, 缓解遗忘问题HybridVLA: 使用一个Collaborative Action Ensemble机制, 融合diffusion and autoregressive decoding, 针对任务选取不同策略VOTE: 使用一种Ensemble Voting机制, 将过去的动作预测根据与当前预测的相似性进行分组, 并对大多数集进行平均处理, 从而生成更稳健的动作输出- 也有一些模型在物理规律层面进行学习
Inference Efficiency Optimization
Inference Efficiency Optimization 推理效率优化 : 机器人对及时性(控制频率)往往有一定要求, 因此模型的推理效率优化也是一个重要的方向
Architectural Optimization 体系优化: 一些常用的方法用, 跳过层级, 早停止等, 进阶的有一些方法会动态计算哪些层级是关键的, 从而激活关键层完成推理; 此外也有方法会逐步减少视觉 token, 也就是修建掉那些与指令生成无关的 token, 再加上注意力机制, 这甚至能同时提高指令准确性Parameter Optimization 参数优化: 也就是压缩模型的大小, 通过蒸馏的模型提高效率; 或者使用 tokenizer 将高维动作指令转化为 token 的序列从而减少模型复杂度Inference Acceleration 推理加速: 即加速动作解码, 可以使用专门优化过的 action head, 一次生成一个动作序列; 通过某种方式实现并行运算等; 也可以单纯地(但有选择地)放开限制, 接受一些“不完善”的推理结果
Distillation-Aware Training: 一种优化训练方法, 旨在通过知识蒸馏(knowledge distillation)技术提高模型的性能和效率。这一过程通常涉及将一个大型、复杂的“教师”模型的知识转移到一个较小的“学生”模型中, 以便在保持性能的同时减少计算资源和加速推理action head: 用于将模型的输出转换为具体的动作或决策的组件
Dual-system Models
双系统主要是为了解决动作生成速度与推理速度要求不同的问题, 引入了一个动作专家模块来对系统解耦, 而其与分层模型不同的是, 不会产生可解释的中间输出

Cascade-based Methods
串联的方法中, 负责推理部分(称为高级 high-level )的系统一般使用 VLM 处理多模态的输入, 提取语义并产生动作 计划 输出, 这些会被编码为某种中间形态, 然后由低级(low-level)系统解码为具体的动作指令
由于在双系统中, 认知和行为是解耦的, 行动可以使用一个不同的模型, 例如 diffusion transformer, Behavioral Cloning transformer
此外, 还有很多种改进方法:
- 再加入一个视频生成模块来预测未来的帧, 并使用
diffusion action expert - 从人类演示中提取场景喂给 LLM 来生成可解释的行为树, 并转化为底层行为
- 将 VLM 与扩散策略模型整合, VLM 会发射一个 TOKEN 控制是否允许动作生成
- 使用预训练的卷积残差网络增加性能
- 将 action expert 集成到 VLA 主干中, 两者可以复用一些组件, 协调工作
Cartesian Actions: 机器人学和控制系统中使用的一个概念, 指的是以笛卡尔坐标系为基础的运动或操作。这种动作通常涉及到机器人的末端执行器(如机械手臂的抓手)在三维空间中移动或执行任务convolutional residual: 卷积神经网络(CNN)中使用的架构设计, 最著名的实现是 ResNet(Residual Network)。这一设计理念旨在解决深层网络训练中的退化问题, 即随着网络层数增加, 模型的性能反而下降; 引入残差连接(residual connections), 模型可以学习到输入与输出之间的“残差”而不是直接学习目标输出
Parallel-based Methods
上图中展示了一种共享注意力的架构, 它受到 mix-of-experts (MoE) 启发, 在注意力层中, VLM 与动作模块进行 token 上的交互, 过程中, 输入的视觉文本信息, 噪声, 机器人特定的输入在共享的注意力层中交互, 从而提高了任务效果
由于这种架构的低耦合性, 它可以实现字面意义上的 MoE, 也就是对每个子任务都让一个“专家”去做, 其中一个典例称为 π0, 其主干网络是 VLM, 为了处理机器人特定的输入输出, 它使用一个独立的权重集合和一个流匹配(Flow Matching(FM))的动作模块
π0 有一些变种, 例如增加显式推理, 基于最近推理生成动作两种模式, 可以根据需求切换; 降低信息力度; 防止动作模块的梯度流入 VLM 以保持 VLM 的知识优势; 增加动作 token 化方法从而自回归训练等; 其他的变种也一般是增加某个维度的输入或者通过复用注意力信息提高性能等常规优化
Normalizing Flows(NFs): 通过一系列概率密度函数的变量变换, 将复杂的概率分布转换为简单的概率分布, 并通过逆变换生成新的数据样本Continuous Normalizing Flows(CNFs)是Normalizing Flows的扩展, 它使用常微分方程(ODE)来表示连续的变换过程, 用于建模概率分布Flow Matching(FM)是一种训练Continuous Normalizing Flows的方法, 它通过学习与概率路径相关的向量场(Vector Field)来训练模型, 并使用 ODE 求解器来生成新样本
HIERARCHICAL MODELS 分层模型
对于很大规模的任务, 由于算力, 存储空间等方面的要求都较高, 更低耦合的架构如分层模型较为常用, 例如长期推理, 空间抽象, 动作分解等
这些模型一般由高等级的 planner, 低等级的 policy 等组成, 计划期接受指令和观察, 转化为中间产物, policy 接受中间产物, 产生动作序列或底层指令
相比单片模型, 它能实现更复杂的组合, 甚至可以只有计划器; 相比其单片双系统, 它的中间产物是显式(可解释)的
Planner-Only
可分为:
Program-based Methods: 计划器生成中间程序, 即直接可执行的程序或者辅助程序, 辅助程序一般用于辅助对任务策略的制定Keypoint-based Methods: 标记出一些关键点, 例如机器臂的可抓取点, 导航任务的路线节点等, 这些提取出来的点可以视为对问题的一种抽象, 从而输入给通用模型如处理, 也可以用作轨迹生成Subtask-based Methods: 一般用于较大的 VLM, 接受一个抽象的隐式指令, 并输出详细的文字命令, 实际部署中可能还会需要一个控制策略。由于该种方法抽象程度较高, 可以使用一些通用模型进行任务分解或者规划
Planner+Policy
其分类上和前一类较为类似
可分为:
Keypoint-based Methods: 一般用 LVLM 产生一些关键点, 或者关键路径, 但这些信息将会交给低级策略模块, 用于生成指令; 例如在导航任务中, 对 生成的关键点进行排序, 并将这个有序路径用于之后的指引; 此外也可以用 LLM 为关键点赋予 cost, 用于确定最佳路径; 也有方法会将关键点赋予互动性上的标注, 用于生成控制指令。总的来说, 一般关键点会被赋予帮助决策的一些信息, 用于最后产生指令Subtask-based Methods: 这种方法主要的工作在于如何划分子任务, 而对具体的子任务执行者则有很高的灵活性。例如对模糊的文字指令, 将其转化为一系列原子命令; 也有模型分出空间感知任务, 使用点云增强空间感知; 或者让高级模型划分任务, 低级扩散策略模型具体实现, 且这样的划分可以继续拓展, 例如再加一个中间的 skill 层辨识一些可重复使用的行动控制底层的执行者; 划分后的子任务也可以一步流水线执行从而增加效率; 这方面有非常多的类似变种
Embodiment-Agnostic Affordance Representation: Affordance 前文介绍过, 是对可交互性的标识, 而 Embodiment-Agnostic 指的是不依赖于机器人形态或者物理特性, 可以理解为通用的可互动性
Monolithic vs Hierarchical:
- 两者的输入输出是一致的, 主要区别为统一化/模块化的内部结构, 其优缺点和这两种常见的结构是类似的
- 另一个关键区别是中间产物的可解释性, 整体模型的中间产物不可解释, 但更方便机器学习一些人类可能无法理解的特征; 分层模型输出可解释的中间数据, 这对需要兼容性, 可解释性的操控领域可能更好
其他前沿领域
- RL: 与 LLM, VLM 不同的是, VLA 的问题更加长周期, 其最大的问题在于难于产生基于规则的奖励函数, 可能人类也不知道怎么做是更好的, 这方面没有特别好的解决方法, 一般将学习过程作为密集奖励或者以视觉上的近似成功率作为奖励;
- 此外, 由于模拟环境现状, 在线学习效率有限, 一些方法会把在线, 离线方法混合起来, 例如离线用 q 学习, 在线用
Soft Actor-Critic提高效率又或者引入人类监督 - 部分方法会只把 RL 用作数据引擎来增强泛化能力, 例如先用 HIL-SERL 训练, 然后通过 sft 将训练成果提取融入给主要模型
- 此外, 由于模拟环境现状, 在线学习效率有限, 一些方法会把在线, 离线方法混合起来, 例如离线用 q 学习, 在线用
- Training-Free Methods: 通常利用模块化和可扩展的设计来改进现有的 VLA 架构, 而无需训练, 例如改变触发机制, 行为和视觉都稳定时不需要完全解码, 可以选择性重用之前的 visual tkoens; 其他的类似方法也是对于简单, 复用性强的任务使用低成本的方式计算, 或者通过一些变换方式压缩动作序列等负担较大的数据提高效率
- Learning from Human Videos: 也就是将人类行为与机器行为对齐, 从而提高机器人行为的表现
- World Model-based VLA: 世界模型(模拟环境), 允许一定程度上对未来状态的预测, 从而让 agent 能根据预测修正自己的策略, 并且世界模型也可以同步改进
Robotic Process Reward Model (RPRM): 一种用于强化学习和机器人控制的框架, 为机器人在执行特定任务时的行为提供奖励信号, 进而不断优化其行为模式HIL-ConRFT(Hardware-in-the-Loop Control with Reinforcement Feedback Training): 结合了硬件在环(HIL)测试和 RL 的控制方法, 旨在优化复杂系统的控制策略, HIL 测试允许在真实硬件上进行控制算法的验证和优化, 通过将模拟环境与实际硬件连接, 确保控制系统在真实条件下的有效性, 结合强化学习的反馈机制, HIL-ConRFT 可以根据系统的表现持续优化控制策略。通过从环境中获取奖励信号, 系统能够学习最佳操作策略HIL-SERL(Hardware-in-the-Loop Sample-Efficient Reinforcement Learning): 是一种结合了硬件在环(HIL)测试和样本高效强化学习(Sample-Efficient Reinforcement Learning)的框架, 旨在优化机器人和自动化系统的控制策略SFT(Supervised Fine-Tuning): 通常用于在预训练模型的基础上进行进一步的监督学习, 模型首先在大规模数据集上进行预训练, 以学习通用的特征和表示。然后, 在特定任务的数据集上进行微调, 使模型能够针对特定任务进行优化
VLA 的特点
- 多模态:
- Shared Embedding Space: 视觉, 文字信息会被一起嵌入一个共享的语义对齐空间, 这个共享的语义空间能减少转码过程的损失, 提供更好的推理能力, 理解能力
- Multimodal Token-Level Integration: 通过 transformer 可以将连续的视觉文字等信息转化为离散序列, 提供了对这些不同类型的信息的综合性理解能力, 减少语义转化损失
- Comprehensive Modal Compatibility: 得益于强大的 VLM, VLA 天生有着与具体模态无关的语义对齐能力, 新的传感器信息, 例如声音, 点云等信息都可以在不影响主干网络的情况下加入
- Instruction Following
- Semantic Instruction Grounding
- Task Decomposition and Collaboration
- Explicit Reasoning via Chain-of-Thought: 链式的思考能力能让 VLA 能一定程度上预测未来的图像, 减少了短视现象
- Multi-Dimensional Generalization
- Cross-Task Generalization: 相比传统模型任务特化的训练过程, 很多 VLA 模型有着 zero-shot 或者 few-shot 级别的泛化能力, 有时可以直接用到没有特别训练的领域
- Cross-Domain Data Generalization: 相比传统模型, 多模态的 VLA 可以接受各种各样的数据, 从而得到相应的泛化能力
- Cross-Embodiment and Sim-to-Real Generalization: 由于现代 VLA 的解耦性质, 其经过抽象的规划起和底层动作解码器可以互相解耦, 也就是不同的机器人形态也可以被泛化
数据集和基准测试
- 真实世界机器人数据集: 尽管理论上讲真实世界是检验以及训练的最好数据, 但由于条件限制, 往往不够全面或者丰富
- 模拟数据集: 其优点是可以针对想要特化的能力调整模拟环境, 而缺点则是相比现实可能有较大差距, 导致可迁移不足
- 人类行为数据集: 对一些特定任务, 例如物体识别, 任务分解等较为实用
- 具身数据集: 强调主动感知, 推理和执行, 提供严格的协议来评估通用 VLA 中的高级语义规划
总结和展望
- 数据集和基准测试: 当前的真实数据稀少, 模拟环境存在缺陷, 可能需要更好的结合方法; 基准测试需要增加长期性, 且更丰富的指标
- 记忆机制和长期规划: 大多数当前的 VLAs 依赖于逐帧推理, 产生了短视问题, 需要增加记忆以及未来预测能力
- 3D&4D 感知: 当前的主要输入形式依旧是 2d 图片, 如果能增加输入维度(空间与时间维度)或许能增强模型能力
- 移动操纵: 鉴于现实任务特点, 导航能力和交互能力应该更加集成
- 多代理合作: 现实有很多协作任务, 且增加代理数量可以更灵活地划分子任务
- 开放世界终身学习: 大部分 VLA 模型基于静态数据集, 由于硬件以及当前软件性质难以长期积累知识
- 模型效率: 在机器人平台的性能往往受限, 因此需要平衡存储, 计算成本与模型表现
π0: A Vision-Language-Action Flow Model for General Robot Control
VLM 大模型的发展, 不仅在通用能力上取得了进步, 同时由于海量数据带来的能力, 在一些专业任务上也有应用空间
来到 VLA 领域, 想要融合 VLM 并得到一定的行动能力, 有几个挑战:
- 这样的研究需要很大规模的数据和训练
- 需要能有效从海量数据中学习的模型架构
- 需要正确的训练技巧
π0 正是为了解决这三个问题的原型模型, 相比其他系统, 其技术特点:
- 跨实体地进行训练
- 为了提供对复杂动作的生成能力使用动作块体系和流匹配方法
最近涌现出一批高质量数据集(关于机器人控制), 但往往总共的时长规模在 10h 左右甚至更少, 而为了尽可能地获取综合能力, 本文使用量 10kh 的演示数据(由研究者自己的数据和一些开源数据补充组成), 除了数量以外, 在涉及机器人的种类、任务类别数、标注数外规模也较大
与其他领域的大模型一样, 极大规模的输入也产生了极强的效果
- Broad Generalization: 一个模型或系统在面对新数据或未见过的任务时, 能够有效地适应和推理的能力。这种概念通常在机器学习和人工智能领域讨论, 特别是在评估模型的泛化能力时
模型介绍
其主干可以说是一个基于 tf 的视觉模型, 将图像输入编码嵌入到语言空间, 但正如很多动作模型一样, 出于任务考虑输入输出数据会增加机器人感知与动作
模型使用条件流匹配(之前写的 介绍博文)来对连续的动作分布建模
模型不依赖特定的 VLM, 为了方便实验中使用 PaliGemma
受一个叫 transfusion 的模型(用一个 tf 处理不同类型的输出, 对连续输出使用流匹配的损失函数, 对离散输出使用交叉熵的损失函数)启发, 基于 transfusion, 在工程上(高情商说法), 发现机器人特有的 token 上(即动作与状态), 应用特定的权重集合能提高表现
作为一个生成任务, 技术上具体可以描述为对分布 \(p(A_t|o_t)\) 建模, 其中 At 是从 t 下标开始, 长度为 H 的动作序列(动作块), 文中的 H 为 50, 而观察 o 由 RGB 图像、语言指令和机器人状态(关节角度)组成分别用 I, l, q 表示
虽然输入类别有很多, 但 I, q 都会由编码器以及一个线性投影层投影到 l 的嵌入空间
将损失函数定义为:
\[L^{\tau}(\theta)=\mathbb{E}_{p(\mathbf{A}_{t}|o_{t}),q(\mathbf{A}_{t}^{\tau}|\mathbf{A}_{t})}||\mathbf{v}\theta(\mathbf{A}_{t}^{\tau},\mathbf{o}_{t})-\mathbf{u}(\mathbf{A}_{t}^{\tau}|\mathbf{A}_{t})||^{2}\]
其中上标是流匹配的时间步, 下标则是机器人的时间步, \(\tau\ \in\ [0,1]\) , 训练时从标准正态分布中采样一个 \(\epsilon\) , 令噪声行动 \(A_t^\tau = \tau A_t + (1-\tau ) \epsilon\) , 训练目标是让 \(\mathbf{v}\theta(\mathbf{A}_{t}^{\tau},\mathbf{o}_{t})\) 与去噪向量场 \(\mathbf{u}(\mathbf{A}_{t}^{\tau}|\mathbf{A}_{t}) = \epsilon - A_t\) 匹配, 初始动作输入是一个从标准正态分布中取样的噪声动作
这里先不讨论太多细节, 整体上这是比较标准的条件流匹配方法, 只不过学习的不是直接的动作输出, 而是如何对输入降噪, 最后我们得到的其实是一个和定义出来的降噪向量场尽可能接近的一个基于模型参数的向量场 v
得到向量场后, 推断过程就是做一个积分: \({\bf A}_{t}^{\tau+\delta}={\bf A}_{t}^{\tau}+\delta{\bf v}_{\theta}({\bf A}_{t}^{\tau},{\bf o}_{t})\)
其中 $ $ 是积分的步长, 这里设 0.1, 由于 $ $ 范围是 [0,1], 这就意味着一共积分 10 次
由于作者是企业, π0 其实算是一篇技术介绍或者说报告, 原理写得很简略, 后文会结合其他资料阐述 类似 LLM, 本文也将模型分为两个阶段, 预训练阶段让模型尽可能获得泛化能力(包括对物理任务的泛化), 后训练阶段则让模型流畅地执行下游任务
训练与实验
数据上, 正如前文所说, π0 使用了一组庞大的数据集, 包括一些开源数据与自己的数据, 且与以往数据不同的是, 自己的数据部分复杂度较高, 可以视为一些行为的组合
由于数据组成较为复杂, 因此对不同的数据集来源进行加权, 动作和状态向量(a, q)按最复杂的机器人设置, 对更简单的机器人, 则填零或者掩盖(mask out)掉缺失的维度
此外一个常见的思路是将复杂的任务分解为简单的任务组合, 由于 VLM 赋予了语言能力, π0 可以实现这种程度的语义推断
进一步的实验中, 为了评估语言能力, 对指令进行划分, 只接受整体性指令的模型表现最差, 而接受人类指令和高级 VLM 指令的模型互有胜负, 比没有任务分解的表现好一个阶层
论文还比较了 π0 的无预训练版本和预训练版本以及其他模型(包括这篇博文写过的 ACT), 较为符合常识的是, 对任务类型相似的任务, 预训练能带来更大提升, 但对其他模型, 往往直接从头开始面向任务训练的模型表现最好; 有些不不符合常识的是, 部分任务训练时间更长的版本表会更差(但降幅不高)
最后的实验针对最为复杂的任务, 例如兼顾移动与操控, 对这种任务, 往往预训练并微调后的模型有相当好表现, 有时能成倍于从头训练版本和 zero-shot 版本
细节
前置知识: flow matching
参考 :
这部分解释一些技术细节:
先放一张架构图
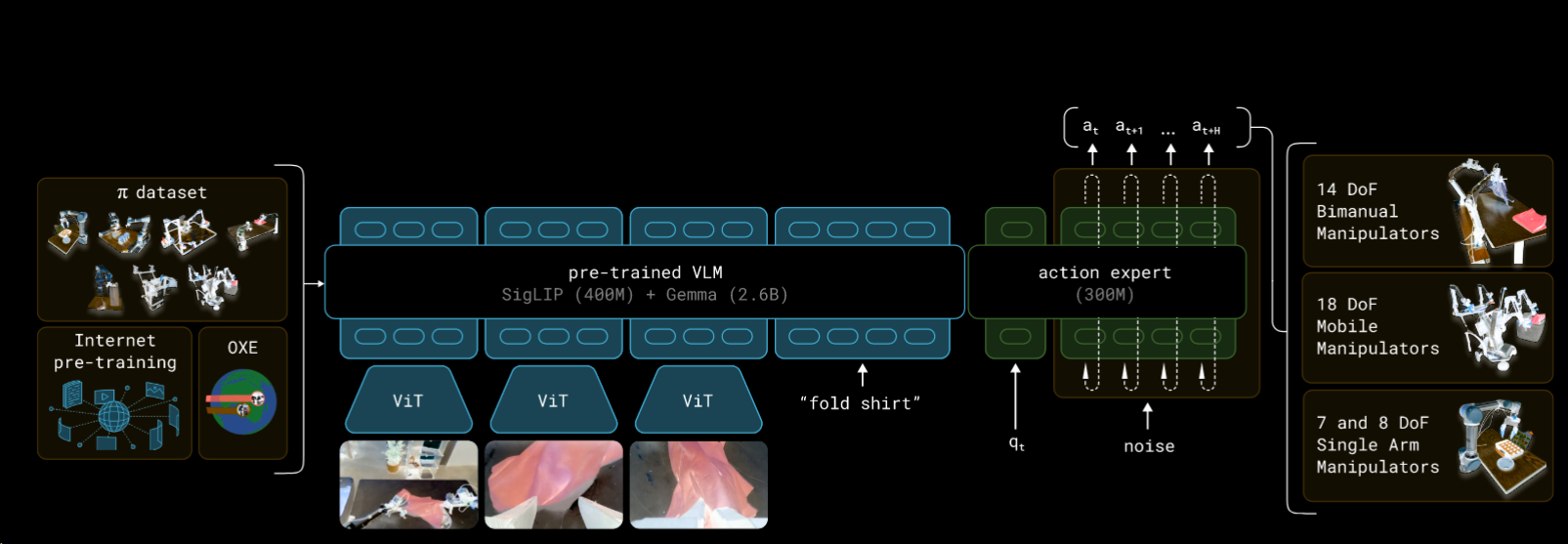
π0 将输入分为 3 个 block, 分别是 图像与文字指令、机器人状态、动作, 第一个 block 由 VLM 处理, 后两个交给动作专家
从 VLM 部分说起, 先简单地对图像处理为 token, 将图像 token 和文字 token 拼接, 交给注意力来计算 kvq, 这是个很简单的处理, 需要注意的是为了提高效率这里的 kv 之后会复用
然后是较为关键的动作专家, 机器人状态是一种很单纯的输入不需要额外处理, 而对(噪声化的)动作, 因为动作是有序的, 需要编码时间步信息(使用正弦编码), 这里不是常见的相加, 而是使用拼接(concat), 最后会得到两倍宽度的一个序列, 然后在经过线性层和激活函数得到最后的 action tokens
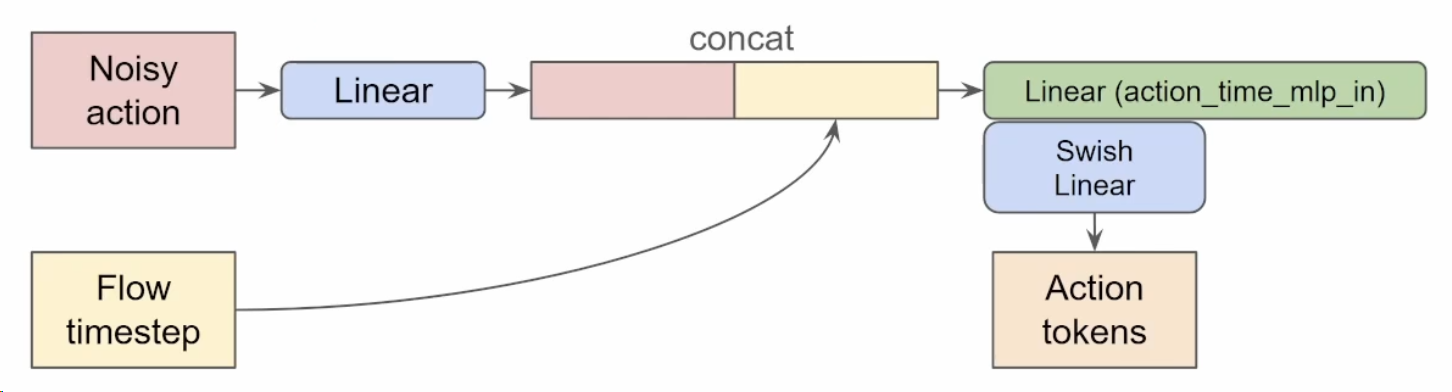
现在我们有了三种输入, 符合常识地, 他们之间存在顺序关系(图文-> 状态-> 动作), 后面的可以“注意”前面的数据(如果长度不够就 padding 0), 这种注意力关系会用 mask 实现, 且使用之前的 kv cache
所有这些信息最后喂给动作专家(一个较小的 VLM), 但沿用的 kv-cache 来自最初的大型 VLM, 结果投影至动作空间, 也就是流匹配的向量 v
那么 π0 使用的流匹配具体是怎样的呢, 作者根据先前研究的经验使用简单的线性高斯, 即 \[ q(\mathbf{A}_{t}^{\tau}|\mathbf{A}_{t})={\mathcal{N}}(\tau\mathbf{A}_{t},(1-\tau)\mathbf{I}) ; \mathrm{A}_{t}^{\tau}=\tau\mathrm{A}_{t}+(1- \tau )\epsilon \]
而 \(\mathbf{u}(\mathsf{A}_{t}^{\mathsf{\tau}}|\mathsf{A}_{t})\ =\ \mathsf{\epsilon}-\ A_{t}\) 此外, \(\tau\) 来自于 β 采样
简单回顾一下流匹配, 它的概率路径应该有的性质:
- t = 0 时, p(x|x1)服从一个标准正态分布
- t = 1 时, p(x|x1)服从一个均值 x1, 方差较小的正态分布
上面提到的 t 其实对应本文的 \(\tau\), 确实是满足条件的, 而这个 u 也很直观, 既然对原来的 At 加上噪声(动作噪声同系数, 动作正噪声负), 那么去噪过程就是噪声减去动作, 也就是噪声如何还原动作
实例
OpenIN
本文提出了一种「开放词汇、实例导向」的导航系统, 该系统「支持多模态和多类型对象导航指令」, 能够实现对 位置可变日常实例 的有效导航
OpenIN 的框架和大部分系统比较类似, 都可以分为场景图构建以及图更新(包括导航)两个主要模块
CRSG
具体而言, 本系统的地图称为载体关系场景图(CRSG), 它基于一个开放词汇实例图 M, 结构上分为 建筑与房间层、载体层、承载层和其他对象层位移对象导航策略
本系统特殊之处在于, 输入是多模态的, 即可以是文本、图像的任意组合:
- 对图像输入: 使用大语言模型获取文本描述
- 对文本输入以及图像的文本描述: 使用 SBERT 对其编码, 与 CRSG 对象的特征比较余弦相似度, 最高者作为模板对象 Ot
确定目标后, 以 MDP 模型定义探索过程:
定义状态空间: \(S_{t}=(L_{t},C R_{t},C T_{t},F_{t})\) 其中 L 为机器人位姿, CR 是未探索的载体层对象集合, CT 为未探索载体层对象上的候选目标对象集合, F 是一个表示是否找到目标的布尔值, 对初始状态 CR0= 载体层对象全集, CT0 是上一轮选择的候选对象 Ot
定义动作空间: \(A=S t o p,E x p l o r e(c r),G o t o(c t)|c r\in C R_{t},c t\in C T_{t}\) 其中 stop 表示任务完成或者所有载体对象已探索, explore 表示探索载体层对象, goto 表示导航到 ct 的位置
定义策略(以下省略下标 t, 用伪代码表示):
1. if F ==1 CR == \(\emptyset\) then a = stop
2. if F == 0 && \(CT_t !=\emptyset\) , CT.sort(by priority); SS = similarity(CT, O) ;
3. Depth = distance(L, CT); D' = mean(distance(camera, CT));
4. \(P_{-}R(O_{t j})=\omega_{r}\cdot\frac{\omega_{1}s s_{t j}\cdot f(\bar{d}_{t j})}{1\ +\omega_{2}d_{t j}}\) (priority of \(O_{tj}\) in CT)
5. if F == 0 && $CT ==$ && $ CR!=$ then (CR.description, O.image, O.image_description) -> LLM -> $cr_k CR_t $ ( \(cr_k\) is best target )
6. \(a_t\) = Explore( \(cr_k\) ); excute( \(a_t\) )
7. if \(a_t\) == Explore(cr) || \(a_t\) == Goto(ct) then while moving: \(CR_{observed}\) = observed objects which don't include candidates in the radial r ; \(CR_{new}\) = new candidates in unexplored CT objects $
总结: 每轮中在候选对象里优先级排序, 对最佳候选对象的位置, 机器人导航到此处并探索是否存在目标对象; 如果没有候选对象但有为探索载体对象, 让 llm 选一个候选者进行探索; 在探索过程中, 机器人会不断更新 map 且寻找新的候选对象或者载体对象
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
精细的操控任务例如扎电线、将电池插入槽中, 往往需要较大的计算成本或者高端的硬件设备, 而想要落实应用, 成本控制是非常重要的, 因此需要找到在有限的预算下实现精细操作的智能
本文基于端到端的模仿学习, 训练数据也完全来自于现实的演示, 在高精度任务中, 模仿学习的缺点是对策略错误较为敏感, 且人类演示数据相差较大, 不便于学习; 为此, 本文提出了一种 Action Chunking with Transformers (ACT) 算法, 可以通过低成本地通过动作序列学习, 并得到不错的准确率
前言
举一个生活中的例子, 例如打开一个有盖的杯子, 这就需要一只手(假设为右手)握住杯子, 倾斜让左手靠近杯盖, 然后辨别出杯盖边缘, 让左手轻轻掀起; 这种任务对 ai 来说相当精细
由于需要在有限的成本内完成精细任务, 我们选择端到端的模型, 使用低成本的摄像头 rgb 图像作为输入, 让模型只学习操作策略而无需对整个环境建模(当然对这种复杂任务建模也非常难, 例如在电子游戏界, 几乎没有游戏能做好吃饭等人物的日常动画)
以下简述本文使用的一些技术:
- 远程操控(tleoperation): 使用两只大致相同的低成本机械臂, 共用一个空间地图, 使用一下些 3d 打印组件来增强反向驱动, 总预算控制在 $20k 内
- 模仿学习算法: 为了避免模仿学习常见的累积误差问题, 参考心理学的
动作块, 让学习策略预测接下来 k 步的一连串动作, 防止某个错误的一步影响后面的推理; 且能减少一些不相干因素的影响, 例如演示中的部分暂停- 为了提高策略的平滑度, 设置了
temporal ensembling机制, 更频繁地查询策略, 且将重叠的动作块取平均值 - 使用 Transformers 处理动作块(序列数据)
- 为了提高策略的平滑度, 设置了
Backdriving: 在机械和控制系统中使用的术语, 通常指的是在某些系统中, 外部力或运动驱动系统的运动, 而不是通过其内部控制机制来实现, 也就是正向驱动是电机驱动机械装置, 反向驱动则可以是相对机械的外力——比如人力也可以驱动机械臂compounding error(累积误差): 指在(模仿)学习过程中, 由于对错误示范的逐步复制和执行, 错误逐渐积累, 从而影响系统的整体表现action chunking: 心理学术语, 将一系列动作或行为组合成一个更大、更有意义的单元(或“块”), 以提高任务执行的效率和流畅性
real work
Behavioral cloning
行为克隆是最简单的模仿学习方法, 但很明显也有非常多的问题, 例如之前提及的累积误差, 应该解决思路是使用额外的在线学习或者额外标注来更正, 但对低成本硬件的远程操纵常见, 难以适用
如果常识在数据集加入噪声, 很可能会直接让训练失败, 又或者离线地生成校正数据, 但这种方法这在部分场景有效
出于对以上过往问题的考虑, 本文引入了动作块机制实体机器介绍
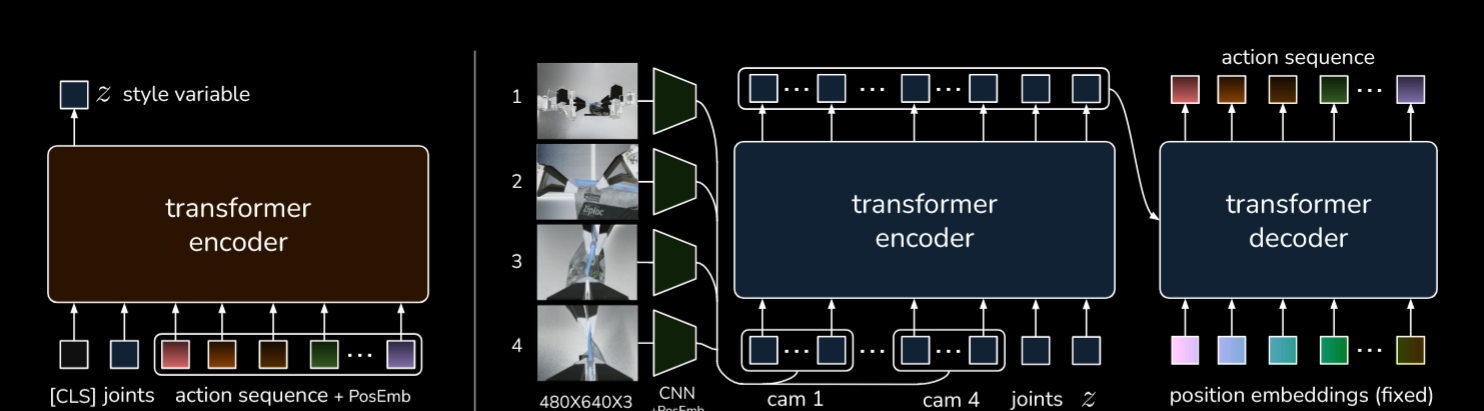
如前文介绍, 本文的技术选择准则可以概括为“物美价廉”, 两个机械臂控制在数千美元, 本文使用的ViperX arm有 750g 的负重能力,1.5m 的宽度, 5-8mm 的准确度, 其关键电机可替换, 但手指对复杂任务不够适用, 为此 3d 打印了一些手指, 并用 Grip tape(握把胶带)缠一圈来提高抓取能力(it just works!)
接下来要选择远程操作系统, 市面上一些常见的系统通过 vr 或者摄像头捕捉手臂姿势来操纵机械臂, 这称为task-space mapping, 本文使用WidowX一种让用户通过反向驱动 "leader"(一个更小的机器部件)来驱动机械臂("follower")的系统, 这称为joint-space mapping
为什么选择这种系统:- 系统中的机械臂有 6 个自由度且没有冗余, 如果使用反向运动学, 很容易陷入起一点
- 共用空间减少计算消耗和延迟
- leader 的重量防止用户动作过快且相比 VR 控制器减少振动
除此之外, 系统做了一些改造减少 leader 的耗力, 详见官网
这个机器系统称为 ALOHA
- ACT 理论部分
ACT 系统可以视为一种有条件(conditional)的 VAE(之前写的 介绍博文), 其编码器将动作序列和关节位置作为观察结果(输入数据)编码为 z(测试时会丢弃编码器), tf 部分的编码器接受所有相机输入、关节位置以及 z, 其解码器生成一个动作序列
实操中, 让操作员操作 leader 机器人(leader 由于要人类操纵, 规格与 follower 不同, 两者的动作参数之间可以隐式转换), ACT 不断预测人类操作员在给定观察下的未来 k 步操作
这样有个额外的好处, 由于学习的样本是人类提供的行为, 而这种行为不一定是符合马尔科夫假设的, 单步学习很可能会被暂停之类的行为误导, 而如果误导行为集中在一个动作块中, 对训练的损害则不会那么巨大
但相应的, 由于每 k 步切换, 可能过程不会太平滑, 因此在每步都会查询策略, 类似滑动窗口, 这样依赖每次预测的动作块都会有部分重叠, 因此为了充分利用这些信息, 对未来时刻的所有预测动作, 计算一个加权和, 这个过程称为 temporal ensembling, 实验发现这样的聚合效果要好于传统的对于时间上相邻动作动作的平滑化, 这部分机制会在下文详细讨论
接下来阐释对输入的处理:
- 我们用 CVAE 处理人类输入, 它由一个编码器和一个解码器组成, 解码器会预测 z 的均值与方差, 用作对角高斯分布, 也就是根据输入数据拟合一个高斯分布
- 出于训练速度考虑, 对输入数据, 不使用图像观察结果, 只用机器人的本体感知数据(例如姿势, 角度等)
- 解码器则会使用 z 以及当前观察结果(图像+关节位置)预测未来的动作序列
- 测试时, 设 z 为先验分布(给定)的均值, 如果想要确定性地解码, 可以直接设 0(注意是测试时这么做)
- 训练的过程中不断地最大化模型输出与演示数据里的相同动作块的对数概率; 同时也使用标准 VAE 的两个标准(重建损失与正则化项), 对正则化项, 乘以一个超参数 β(用于控制 z 包含的信息量, 更高的正则化会导致更少的信息转入 z)
具体实现:

- 使用 tf 作为编码和解码器, 具体来说, CVAE 的编码器类似 BERT, 其输入是当前关节位置以及长度为 k 的演示动作序列, 同样类似 BERT, 每段序列会有个
CLS前缀, 具体见上图左侧部分 - CVAE 解码器实际上更为复杂, 由
ResNet image encoders, a transformer encoder, a transformer decoder组成, 接受的输入也比编码器更多, 其动作空间是机器人的所有关键位置也就是一个 14 维向量(一只手对应 7 维), 大致过程如下- resnet 的编码器将图像输入转化为特征地图, 再被展平(flatten)为序列(另外使用正弦位置编码保存空间关系)
- 处理完图像后, 特征数据以及关节位置, z 作为输入通过一个线性层投影到一个向量组, 其向量数为 k
- 得益于前一步中得到的固定长度的向量组, tf 解码器通过 cross-attention 产生相同长度的输出组, 然后在经过 MLP(多层感知机)的投影为 14 长度的动作向量组
神奇的是, 用 L1 损失作为重建损失的表现更好, 此外用 delta joint position(关节变化量)训练效果不如目标位置
- 逆向运动学(Inverse Kinematics, IK): 运动学(Kinematics)是在给定所有关节角度的情况下计算链接结构(如一节人体的关节)的末端的空间位置的过程; 逆向运动学则相反, 知道末端状态, 需要求解关节应该是什么角度
- 奇异点(singularities): 机器人在某些特定配置下失去自由度或控制能力的状态。在这些状态下, 机器人可能无法有效地执行运动或控制其末端执行器的位置和姿态
- 变分自编码器(Variational Autoencoder, VAE): 一种生成模型, 结合了神经网络和贝叶斯推断的思想, 广泛应用于无监督学习、数据生成和特征学习
- 风格变量(Style Variable): 生成模型中, 用于控制输出样本风格或特征的潜在变量, 能够影响生成内容的“风格”而不改变其“内容”
实验与总结
由于此部分大多是现实情况的细节, 省略这些部分, 只说结果
ACT 主要创新点在于能够预测连续的, 精确的动作序列, 而一些先前的模仿学习方法只能像分类问题一样预测离散动作, 此外端到端的训练方式对特化的任务可能有更好的效果
消融实验中, CVAE, 动作块等机制都较为有效
相比先前方法, ACT 大部分任务都取得了更好的表现, 但是会在对比度低图像难以捕捉特征的场景表现不佳