基于伯克利Sysadmin decal的linux笔记
shell脚本
Shell 脚本通常以 shebang 行开头:#!path/to/interpreter。
#!是一个人类可读的 幻数表示 0x23 0x21它可以告诉 shell 将文件其余部分的执行传递给 指定翻译。 如果您的脚本作为可执行文件运行(例如 ./awesome_shell_script) 加上 shebang 行,那么 shell 将调用 可执行文件(通常是解释器)位于 path/to/interpreter运行你的 脚本。 如果您的脚本作为参数传递给解释器,例如 bash awesome_shell_script,那么 shebang 没有效果并且 bash会处理 脚本的执行。 为什么这很重要? shebang 可以被认为是一个有用的部分 执行脚本的关注 如何 元数据传递了用户 给程序的作者。 awesome_shell_script可能是一个 bash脚本,一个 python脚本,一个 ruby脚本等。这个想法是只有脚本的 对于调用的用户来说,行为而不是其实现细节应该重要。
您可能已经看到过一些变体 #!/bin/sh。 虽然最初参考的是 现代系统上的 Bourne shell sh已经提到了 Shell Command Language ,这是一个具有多种实现的 POSIX 规范。 sh通常符号链接到这些符合 POSIX 标准的 shell 之一 实现 Shell 命令语言。 以 Debian 为例, sh是 符号链接到 shell dash。 重要的是要注意 bash不 **_** 遵守这个标准,虽然运行 bash作为 bash --posix做到了 更合规。
管道
我们可以使用 |字符将多个命令链接在一行中。 例如: command1 | command2 将传递的输出 command1作为输入 command2。 我们可以根据需要多次重复此操作。
循环使用 for
Bash 可以使用 for 循环对多个对象重复操作。 语法如下:
1 | for VARIABLE in LIST; do |
缩进不是必需的,但使代码更易于阅读。 这 LIST可以是包含多个文件的目录,也可以是包含多行 init 的文件、文件列表( file1 file2 file3),甚至是一系列数字( {start..end}).
有用的命令
一些对于完成实验可能有用的命令。 当然,解决问题的方法有很多,并不需要使用这些命令。
cat
cat 打印 将文件 到标准输出 。 对于打印一些内容以通过管道输入其他命令非常有用!
cut
cut [options] [filename]提取文件的某些部分(或管道输入) 参数 根据使用的 。 一些可能有用的:
-d允许我们更改分隔符,或更改字符 cut寻找将字符串分成块。 如果省略该选项, tab用来。
-f允许我们指定与要返回的字段对应的数字,例如 cut -f1 -d" "将返回句子中的第一个单词。 数字后跟一个 -也返回指定字段之后的所有字段,因此 cut -f1- -d" "将返回整个字符串。
--complement告诉 cut返回除 之外的所有内容。 指定字段
grep
grep [pattern] [filename] 过滤 并返回文件(或管道输入)中包含指定模式的行。
sed
sed可以做 很多事情 ,比如编辑字符串和匹配正则表达式。 我们可以用 sed将一种模式替换为另一种模式,如下所示:
sed 's/<PATTERN-TO-REPLACE>/<NEW-PATTERN>/g <INPUT>'
sed` 还可以从其他东西获取管道输入,而不是显式输入。
这 g最后告诉 sed替换所有出现的模式; 如果我们只想替换模式的第一次出现,则可以省略它,或者用数字替换以仅替换一定次数的出现。
xargs
xargs让我们将命令应用于从管道重定向的输出。 例如, output | xargs command会适用 command到 output。 一些有用的 选项 :
-n1告诉 xargs将命令应用到中的每个项目 output如果输出中有多个项目(例如多个字符串的列表),则一次
-0告诉 xargs用空字符(表示字符串的结尾)分割输出中的项目,而不是使用空格。 搭配 -n1, 这意味着 xargs会将命令应用于每个字符串,而不是将字符串分解为单个单词并将命令应用于每个单词。
与往常一样,有更多方法可以使用这些命令,因此请使用 Google 或 手册页 来了解更多信息
语法
Shell 变量和类型
与大多数其他编程语言一样, bash促进有状态分配 名称到值作为变量。
变量可以被赋值 bash语法如下: NAME=value。 请注意 赋值运算符之间缺少空格 =及其操作数。 任务 对空格敏感。
您可以通过在前面添加一个来检索变量的值 $以它的名字。 获取值 NAME必须完成 $NAME。 这就是所谓的变量 插值。
1 | $ NAME = "Tux" # Incorrect |
$?保存最近执行的命令的退出代码。 在这个 上下文、退出代码 0一般表示程序已经执行 成功地。 其他 退出代码 指的是错误的性质 导致程序失败。
特殊 位置参数 允许将参数传递到脚本中。 $0是脚本的名称, $1是传递给的第一个参数 脚本, $2是传递给脚本的第二个参数, $3是第三个 论证等 $#给出传递给脚本的参数数量。
所以 ./awesome_shell_script foo bar可以访问 foo从 $1和 bar从 $2.
Bash 变量是 无类型的 。 它们通常被视为文本(字符串),但是 如果变量包含数字和算术运算,则可以将其视为数字 对其应用操作。 请注意,这与大多数编程不同 语言。 变量 本身没有类型,但 运算符 会处理 在不同的环境下他们的价值观也不同。 换句话说, bash变量是文本,没有任何固有的行为或属性 可以操作的文本,但操作员会解释该文本 根据其内容(数字或无数字?)和上下文 表达。
算术
Bash 支持整数算术 let内置。
1 | $ x=1+1 |
注意 let对空格敏感。 操作数和运算符不得 用空格分隔。
bash本身不支持浮点运算,所以我们必须依赖 如果我们想处理十进制数字,请使用外部实用程序。 一个常见的选择 这是 bc。 有趣的事实: bc实际上是它自己的完整语言!
我们经常访问 bc通过 管道 (表示为 |),这允许 将一个命令的输出用作另一命令的输入。 我们包括 -l 选项 bc为了启用浮点运算。
1 | $ echo 1/2 | bc -l |
test
Bash 脚本经常使用 [(同义词为 test) shell 内置的 表达式的条件评估。 test计算一个表达式并 以任一状态代码退出 0(true) 或状态代码 1(错误的)。
test支持常见的字符串和数字运算符,以及许多 额外的二元和一元运算符在大多数情况下没有直接类似物 其他编程语言。 您可以看到这些运算符的列表,以及 其他有用的信息,通过输入 help test在你的壳里。 的输出 如下所示。 注意 help类似于 man,除非它用于 bash 函数而不是其他程序。
1 | $ help test |
我们可以测试整数相等
1 | $ [ 0 -eq 0 ]; echo $? # exit code 0 means true |
字符串相等
1 | $ [ zero = zero ]; echo $? # exit code 0 means true |
以及您可以自由进行的许多其他字符串和数字运算 探索。
控制结构
bash包括大多数编程语言典型的控制结构 – if-then-elif-else, while for-in等等。您可以阅读更多有关 条件语句 和 迭代 中的 Bash 指南 初学者 Linux 文档项目 (LDP) 的 。 我们鼓励您 请阅读这些部分,因为本指南仅提供了一些内容的简短摘要 重要特征。
if-then-elif-else
if 语句的一般形式 bash是
1 | if TEST-COMMANDS; then |
缩进是一种很好的做法,但不是必需的。
例如,如果我们写
1 | #!/bin/bash |
我们看
1 | $ ./awesome_shell_script 0 0 |
尽管
while 循环的一般形式 bash是
1 | while TEST-COMMANDS; do |
如果 TEST-COMMANDS退出并带有状态码 0, CONSEQUENT-COMMANDS将要 执行。 这些步骤将重复,直到 TEST-COMMANDS退出时带有一些非零值 地位。
例如,如果我们写
1 | #!/bin/bash |
我们看
1 | $ ./awesome_shell_script 5 |
函数
bash supports functions, albeit in a crippled form relative to many other languages. Some notable differences include:
- 函数不 返回 任何内容,它们只是产生输出流(例如
echo到标准输出) bash严格来说是按值调用。 也就是说,只有原子值(字符串)可以 被传递到函数中。- 变量没有词法作用域。
bash使用一个非常简单的本地系统 范围接近动态范围。 bash没有一流的函数(即没有将函数传递给 其他函数)、匿名函数或闭包。
功能于 bash定义为
1 | name_of_function() { |
并由
1 | name_of_function $arg1 $arg2 ... $argN |
请注意函数签名中缺少参数。 参数在 bash 函数的处理方式与全局位置参数类似,其中 $1 含有 $arg1, $2含有 $arg2, ETC。
例如,如果我们写
1 | #!/bin/bash |
我们看
1 | $ ./awesome_shell_script world |
实例
斐波那契
1 | #!/bin/bash |
1 | read -p “send: ” FOO |
Bash 支持整数算术 let内置的。
1 | $ x=1+1 |
注意 let对空格敏感。 操作数和运算符不得 用空格分隔。 test计算一个表达式并 以任一状态代码退出 0(true) 或状态代码 1(错误的)
bash支持函数,尽管相对于许多其他函数而言,其形式有缺陷 语言。 一些显着的差异包括:
- 函数不 返回 任何内容,它们只是产生输出流(例如
echo到标准输出) bash严格来说是按值调用。 也就是说,只有原子值(字符串)可以 被传递到函数中。- 变量没有词法作用域。
bash使用一个非常简单的本地系统 范围接近动态范围。 bash没有一流的函数(即没有将函数传递给 其他函数)、匿名函数或闭包
请注意函数签名中缺少参数。 参数在 bash 函数的处理方式与全局位置参数类似,其中 $1 含有 $arg1, $2含有 $arg2, ETC。
例如,如果我们写
1 | #!/bin/bash |
我们看
1 | $ ./awesome_shell_script world |
shell命令
SSH(安全外壳)
SSH 允许您通过互联网登录远程计算机。 这相当于在远程计算机上打开 shell。
用法是 ssh [remote username]@[remote host].
问题
- 登录到
tsunami.ocf.berkeley.edu使用您的 OCF 用户名和密码。 有一个文件在~staff/public_html/decal。 打开它。 文件中到底隐藏着什么秘密?
管道和重定向
将命令链接在一起对于自动化 shell 操作至关重要。 这是一个快速备忘单:
>:将 标准 输出重定向到文件(将覆盖该文件)。
>>:将标准输出附加到文件(与 >除非不覆盖)。
<:从文件中读取输入。
|:将一个程序的输出发送到下一个程序的输入。
下面是一个示例:假设您正在参加一门课程,需要您提交一个包含您的 SID 的文本文件。 您的第一反应可能是打开一个文本编辑器(例如 vim)并简单地输入它,但是有一种更快的方法来创建文件! 这里是:
echo '123456789' > sid.txt
tmux
为什么是 tmux?
- 当通过 ssh 连接到一台计算机时,您可以打开多个窗口。
- 您可以在编辑程序的同时对其进行编译和运行。
- 您可以注销并通过 ssh 重新登录,而无需重新打开所有文件。
入门
- 开始会话
tmux. - 从会话中分离
Ctrl-b d(释放后按 dCtrl-b) - 分成 2 个窗格
Ctrl-b %(垂直)或Ctrl-b "(水平的) - 交换当前窗格
Ctrl-b o - 在线查找有关 tmux 的更多信息。 您可能会发现 此备忘单 很有帮助!
包管理
Debian:简介 apt和 dpkg
在本课程中,我们将重点关注 Debian 的使用。 正如本周讲座中提到的,Debian 使用 apt/dpkg 作为其包管理器。 其他发行版使用不同的包管理器。
apt
Debian 的前端包管理器是 apt。 大多数时候,当您需要与包管理器打交道时, apt通常是要走的路。 在做任何事情之前 apt,更新包列表通常是一个好习惯,以便包管理器可以找到并获取各种包的最新版本。 为此,您可以运行:
apt update
要查找要安装的包:
apt search [package|description]
要安装包:
apt install [package]
要删除包:
apt remove [package]
使用安装的软件包一段时间后,您可能会注意到它们不会自动更新,这一功能可能存在于为其他操作系统编写的程序中。 要更新已安装的软件包,请运行:
apt upgrade或有时 apt dist-upgrade
使用起来比较普遍 apt upgrade更新你的包,但有时你需要使用 apt dist-upgrade。 阅读有关两者之间差异的更多信息 您可以在此处 。
在某些情况下,您希望完全确定要安装的软件包的版本。 要列出可以安装的潜在版本,您可以运行:
apt policy [package]
这根据其引脚优先级列出了要安装的候选版本以及与系统兼容的其他版本。 要安装特定目标版本的 aa 版本,您可以运行:
apt -t [targetrelease] install [package]
还有其他命令可以删除不需要的依赖项并清除包,但这就是 man页面是为了。 请注意,您将必须使用 sudo对于上述命令,因为您实际上是在修改系统本身。
dpkg
后端包管理器是 dpkg。 传统上, dpkg用于安装本地软件包。 使用 dpkg,您还可以检查软件包并修复损坏的安装。 要安装本地软件包,请运行:
dpkg -i [packagefilename]
删除系统包:
dpkg --remove [package]
要检查包以获取有关该包的更多信息:
dpkg -I [packagefilename]
要修复/配置所有已解压但未完成的安装:
dpkg --configure -a
入门
创建一个简单的包
现在,我们将使用您将在接下来的步骤中创建的 hellopenguin 可执行文件创建一个简单的包。 首先,移至您在入门部分克隆的存储库中的 a2 文件夹:
cd decal-labs/a2
现在我们将创建一个文件夹来进行此练习:
mkdir ex1
现在进入该文件夹:
cd ex1
编写和编译程序
现在,我们将用 C 语言制作一个非常简单的应用程序,打印“Hello Penguin!” 名为地狱企鹅。 调用:
touch hellopenguin.c
这将创建一个名为的空文件 hellopenguin.c。 现在,使用您选择的首选文本编辑器,例如 vim, emacs, 或者 nano,将以下代码插入 hellopenguin.c
1 | #include <stdio.h> |
我们现在将编译您刚刚编写的源文件:
gcc hellopenguin.c -o hellopenguin
其作用是获取源文件 hellopenguin.c并将其编译为名为的可执行文件 hellopenguin与 -o输出标志。
打包可执行文件
现在,我们将创建可执行文件所在的文件夹结构。在 Debian 中,用户级包通常驻留在该文件夹中 /usr/bin/:
mkdir -p packpenguin/usr/bin
现在移动你编译的 hellopenguin可执行到 packpenguin/usr/bin/文件夹。
mv hellopenguin packpenguin/usr/bin/
现在我们将创建一个名为 hellopenguin。 移动到父目录 packpenguin文件夹并调用以下命令:
fpm -s dir -t deb -n hellopenguin -v 1.0~ocf1 -C packpenguin
这指定您要使用目录 -s标志,并输出 .deb包使用 -t旗帜。 它接受一个名为的目录 packpenguin, 使用 -C标志,并输出 .deb文件名为 hellopenguin, 使用 -n,版本号为 1.0~ocf1, 使用 -v旗帜。
现在通过调用 apt 并安装它来测试它:
sudo dpkg -i ./hellopenguin_1.0~ocf1_amd64.deb
现在你应该能够运行 hellopenguin通过执行以下操作:
hellopenguin
计算机网络
概述
不可否认,互联网是一个重新定义了我们世界的重要系统。 开发网络和允许设备通信的能力对于现代计算机系统至关重要。 本实验将研究计算机网络的基础知识,然后从系统管理员的角度检查网络。
我们将使用网页浏览作为类比来了解网络的基础知识。 当我上网浏览猫的图片时到底会发生什么?
但首先让我们简要了解一下网络的细节。
硬件地址mac
媒体访问控制 (MAC) 地址是唯一分配给网络接口的标识符。 
由于 MAC 地址是唯一的,因此通常称为物理地址。 八位位组通常以十六进制书写并用冒号分隔。 MAC 地址示例是 00:14:22:01:23:45。 请注意,前 3 个八位位组指的是组织唯一标识符 (OUI),它可以帮助识别制造商。 有趣的事实—— 00:14:22以上是 Dell 的 OUI。
ip
IP 地址是识别根据互联网协议连接到网络的设备的方法。 互联网协议有两个版本:IPv4 和 IPv6,它们的地址大小不同。 IPv6 地址示例是 2001:0db8:85a3:0000:0000:8a2e:0370:7334它比 IPv4 地址长得多,例如 127.0.0.1。 由于时间关系,我们只讨论 IPv4,但 IPv6 确实正在取得进展,值得一试!
IPv4 地址为 32 位,即 4 个字节,每个字节由点 (.) 分隔。 IPv4 地址示例是 127.0.0.1。 巧合的是,这个地址被称为环回地址,它映射到您自己机器上的环回接口。 这允许网络应用程序在同一台计算机(在本例中是您的计算机)上运行时相互通信。 但为什么 127.0.0.1并不是 127.0.0.0或者 127.0.0.2?
答案是 127.0.0.1是简单的约定,但从技术上讲,网络块中的任何地址 127.0.0.0/8是一个有效的环回地址。 但网络块到底是什么?
在 IPv4 中,我们可以将地址块划分为子网。 这是以 CIDR 格式编写的。 我们以上面的子网为例 127.0.0.0/8。 斜杠后面的数字 ( /),在本例中为 8,是子网掩码。 这表示网络地址中有多少位,其余位标识网络内的主机。 在这种情况下,网络地址是 127.0.0.0面具是 255.0.0.0。 所以 127.0.0.1将是第一个主机 127.0.0.0/8网络等等。
该图提供了 CIDR 寻址的可视化细分 
ARP
地址解析协议 (ARP) 是用于将 IP 地址解析为 MAC 地址的协议。 为了理解ARP,我们首先讨论发送帧的两种方式,单播和广播。 在第 2 层上下文中,单播帧意味着将该帧发送到一个 MAC 地址。 另一方面,通过将帧发送到广播地址来广播帧意味着该帧应该发送到网络上的每个设备,从而有效地“淹没”本地网络。
例如,让我们想象一个发送者 A,他有 MAC 00:DE:AD:BE:EF:00,广播一条消息,本质上是询问“谁拥有 IP 地址 42.42.42.42请在 00:DE:AD:BE:EF:00 告诉 A”。
如果一台机器B,有MAC 12:34:56:78:9a:bc有IP地址 42.42.42.42他们向发件人发送单播回复,其中包含以下信息“ 12:34:56:78:9a:bc有 42.42.42.42”。 发送方将此信息存储在 arp 表中,因此每当它收到发往机器 B 的数据包时,即目标 IP 地址为 42.42.42.42它将数据包发送到从 B 收到的 MAC。
为了路由 IP 数据包,设备具有所谓的路由表。 路由条目存储在路由表中,它们本质上是告诉设备应如何基于 IP 转发数据包的规则。 路由条目指定子网以及与该条目对应的接口。 设备选择具有最特定于给定数据包的子网的条目,并将其转发出该条目上的接口。
路由表通常也有一个默认网关。 在没有更具体的匹配条目的情况下,这将用作数据包的默认捕获所有内容。
以此路由表为例。
1 | default via 10.0.2.2 dev eth0 |
一个数据包的目的地是 8.8.8.8将从默认网关 eth0 转发出去。 一个数据包的目的地是 10.0.2.1将根据第二个条目从 eth0 转发。 一个数据包的目的地是 10.0.2.254将根据第三个条目从 eth0 转发。 一个数据包的目的地是 192.168.162.254将根据第四个条目从 eth1 转发。
域名
我们已经讨论了 IP 地址以及它们如何通过 IP 与主机进行通信,但是虽然 IP 地址是机器友好的(计算机喜欢数字),但它们并不完全是人类友好的。 记住电话号码已经够难了,记住 32 位 IP 地址也不会更容易。
但我们更容易记住 <www.google.com、www.facebook.com> 或 Coolmath-games.com 等名称。 因此,在这种冲突中,域名系统 (DNS) 诞生了,它是机器友好的 IP 地址和人类友好的域名之间的折衷方案。
DNS 是一个将 google.com 等域名映射到 172.217.6.78。 当您查询 google.com 时,您的计算机会将 google.com 的 DNS 查询发送到 DNS 服务器。 假设配置正确并且 google.com 有一个有效的对应地址,您将收到来自权威服务器的响应,其实质上是“google.com 有 IP 地址” x.x.x.x”.
现在让我们稍微消除一下这个黑魔法……
DNS 记录
DNS 服务器以资源记录 (RR) 的形式存储数据。 资源记录本质上是(名称、值、类型、TTL)的元组。 虽然 DNS 记录的类型多种多样,但我们最关心的是
一条记录 名称 = 主机名 值 = IP 地址
该记录非常简单,包含给定主机名的 IP 地址,本质上是我们最终想要得到的信息。
国民服役记录 名称=域名 值 = 域的 DNS 服务器名称
该记录指向另一个可以为该域提供权威答案的 DNS 服务器。 将此视为将您重定向到另一个名称服务器。
CNAME 记录 名称 = 别名 值=规范名称
这些记录指向给定别名的规范名称,例如 docs.google.com 将是一个仅指向 document.google.com 的别名 尝试 <www.facebook.com>
MX记录 邮件服务使用的记录。
TCP 和 UDP
现在我们将讨论传输层的协议。 这一层最著名的两个协议是传输控制协议(TCP)和用户数据报协议(UDP)。
TCP 是一种面向有状态流的协议,可确保可靠的传输。 可靠的传输本质上保证信息完整且有序地到达目的地。
TCP 是面向连接的协议,这意味着它在发送任何数据之前必须首先建立连接。 此连接交换信息,这是 TCP 用于在其他功能中提供可靠传输的机制。 TCP 连接以 TCP 握手开始。
TCP 握手包括在发送方和接收方之间交换的数据包的 TCP 标头中设置某些标志。 发送方首先发送 SYN(设置了 SYN 标志的数据包)来启动 TCP 连接。 服务器通过发回 SYN-ACK(一个同时设置了 SYN 和 ACK 标志的数据包)来确认此连接请求。 客户端通过向服务器发送一个最终 ACK 来确认这一点,然后建立连接。
TCP 然后开始传输数据,如果数据成功到达连接的另一端,则会发出 ACK。 因此,如果数据丢失、重新排序或损坏,TCP 能够识别这一点并发送重传任何丢失数据的请求。
TCP 也有一个关闭连接的过程。 我们在这里只考虑优雅终止,突然终止有不同的过程,我们不会讨论。 如果您有兴趣,CS168 这里 有一些很棒的材料。 假设机器 A 想关闭与机器 B 的连接。
A 首先发送 FIN。 B 必须通过发送 FIN 和 ACK 进行响应。 如果 B 仅发送 ACK,则连接将持续存在,并且可以发送其他数据,直到发送 FIN。 另一方面,如果 B 准备好关闭连接并且不需要发送额外的数据,则 B 也可以只发送一个同时设置了 FIN 和 ACK 标志的数据包,即 FIN+ACK。发送最后一个 ACK 来表示连接终止。
UDP是无状态无连接协议。 UDP 专注于以数据报的形式发送消息。 无连接 UDP 也不会产生 TCP 握手和终止的开销。 UDP 也不保证可靠传输,因此消息可能会损坏、无序到达或根本不到达。 因此,UDP 有时被称为不可靠数据报协议。
虽然 UDP 不保证可靠传输,但它不会像 TCP 那样遭受建立和关闭连接的开销。 因此,UDP 非常适合我们只想快速发送数据包并且丢失一些数据包也不会造成灾难性后果的使用情况。
此外,与 TCP 相比,发送的每个 UDP 数据报都需要单独接收。 而对于 TCP,您传递的数据流被透明地分成一定数量的发送,并且数据流在另一端透明地重建为一个整体。
端口
广义上讲,端口定义了服务端点——端口标记了流量的入口和出口点。 IP 地址连接主机,而端口则连接在此类主机上运行的进程。 一次只能将一个进程绑定到一个端口。 端口由 16 位数字表示,范围从 0 到 65535。从 0 到 1023 的端口是众所周知的端口,即系统端口。 使用这些端口通常有更严格的要求。 1024 到 49151 是注册端口。 官方 列表 IANA 维护着知名和注册范围的 。 从 49152 到 65535 的其余端口是临时端口,可以根据每个请求动态分配给通信会话。
systemd unit
unit的介绍和写法 Linux 发行版越来越多地采用 systemd初始化系统。 这套功能强大的软件可以管理服务器的许多方面,从服务到安装的设备和系统状态。
在 systemd, A unit指系统知道如何操作和管理的任何资源。 这是主要对象 systemd工具知道如何处理。 这些资源是使用称为单元文件的配置文件定义的。
单位是对象 systemd知道如何管理。 这些基本上是系统资源的标准化表示,可以由守护程序套件管理并由提供的实用程序操作。
单元可以说类似于其他 init 系统中的服务或作业。 然而,单元具有更广泛的定义,因为它们可用于抽象服务、网络资源、设备、文件系统挂载和隔离资源池。 系统的单元文件副本一般保存在 /lib/systemd/system目录。 当软件在系统上安装单元文件时,这是它们默认放置的位置。
存储在此处的单元文件可以在会话期间按需启动和停止。 这将是通用的普通单元文件,通常由上游项目的维护人员编写,应该适用于部署的任何系统 systemd在其标准实施中。 您不应编辑此目录中的文件。 相反,如果有必要,您应该使用另一个单元文件位置来覆盖该文件,该位置将取代该位置中的文件。 正确的方法是创建一个以单元文件命名的目录 .d附加在最后。 所以对于一个叫做 example.service,一个名为 example.service.d可以被创建。 在此目录中,有一个以以下结尾的文件 .conf可用于覆盖或扩展系统单元文件的属性。
大多数单元文件中的第一部分是 [Unit]部分。 这通常用于定义单元的元数据并配置单元与其他单元的关系。
尽管部分顺序并不重要 systemd解析文件时,此部分通常放置在顶部,因为它提供了单元的概述。 您可以在以下位置找到一些常见指令 [Unit]部分是:
Description=:该指令可用于描述单元的名称和基本功能。 它由各种返回systemd工具,因此最好将其设置为简短、具体且信息丰富的内容。Documentation=:该指令提供了文档 URI 列表的位置。 这些可以是内部可用的man页面或网络可访问的 URL。 这systemctl status命令将公开此信息,以便于轻松发现。Requires=:该指令列出了该单元本质上依赖的所有单元。 如果当前单位已激活,则此处列出的单位也必须成功激活,否则该单位将失败。 默认情况下,这些单元与当前单元并行启动。Wants=:该指令类似于Requires=,但不太严格。Systemd当此单元被激活时,将尝试启动此处列出的任何单元。 如果未找到这些单元或无法启动,当前单元将继续运行。 这是配置大多数依赖关系的推荐方法。 同样,这意味着并行激活,除非被其他指令修改。BindsTo=:该指令类似于Requires=,但也会导致当前单元在关联单元终止时停止。Before=:如果同时激活了该指令中列出的单元,则只有当前单元被标记为已启动后,它们才会启动。 这并不意味着依赖关系,并且如果需要的话必须与上述指令之一结合使用。After=:该指令中列出的单元将在启动当前单元之前启动。 这并不意味着依赖关系,如果需要,必须通过上述指令建立依赖关系。Conflicts=:这可用于列出不能与当前单元同时运行的单元。 启动具有这种关系的单元将导致其他单元停止。Condition...=: 有许多指令以Condition这允许管理员在启动设备之前测试某些条件。 这可用于提供仅在适当的系统上运行的通用单元文件。 如果不满足条件,则会正常跳过该单元。Assert...=:类似于以Condition,这些指令检查运行环境的不同方面,以决定是否应激活该单元。 然而,与Condition指令,负结果会导致该指令失败。
安全管理
加密与解密
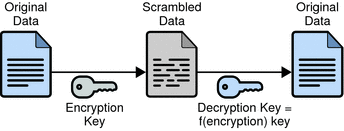
基础知识
加密采用明文和密钥,返回密文。 解密需要密文和密钥,仅当解密密钥有效时才恢复并返回原始明文。 加密和解密的密钥是由随机位组成的长字符串,这使得攻击者在计算上无法猜测密钥并解密密文。
 安全性是指在面对攻击时保持系统按预期运行 这可以采取多种形式:
安全性是指在面对攻击时保持系统按预期运行 这可以采取多种形式:
- 保密性
- 完整性/真实性
- 可用性
模块:
- 认证
- 加密:防止攻击者读取您的文件,直到它们得到 联邦调查局和他们的密码学家参与其中
- 哈希:将大数据转化为小数据
- 签名和证书:确保您就是您所说的人 假设我想使用你的公钥来验证你的身份。 我 可以用它加密一些东西,并要求你解密它并且 显示正确的值。 如果您可以解密该值,那么您必须拥有密钥的私有部分并且可以进行身份验证。 假设你想证明你发送的消息实际上是由您发送。 您可以使用您的私钥来“签署”消息通过对其进行加密,您的公钥可用于解密签名以验证您(由您发布的公开信息识别)键)实际上确实发送了消息,因为只有您而不是其他人对手将拥有相应的私钥。
根证书:操作系统包含许多根证书 这是网络信任的基础。 证书是在通向根的链中签名; 如果链有效,则最后的 cert 被认为是可信的。
网络攻击: 攻击网络系统的方法有很多: 窃听、中间人、拒绝服务、应用程序 缓冲区/堆溢出、SQL 注入等漏洞 目录遍历、CSRF、SSRF、XSS、蠕虫、rootkit、垃圾邮件、加密挖矿、勒索软件、网络钓鱼等等……
对称密码学
在对称密码学中,用于加密和解密的密钥是相同的。
尝试一下:
gpg --symmetric [FILE]在任何文件上输出[FILE].gpg文件是输入文件的加密版本。 加密文件时需要输入密码。gpg --decrypt [FILE].gpg在原始文件的加密版本上,您需要输入原始密码。
在此 GPG 实现中,文件的加密和解密都需要知道单个密码,在本例中该密码充当对称密钥。
非对称密码学
在非对称加密中,两个单独的密钥分别用于加密和解密。 这两个密钥是一对公私密钥。 公钥是公开的并用于加密数据。 而私钥由所有者保密并用于解密数据。 使用公钥加密文件意味着只有拥有相应私钥的人才能解密生成的加密文件。
GPG 钥匙圈抽象
GPG 使用“密钥环”作为集中位置来保存用户的所有密钥。 如果您想使用并保留它,则需要向密钥环添加/导入密钥。 同样,如果您希望与其他人共享密钥,您可以导出您的密钥(这会生成您的密钥的副本)并让他们将其导入到他们的密钥环中。
尝试一下:
gpg --full-generate-key生成 GPG 公私密钥对。 它会要求输入密码。 如果您的机器需要一段时间才能生成密钥,则可能是由于缺乏长随机密钥所需的熵(随机性)。sudo apt-get install haveged将安装一个生成熵的守护进程。gpg --recipient [RECIPIENT] --encrypt [FILE]这将加密[FILE]和[RECIPIENT]的公钥(目前,尝试使用您自己的公钥加密文件)。gpg --decrypt [FILE].gpg将搜索您的密钥环并使用适当的私钥解密文件(当然,如果您拥有正确的私钥)。 您无需指定使用哪个密钥来解密文件,因为 GPG 加密的文件和密钥包含元数据,允许 GPG 从密钥环中选择正确的密钥来解密文件。
签名
公钥加密、私钥解密的非对称方案也可以反过来实现数字签名,其作用相当于物理签名。 在这个相反的方案中,私钥用于对文件进行签名,从而在该文件上生成签名。 并使用相应的公钥来验证签名。 因此,只有拥有私钥的人才能生成签名,但拥有相应公钥的任何人都可以验证该签名。 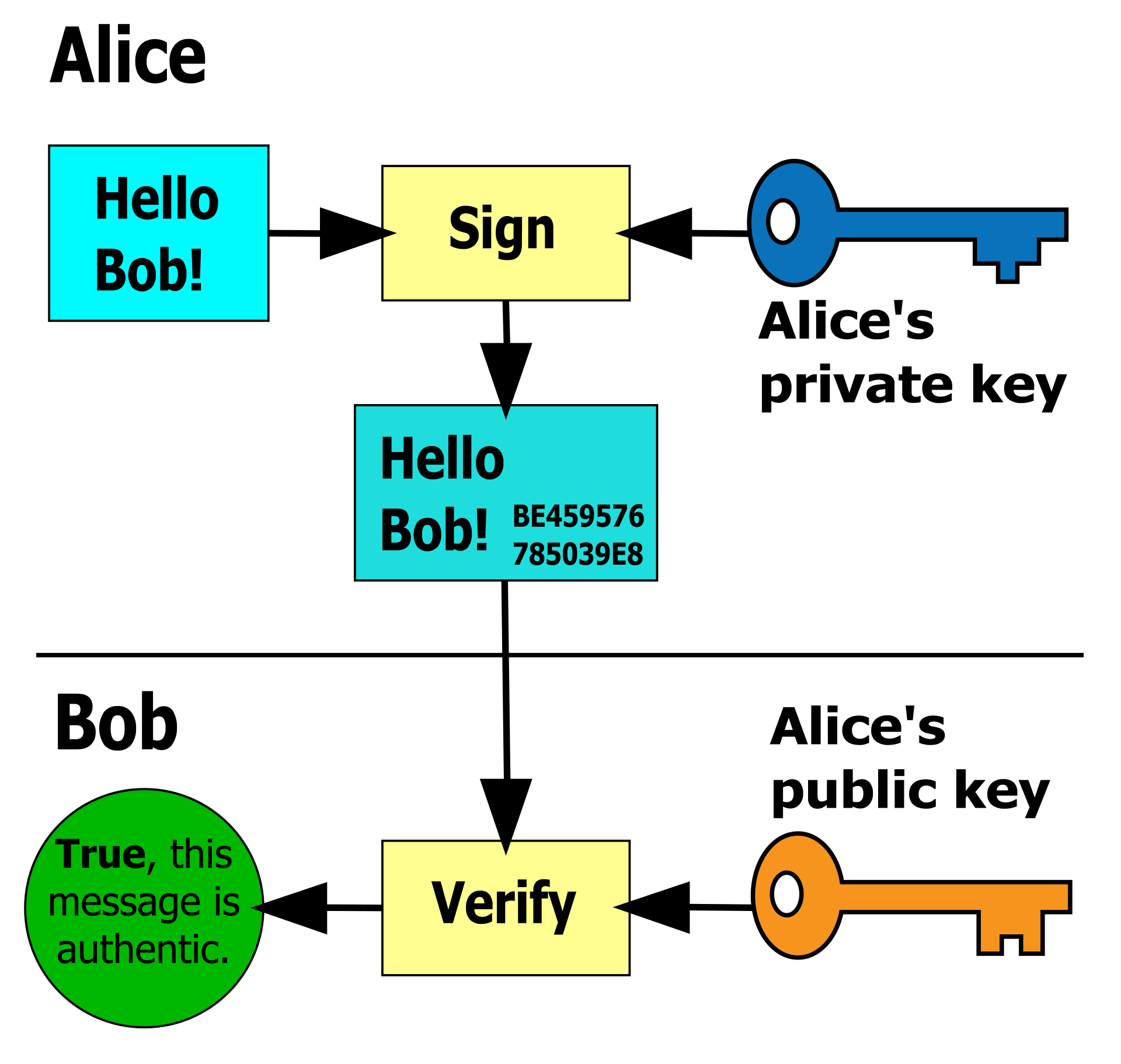
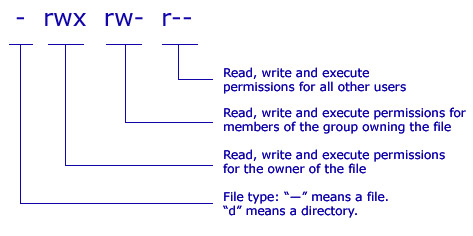
UNIX 权限模型有 3 个组成部分:授予文件的 (1) 所有者用户、(2) 所有者组和 (3) 其他人/其他所有人的权限。 权限本身有 3 个子组件:(1) 读取、(2) 写入和 (3) 执行,强制执行读取、写入或执行文件的能力。
gpg
- 解密b8/file1.txt.gpg:
1 | gpg --decrypt b8/file1.txt.gpg |
- 输入密码ocfdecal后,解密内容为: mYp@sw0rd2. 导入密钥的命令是:
1 | gpg --import {key_file} |
- 将密钥导出到文件的命令:
1 | gpg --export --armor {key_id} > {output_file} |
- 查看钥匙圈所有钥匙的命令:
1 | gpg --list-keys |
- 使用私钥b8/lab8privkey解密b8/file2.txt.gpg:
1 | gpg --import ./lab8privkey |
hash
sha1sum [FILE]获取 SHA1 哈希值[FILE].md5sum [FILE]获取 MD5 哈希值[FILE].
安全系统
威胁模型
设计安全系统时要记住的最重要的事情是 了解您的威胁模型。 没有系统能够保证安全或能够 能够抵挡所有的攻击,甚至在极端的情况下也是不可能的。 对手。 但是,您可以(并且应该)针对威胁采取预防措施 你很可能会面临。 平衡授权用户访问的需求 在将未经授权的用户拒之门外的情况下,很容易出错。 幸运的是,聪明人已经将安全原则提炼为 中得到了很好的 第一个讲义 一些公理,在CS 161 的 介绍 (归功于大卫·瓦格纳教授)。 建议阅读讲义。
构建威胁模型时,请记住以下问题:
- 你在保护什么?
- 谁是你的对手?
- 您需要保护它的可能性有多大?
- 如果不加以保护,会产生什么后果?
- 您应该投入多少资源来保护它?
加密解密
对称密钥加密几乎对所有事物都有用,尤其是属于以下类别的事物:
- 加密传输中的数据(例如 HTTPS)
- 加密静态数据(例如手机上存储的数据)
作为示例,我们来探讨一下 iPhone 如何使用加密来保证数据安全:
- iPhone 的内部存储使用一组 AES 密钥进行加密,这些密钥存储在手机内部芯片上,并在工厂生成。
- 这些密钥又使用您的 PIN 进行加密。 您的 PIN 码允许手机解锁密钥,从而解密文件系统的其余部分。
与对称密钥加密不同,公钥加密中有 2 个密钥 ,密码系统由公钥 和 私钥组成 。 顾名思义, 公钥是公开共享的,这是其他人可以使用的方式 加密适合您的数据。 您使用您的私钥来解密此内容 数据。 只要没有人拥有你的私钥,任何人都可以使用你的公钥 加密数据并确保只有您可以解密它。 这是一个强大的 对称密钥范式的扩展,除了加密之外,它还允许 签名和不可否认性 公钥密码学与 RSA 算法 同义, 是最早经过验证的双密钥方案之一。 RSA 公钥加密工作原理的简要概述:
- RSA算法,通过一些高等数学(涉及素数和模数) 算术),返回 3 个数字:一个公共指数(又名密钥),一个私有指数, 和一个模数。 两个密钥的工作方式使得用一个密钥加密的数据只能 可以用另一个密钥解密。
- 为了加密数据,需要使用指数和模数之一对数据执行模幂运算。
- 为了解密数据,对加密数据进行模幂运算 与合作伙伴密钥和模数。 常用时,使用较大的指数 作为私钥,用于解密数据和创建签名, 较小的指数作为公钥,用于加密数据 并验证签名。 比如:
1 | ssh-keygen -t rsa -b 4096 |
该命令将生成两个文件, ~/.ssh/id_rsa和 ~/.ssh/id_rsa.pub。 正如命令所示,此命令生成 4096 位 RSA 密钥对。 你 应该能够猜测哪个文件代表公钥以及哪个文件必须 因此是私钥。 为了影响安全 SSH 登录,请使用 RSA密钥,用户必须首先将他们想要使用的公钥传输到 提前向服务器表明自己的身份。 然后,一旦会话结束 服务器和客户端之间建立的,服务器会加密一个随机数 号码与用户的公钥并发送给用户。 用户将 然后使用他们的私钥解密该值并返回该值的哈希值 到服务器,然后服务器可以自己散列该值以确定用户是否 能够成功解密随机数,从而表明拥有 匹配的密钥并作为身份验证的证据。
签名和证书
一开始,您 将发布 Natoshi 的公钥,此后,对于您发布的每个帖子,您 将使用您(Natoshi)的私钥对消息内容进行加密,并且 将其与您的原始消息一起发布。 那么,想验证的人 Natoshi(即公钥对应的私钥的所有者 属于 Natoshi)实际上确实发布了一条特定的消息,可以简单地 使用 Natoshi 的公钥解密加密签名并比较 内容与原始消息相反。
Natoshi 王位的觊觎者将是 无法签署他们的虚假声明,以便可以与他们核实 Natoshi 公开了公钥,因为他们没有 Natoshi 的私钥, 您可以放心,没有人会过度影响您的项目 当你躲避 IRS 和 DEA 时,除非他们碰巧有 仓库里装满了 ASIC 和大量廉价电力。
然而,在这个方案中,如何防止对手发布虚假信息 公钥并声称是您? (他们可以对此进行有效签名 假公钥)不知何故,你需要“引导”信任:有人需要 验证您的身份并公开确认您的公钥实际上 对应于你。
我们通过 证书 来做到这一点:签署的声明 声称特定的公钥实际上属于它所声称的人 属于。
谁签署此证书? 一个 证书颁发机构 ,我们的某人 信任负责验证身份和发布签名。
但是我们如何知道要信任哪些 CA,以及我们如何才能信任声称 真正值得信赖的是? 他们可能还需要证书。 它 听起来好像一路下来都是海龟; 然而,链条确实结束了 某处:所谓的信任根,根 CA。 这些 CA 的 证书是由浏览器和操作系统预安装的,因此 本质上受信任,无需任何进一步的证书。 如果根 CA 签署您的证书,我们假设他们已经完成了必要的尽职调查 愿意冒着声誉风险签署您的证书,并且基本上 相信他们的话。 这种模型被称为“ 信任网络” ,是网络如何 今天的安全工作正常进行。
不幸的是,它并不像我们希望的那样可靠: 有些 CA 很卑鄙,只要有足够的钱就会签署任何东西,从而导致有效的 为 microsoft.com 和 github.com 等域颁发的证书 显然不是 Microsoft 或 GitHub 的实体。 1 此外, 任何拥有足够边境控制的实体都可以强制安装自己的 根证书(例如哈萨克斯坦政府 2 ) 并截取 通过为任何域颁发自己的伪造证书来窃取任何流量。
您可能没有意识到,但 您使用并依赖证书和签名 每天。 每当您在网站地址栏附近看到绿色锁时, 访问,您正在通过 TLS 或 HTTPS 连接访问该网站,并且数据 您和网站之间的传输是加密的。 当你的浏览器 连接到网站的服务器,它会按顺序请求服务器的公钥 设置加密连接和服务器证书以便 验证其作为授权为您拥有的域提供服务的服务器的身份 要求。 然后,您的浏览器通过验证公钥来验证公钥 证书上的签名。 如果有人试图执行 对您进行中间人攻击,此证书验证步骤将失败, 因为受信任的 CA 不太可能颁发签名的证书 将您的域名转让给您以外的实体(除非您不幸 居住在哈萨克斯坦)。 您将收到一条非常侵入性的通知 这个事实,忽略证书验证是一个坏主意 失败通知。
怎么为自己的网站设置https加密传输数据 现在您有了一个网站,您决定,作为一个优秀的互联网公民,您 希望保护您的访客免受政府的窥探,通过 设置 HTTPS。 您已经知道您将需要一个公钥和一个 为此,由受信任的根 CA 签署的证书。 你怎么去 关于得到一个? 在互联网上搜索,你发现了一个很棒的项目,名为 Let's Encrypt 提供免费、签名的服务 证书。
文件安全
作为 root用户。 当程序启动时,它会继承其用户 ID 和组 ID 父进程,并保留它们,除非手动删除权限。 如果你 以 root 用户身份启动程序,因为,例如,它需要更深入的 系统访问,程序中的漏洞意味着攻击者可以 以 root 用户身份与您的计算机进行交互。 这是一个常见问题 错误配置的网络服务器,其中服务器以根目录运行 遍历漏洞可能允许攻击者读取秘密凭证 存储在服务器的文件系统上。
这个故事的寓意与最小特权原则紧密相连:无论在哪里 可能的话,只给予尽可能少的许可或特权。 如果 程序不需要 root 凭据,请勿以特权用户身份运行它。 如果 文件包含敏感内容,请勿使其可读。
如何更改权限? 有两个主要命令可以执行此操作: chmod和 chown. chmod更改文件模式,即权限,以及 其语法示例如下:
1 | $ ls -la ~/ |
chmod接受八进制表示法的文件权限,即 下列的:
| # | 读写 |
|---|---|
| 7 | 读写 |
| 6 | RW- |
| 5 | 接收 |
| 4 | r– |
| 3 | -wx |
| 2 | -在- |
| 1 | -X |
| 0 | — |
pueept
● 流行的配置管理软件 ● 用于配置单个机器 ● 声明性哲学,必要时带有一些命令式组件 ● 最初基于 Ruby 构建,现在拥有自己的配置语言 流程: ● 客户端向服务器请求更新 ○ “我想配置为 Minecraft 服务器” ● 服务器向客户端询问事实列表 ○ “好的,请将您的主机名和 RAM 发送给我” ● 客户用事实回应 ○ “我的主机名是僵尸.ocf.berkeley.edu,我有 4GB RAM” ● 服务器响应配置 ○ “确保 Minecraft 服务器正在运行,主机名为僵尸.ocf.berkeley.edu,4GB RAM, 这个配置文件 ● 客户端进行必要的更改以确保其当前配置与 服务器给出的配置 ○ “minecraft服务器当前正在运行,但配置文件已更新,我将获取 更新后的版本 Puppet是一个配置管理工具,通过Puppet可以实现对大量服务器/主机的集中化、自动化的配置管理。Puppet的工作原理是:
- 在Puppet Master服务器上面编写Puppet Manifests(配置文件)。这些文件使用Puppet语言定义了服务器的最终状态。
- Puppet Agent安装在被管理的主机上面,它会定期从Puppet Master拉取配置。
- Puppet Agent对本地服务器状态进行检查,然后根据Manifests对服务器进行配置,确保服务器状态与预期状态一致。
- 如果配置发生变化,Puppet会自动应用这些变化,无需手动操作。
- Puppet Agent会定期运行,如果配置失效会再次修正。所以Puppet脚本就是编写Puppet Manifests的文件,它定义了需要配置什么,怎么配置。常见的配置包括:- 安装软件
- 管理服务
- 配置文件内容
- 用户和权限
- 安全设置
- 定时任务 等等通过Puppet脚本可以实现服务器配置的版本控制、自动化部署,大幅减少管理时间成本。它适用于需要管理大量Linux/Unix主机的场景。
git
创建一个分支:
1 | git checkout -b dice |
这使得一个新的本地分支称为 dice基于我们所在的分支机构 目前在( master)并将您切换到 dice分支。 这个命令是 基本上简写为:
1 | git branch dice # Create new branch called 'dice' |
您可以通过键入来查看您创建的分支 git branch。 你应该看到 此时有两个分支,一个称为 master和一个叫 dice。 一个 星号位于您当前签出的分支旁边。 git log查看历史提交。 每个提交都有一些信息,例如提交的作者、 创建提交的时间戳和提交消息。
每个提交条目的第一行都有一个长的十六进制字符串。 这是 commit hash :将其视为可用于引用的唯一 ID 具体提交。
有些提交在提交哈希旁边的括号中包含分支信息, 表明它们是最近的提交或
HEAD那个分支的。 你的 最近的提交应该有类似的内容(HEAD -> dice)。 第四个 提交应该有(origin/master, origin/HEAD)因为我们的分支机构 关闭master并在其之上添加了三个新的提交。 请注意,如果 有人向本地或远程添加新提交master, 分支 信息可能会更改或过时。
1 | commit adc45cd5110b59f76cefc2b862d0e4d550ccb183 (HEAD -> dice) |
除了查看提交历史记录之外,您可能还想查看实际的更改 在代码中。 您可以使用 git diff <old commit> <new commit>查看 两次提交之间的差异。
除了查看提交历史记录之外,您可能还想查看实际的更改 在代码中。 您可以使用 git diff <old commit> <new commit>查看 两次提交之间的差异。 有几种不同的方式可以引用 一次提交。 之前提到的一个是复制提交的哈希值(请注意 您的提交哈希值将与下面的示例不同):
1 | git diff 3368313c0afb6e306133d604ca72b0287124e8f2 762053064506810dee895219e5b2c2747a202829 |
您还可以复制提交哈希开头的一小块,而不是 整个哈希。 由于哈希的工作方式,您不太可能 有两个具有完全相同的起始序列的提交。
1 | git diff 3368313 7620530 |
如果你想尝试 diff两个提交非常接近 日志,一种更简单的方法是通过距提交的距离来引用提交 HEAD (最近)使用以下格式提交 HEAD~<number>。 由于我们添加了三个 提交新的提交 dice,我们可以查看之间的差异 dice和 master使用以下命令:
1 | git diff HEAD~3 HEAD |
有多种方法可以处理合并冲突,但我们将采用的方法 在这个实验室中向您展示正在使用 git rebase。 我们的 dice分支是“基于” 这 master在某个时间点有分支,但是 master分行有 向前离开 dice基于过时的 master。 因此,我们想要 “重新基地” dice就目前的状态而言 master。 当你的 dice分支, 跑步 git rebase master。 Git 将回滚您所做的提交 dice, 复制 任何新的提交 master,并尝试在顶部重放您的提交。 有时 rebase无需您的干预即可运行完成,但是如果 存在合并冲突,您需要解决它。
Git 会告诉你如果遇到合并冲突该怎么办 在变基期间。 在这种情况下,打开 rand.py并找到冲突区域 应具有以下格式:
1 | <<<<<<< HEAD |
要解决冲突,只需保留您想要的行(您的行来自 dice) 和 删除冲突区域中的其他行(
1 | `<<<<<<< HEAD`, `=======`, `>>>>>>> dice` |
,以及来自 master 的不需要的代码),然后保存并退出 文件。 Git 会将您保存的内容作为文件的确切形式 看起来像在变基结束时,所以你所做的本质上是修复 文件,以便代码正常运行。 这意味着如果您有多个 合并冲突,您决定混合保留基础分支中的一些行 还有一些来自您的功能分支,您需要确保代码确实有效 正确。
现在您已经解决了合并冲突,请按照变基说明进行操作 暂存您的固定文件( git add rand.py),然后运行 git rebase --continue。 如果 Git 发现其他文件有更多合并冲突,您将遵循相同的操作 程序如上。 然而,我们只有一个有冲突的文件,所以我们的变基是 完成的! 跑步 git log查看我们 rebase 的结果。 你现在应该看到了 你想象中的队友 "dice rolling WIP"提交您分支的历史记录, 你的提交高于他们的提交。
docker
安装 Docker wsl2不支持systemctl命令,而是支持systemed命令 所以需要执行如下命令启动docker
1 | service docker start |
虚拟机 你的电脑里有一台电脑! ● 通过软件模拟抽象物理硬件 ● 虚拟机管理程序运行多个虚拟机 ● 隔离应用:更好的安全性、稳定性 ● 一些开销:需要不同的客户操作系统和模拟 每个应用程序的虚拟硬件数量 ● 需要一些时间来启动
容器 ● 通常与虚拟机进行比较,但更像是捆绑的进程 环境 ● 提供类似的隔离 ○ 然而,比虚拟机要少得多! 出于这个原因,我们仍然经常在虚拟机内运行容器(但是 每个虚拟机可以运行 >1 个容器) ● 启动速度比虚拟机快得多 ● 目标是通过共享代码提供轻量级隔离环境 ● 轻松打包应用程序以实现一致的部署 ● 常见的容器:Docker、rkt、LXC ● 很确定这是加州大学伯克利分校唯一使用的课程
| Command | Description |
|---|---|
| docker search | Search Docker Hub for pre-built images |
| docker pull | Pull an image or a repository from a registry |
| docker images | List images |
| docker build | Build an image from a Dockerfile |
| docker run | Run a command in a new container |
| docker ps | List containers |
| docker start/stop/restart | Start/stop/restart a container |
| docker exec | Run a command in a running container |
| docker inspect | Return low-level information on Docker objects |
| docker rm | Remove one or more containers |
| docker rmi | Remove one or more images |
docker ● 需要构建镜像 ● 通常使用 Dockerfile 来指定 如何构建快照 ● 快照是分层构建的 ○ 像洋葱一样 ○ 允许基于相同的快照层构建速度更快 ● 保持每一层最少化资源
自动化配置管理工具 ● 声明式:说出你想要什么,而不是如何做 ○ 应用程序弄清楚如何 ● 可以定义要安装的应用程序、要包含的文件等 ● 可以在不同“类别”的机器上安装不同的东西 (桌面与服务器) ● 常用工具:Puppet、Ansible、Chef
docker的使用
docker run hello-world
您应该看到一些友好的输出,如下所示:
1 | Unable to find image 'hello-world:latest' locally |
此消息表明您的安装似乎运行正常。 为了生成此消息,Docker 采取了以下步骤:
- Docker 客户端联系了 Docker 守护进程。
- Docker 守护进程从 Docker Hub 中提取“hello-world”镜像。
- Docker 守护进程从该映像创建了一个新容器,该容器运行生成您当前正在读取的输出的可执行文件。
- Docker 守护进程将该输出传输到 Docker 客户端,然后将其发送到您的终端。 在容器中默认以
root用户身份登录。
以交互方式运行容器。 如果您需要在裸系统上尝试和安装东西而不弄乱当前系统,那么这非常有用。 尝试运行以下命令:
docker run -it ubuntu:latest
这 -iflag 告诉 docker 保留 STDIN打开你的容器,然后 -t分配一个 伪 TTY flag为您 。 基本上,您需要两者才能在新启动的容器中拥有一个 shell。 尝试安装一些软件包 apt或者只是玩玩。 它看起来应该像一个裸露的 Linux 系统。
使用 CTRL+D 退出容器。 自然的问题是,Docker 镜像是如何构建的? Dockerfile 。 就像镜像的源代码 相反,Dockerfile允许您通过指定手动键入创建镜像的所有命令来定义镜像。 然后 Docker 可以从指定Dockerfile 构建镜像。 这些 Dockerfile 可以放入版本控制中,并将镜像上传到在线存储库。
Docker可以通过读取来自Dockerfile的指令来自动构建镜像 。 Dockerfile是一个文本文档,其中包含所有命令 用户可以在命令行上调用来构建镜像。 eg.下面是一个 Dockerfile ,通过将 Python 3 和软件包安装到基础 Fedora Linux 映像上
1 | # Specify Fedora Linux as base image |
docker build -t missile:latest .
这告诉 Docker 在当前目录中查找 Dockerfile,并用该文件构建一个镜像。 这 -tflag 告诉 Docker 使用名称标记此构建 missile:latest。
查看系统上正在运行的容器。 使用以下命令:
docker ps
由于您(可能)没有运行任何容器,因此您可能不会看到任何有趣的东西。 但是,如果您传入 -a标志,您还可以看到已停止的容器:
要获取有关容器的更多信息,您可以使用 docker logs命令 获取容器的日志(无论它仍在运行还是已退出):
docker logs <container_id_or_name>
在某些时候,您可能想要清理已退出且不打算再使用的容器:
docker rm <container_id_or_name>
将移除容器。
查看已经下载的镜像: docker images 图像可能会占用计算机上相当多的空间,因此您可能需要清理不打算使用的图像 使用。 如果您收到有关计算机上没有足够磁盘空间的错误,这一点尤其重要:
docker rmi <image_id>
镜像文件以及容器的各种文件系统都存储在 /var/lib/docker
分离容器
容器可以以后台服务的形式运行,这适用于一些后台服务的场合,Docker 支持这种方式 以 -d标志,见 分离 方式启动容器 模式
Docker 为容器创建一个单独的虚拟网络,因此您需要将主机端口转发到您的 容器的端口(这称为 端口转发 或端口映射)。 容器正在侦听端口 80,因此让我们尝试将主机的端口 5050 转发到容器的端口 :
docker run -d -p=5050:80 httpd
-p 接受冒号分隔的一对 HOST_PORT:CONTAINER_PORT
您实际上可以“附加”到正在运行的容器并在其中运行更多命令,类似于 docker run作品。 使用 这 docker exec命令:
docker exec <container_id_or_name> <command>
要停止此容器,请使用 docker stop <container_id_or_name>.
您可以使用以下命令重新启动容器 docker restart <container_id_or_name>.
关于 docker-compose
docker-compose允许您定义需要多个容器才能运行的应用程序。 例如,在网络上 应用程序,您可能希望实际的 Web 应用程序在单个容器内运行,并且数据库在其中运行 一个不同的容器。
通常,您根据 服务 来定义应用程序。 同样,以 Web 应用程序为例,有 两个不同的服务:应用程序本身和支持它的数据库。 docker-compose让您定义不同的服务 在 YAML 文件中并相应地运行服务。
其中一件好事是 docker-compose是它会自动为您的容器设置一个网络,其中:
- 服务的每个容器都位于网络上,并且可以从网络上的其他容器访问
- 每个容器都可以通过其容器名称在网络上发现
使用 Docker 官方网站上的说明安装 Docker Compose
一些小脚本
1 | #!/bin/bash |
1 | #!/bin/bash |
1 | #1/bin/bash |