基于伯克利cs61a的python笔记
python语言特性
函数
名称也可以与函数绑定。例如,名称 max 就和我们之前使用的 max 函数进行了绑定。与数字不同,函数很难以文本呈现,因此当询问一个函数时,Python 会打印一个标识来描述: 1
2>>> max
<built-in function max>
赋值语句可以为现有函数赋予新名称。
1 | >>> f = max |
以下指南改编自 Python 代码风格指南, 它可以作为所有(非叛逆的)Python 程序员的指南。这些共享的约定使开发者社区的成员之间的沟通能够顺利进行。作为遵循这些约定的副作用,你会发现你的代码在内部变得更加一致。
- 函数名是小写的,单词之间用下划线分隔。鼓励使用描述性名称。
- 函数名称通常反映解释器应用于参数的操作(例如,
print, add, square)或结果(例如,max, abs, sum)。 - 参数名称是小写的,单词之间用下划线分隔。首选单个词的名称。
- 参数名称应该反映参数在函数中的作用,而不仅仅是允许的参数类型。
- 当作用明确时,单字参数名称可以接受,但应避免使用 l(小写的 L)和 O(大写的 o)或 I(大写的 i)以避免与数字混淆。
函数设计原则
- 每个函数应该只负责一个任务,且该任务要用一个简短的名称来识别,并在一行文本中进行描述。按顺序执行多个任务的函数应该分为多个函数。
- 不要重复自己(Don't repeat yourself)是软件工程的核心原则。这个所谓的 DRY 原则指出,多个代码片段不应该描述重复的逻辑。相反,逻辑应该只实现一次,为其指定一个名称后多次使用。如果你发现自己正在复制粘贴一段代码,那么你可能已经找到了进行函数抽象的机会。
- 定义通用的函数。比如作为
pow函数的一个特例的平方函数就不在 Python 库中,因为pow函数可以将数字计算为任意次方。 当你使用函数名称作为参数调用help时,你会看到它的文档字符串(键入 q 以退出 Python help)。 Python 中的注释可以附加到#号后的行尾。例如,上面代码中的注释玻尔兹曼常数描述了k变量的含义。这些注释不会出现在 Python 的help中,而且会被解释器忽略,它们只为人类而存在。
1 | >>> help(pressure) |
数据结构
链表
1 | class Link: |
抽象障碍
每当程序的一部分可以使用更高级别的函数而不是使用较低级别的函数时,就会违反抽象障碍。例如,计算有理数平方的函数最好用 mul_rational 实现,它不对有理数的实现做任何假设。
1 | >>> def square_rational(x): |
序列
范围通常出现在 for 语句 header 中的表达式,以指定 <suite> 应执行的次数。如果 <name> 没有被用在 <suite>,一个惯用的使用方式是,使用下划线表示 <name>。
python
1 | >>> for _ in range(3): |
对解释器而言,下划线只是环境中的另一个名称,但对程序员具有约定俗成的含义,表示该名称不会出现在任何未来的表达式中。 列表推导式的一般形式是:
python
1 | [<map expression> for <name> in <sequence expression> if <filter expression> |
为了运算列表推导式,Python 首先评估 <sequence expression>,它必须返回一个 iterable 值。然后,每个元素依次绑定到 <name>,再运算 <filter expression>;如果产生一个真值,运算 <map expression>。最后 <map expression> 的值被收集到一个列表中
reduce 可用于将序列的所有元素相乘。使用 mul 作为 reduce_fn, 1 作为 initial 值, reduce 可用于将各数字相乘。
python
1 | >>> reduce(mul, [2, 4, 8], 1) |
多行文字 (Multiline Literals)。字符串不限于一行。跨越多行的字符串文字可以用三重引号括起。我们已经在文档字符串中广泛使用了这种三重引号。
迭代器
迭代器的用处源自以下事实: 迭代器的一系列数据可能不会在内存中显式表示。 迭代器提供了一种考虑一系列值中的每一个的机制 轮,但所有这些元素不需要同时存储。 相反,当迭代器请求下一个元素时,该元素可能会 按需计算,而不是从现有内存中检索 来源。
范围能够惰性地计算序列的元素,因为 表示的序列是统一的,并且任何元素都很容易从 范围的开始和结束边界。 迭代器允许延迟生成 更广泛的底层序列数据集类别,因为它们不需要 提供对底层系列的任意元素的访问。 反而, 迭代器只需要按顺序计算该系列的下一个元素, 每次请求另一个元素时。 虽然不像访问那样灵活 序列的任意元素(称为 随机访问 )、 顺序访问 顺序数据通常足以满足数据处理应用程序的需要。 函数 map 是惰性的:调用它并不执行计算 需要计算其结果的元素。
1 | >>> def double_and_print(x): |
迭代器
可迭代的 Letters 实例 b_to_k 和 LetterIter 迭代器 实例 first_iterator 和 second_iterator的 不同之处在于 字母 实例不会改变,而迭代器实例会改变 每次调用 next (或等效地,每次调用 next )。 迭代器通过顺序数据跟踪进度,而可迭代器 代表数据本身。
Python 中的许多内置函数都采用可迭代参数并返回迭代器。 函数 map 例如, 接受一个函数和一个可迭代对象。 它返回 将函数参数应用于每个元素的结果的迭代器 在可迭代的参数中。
1 |
|
生成器
生成器函数是生成值而不是返回值的函数 普通函数返回一次; 一个生成器函数可以产生多次 生成器是通过调用生成器函数自动创建的迭代器 当调用生成器函数时,它返回一个迭代其产量的生成器
1 | >>> def plus_minus(x): |
高阶函数
嵌套定义
1 | >>> def sqrt(a): |
与局部赋值一样,局部 def 语句只影响当前局部帧。这些函数仅在求解 sqrt 时在作用域内。与求解过程一致,这些局部 def 语句在调用 sqrt 之前都不会被求解。
词法作用域(Lexical scope):局部定义的函数也可以访问定义作用域内的名称绑定。在此示例中, sqrt_update 引用名称 a,它是其封闭函数 sqrt 的形式参数。这种在嵌套定义之间共享名称的规则称为词法作用域。最重要的是,内部函数可以访问定义它们的环境中的名称(而不是它们被调用的位置)。
我们需要对我们的环境模型实现两个扩展来启用词法作用域。
- 每个用户定义的函数都有一个父环境:定义它的环境。
- 调用用户定义的函数时,其局部帧会继承其父环境。 Python 中词法作用域的两个关键优势。
- 局部函数的名称不会影响定义它的函数的外部名称,因为局部函数的名称将绑定在定义它的当前局部环境中,而不是全局环境中。
- 局部函数可以访问外层函数的环境,这是因为局部函数的函数体的求值环境会继承定义它的求值环境。
lambda
不像 定义 语句、lambda 表达式可以用作运算符或 调用表达式的操作数。 这是因为它们只是一行 计算结果为函数的表达式
1 | >>> what = lambda x : x + 5 |
类
1 | >>> class Account: |
内置函数 getattr 还按名称返回对象的属性。它是点表示法的函数等效物。使用 getattr ,我们可以使用字符串查找属性,就像我们对调度字典所做的那样。
python
1 | >>> getattr(spock_account, 'balance') |
我们还可以测试应该对象是否具有 hassattr 的名命属性。
python
1 | >>> hasattr(spock_account, 'deposit') |
我们可以通过对点表达式的返回值调用 type 来查看交互式解释器的差异。作为类的属性,方法只是一个函数,但作为实例的属性,它是一个绑定方法:
python
1 | >>> type(Account.deposit) |
这两个结果的区别仅在于第一个是参数为 self 和 amount 的标准双参数函数。第二种是单参数方法,调用方法时,名称 self 将自动绑定到名为 spock_account 的对象,而参数 amount 将绑定到传递给方法的参数。这两个值(无论是函数值还是绑定方法值)都与相同的 deposit 函数体相关联。 在某些情况下,有一些实例变量和方法与对象的维护和一致性相关,我们不希望对象的用户看到或使用。它们不是类定义的抽象的一部分,而是实现的一部分。Python 的约定规定,如果属性名称以下划线开头,则只能在类本身的方法中访问它,而不是用户访问。
计算点表达式:
- 点表达式左侧的
<expression>,生成点表达式的对象。 <name>与该对象的实例属性匹配;如果存在具有该名称的属性,则返回属性值。- 如果实例属性中没有
<name>,则在类中查找<name>,生成类属性。 - 除非它是函数,否则返回属性值。如果是函数,则返回该名称绑定的方法。
约束传递 (Propagating Constraints)
可变数据允许我们模拟具有变化的系统,也允许我们构建新的抽象类型。在这个扩展示例中,我们结合了非局部赋值、列表和字典来构建一个支持多方向计算的基于约束系统。将程序表示为约束是一种声明式编程,在这种编程中,程序员声明要解决的问题的结构,而不是抽象出问题解决方案的具体计算方式的细节。
计算机程序传统上被组织为单向计算,它对预先指定的参数执行操作以产生所需的输出。另一方面,我们通常希望根据数量之间的关系对系统进行建模。例如,我们之前考虑过理想气体定律,它通过玻尔兹曼常数 (k) 将理想气体的压力 (p)、体积 (v)、数量 (n) 和温度 (t) 联系起来:
p * v = n * k * t
这样的方程不是单向的。给定任何四个量,我们可以使用这个方程来计算第五个。然而,将方程式翻译成传统的计算机语言会迫使我们选择一个量来根据其他四个量进行计算。因此,计算压力的函数不能用于计算温度,即使这两个量的计算来自同一个方程。
在本节中,我们概述了线性关系的一般模型的设计。我们定义了在数量之间保持的原始约束,例如强制数学关系 a + b = c 的 adder(a, b, c) 约束。
我们还定义了一种组合方式,以便可以组合原始约束来表达更复杂的关系。这样,我们的程序就类似于一种编程语言。我们通过构建一个网络来组合约束,在该网络中约束由连接器 (connector) 连接。连接器是一个对象,它“持有”一个值并且可以参与一个或多个约束。
例如,我们知道华氏温度和摄氏温度之间的关系是:
9 * c = 5 * (f - 32)
该等式是 c 和 f 之间的复杂约束。这样的约束可以被认为是一个由原始加法器 (adder) 、乘法器 (multiplier) 和常量 (constant) 约束组成的网络。
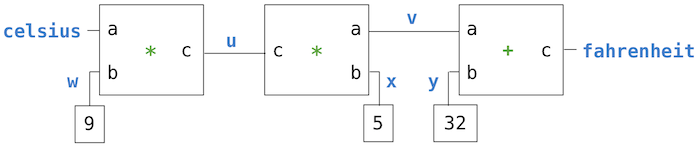
在此图中,我们在左侧看到一个乘数框,其中包含三个端子,标记为 a 、b 和 c。这些将乘数连接到网络的其余部分,如下所示:终端连接到连接器 celsius,该连接器将保持摄氏温度。b 端子连接到连接器 w,该连接器链接到常量 9。乘数盒约束为 a 和 b 乘积的 c 端链接到另一个乘法盒的 c 端,其 b 连接到常量 5,其 a 连接到和约束中的项之一。
这种网络的计算过程如下:当一个连接器被赋予一个值时(由用户或由它链接到的约束框),它会唤醒所有相关的约束(除了刚刚唤醒它的约束) 以告诉他们它有值。每个被唤醒的约束框之后轮流询问其连接器,以查看是否有足够的信息来确定连接器的值。如果有,该框设置该连接器,然后唤醒所有关联的约束,依此类推。例如,在摄氏度和华氏度之间的转换中, w、 x 和 y 立即被常量框分别设置为 9、 5 和 32。连接器唤醒乘法器和加法器,它们确定没有足够的信息继续进行。如果用户(或网络的其他部分)将摄氏连接器设置为一个值(比如 25),最左边的乘法器将被唤醒,它将 u 设置为 25 * 9 = 225。然后你唤醒第二个乘法器,将 v 设置为 45,v 唤醒加法器,将 fahrenheit 连接器设置为 77。
使用约束系统 (Using the Constraint System)。要使用约束系统执行上述温度计算,我们首先通过调用连接器构造函数创建两个命名连接器,摄氏度 celsius 和华氏度 fahrenheit。
python
1 | >>> celsius = connector('Celsius') |
然后,我们将这些连接器链接到一个反映上图的网络中。函数转换器 (converter) 组装网络中的各种连接器和约束。
python
1 | >>> def converter(c, f): |
python
1 | >>> converter(celsius, fahrenheit) |
我们将使用消息传递系统来协调约束和连接器。约束是不包含局部状态本身的字典。它们对消息的响应是非纯函数,会更改它们约束的连接器。
连接器是保存当前值并响应操纵该值的消息的字典。约束不会直接更改连接器的值,而是通过发送消息来更改,以便连接器可以通知其他约束以响应更改。这样,一个连接器既代表了一个数字,同时也封装了连接器的行为。
我们可以发送给连接器的一条消息是设置它的值。在这里,我们( “ user ” )将 celsius 的值设置为 25。
python
1 | >>> celsius['set_val']('user', 25) |
不仅 celsius 的值变为 25,而且它的值通过网络传播,因此 fahrenheit 的值也发生变化。打印这些更改是因为我们在构造它们时命名了这两个连接器。
现在我们可以尝试将 fahrenheit 度设置为一个新值,比如 212。
python
1 | >>> fahrenheit['set_val']('user', 212) |
连接器抱怨说它感觉到了一个矛盾:它的值为 77.0,而有人试图将它设置为 212。如果我们真的想用新值应用到网络,我们可以告诉 celsius 忘记它的旧值:
python
1 | >>> celsius['forget']('user') |
连接器 celsius 发现最初设置其值的用户现在收回该值,因此 celsius 同意失去其值,并将这一事实通知网络的其余部分。这个信息最终传播到 fahrenheit,它现在发现它没有理由继续相信它自己的值是 77。因此,它也放弃了它的值。
现在 fahrenheit 没有值,我们可以将其设置为 212:
python
1 | >>> fahrenheit['set_val']('user', 212) |
这个新值在通过网络传播时会迫使 celsius 的值变为 100。我们使用了完全相同的网络来计算给定 celsius 的 fahrenheit 和给定 fahrenheit 的 celsius。这种计算的非方向性是基于约束的系统的显着特征。
实施约束系统 (Implementing the Constraint System)。正如我们所见,连接器是将消息名称映射到函数和数据值的字典。我们将实施响应以下消息的连接器:
python
1 | >>> connector ['set_val'](source, value) """表示 source 在请求连接器将当前值设为 value""" |
约束也是字典,它通过两条消息从连接器接收信息:
python
1 | >>> constraint[\'new_val']() """表示与约束相连的某个连接器具有新的值。""" |
当约束收到这些消息时,它们会将消息传播到其他连接器。
adder 函数在三个连接器上构造一个加法器约束,其中前两个必须与第三个相加:a + b = c。为了支持多向约束传播,加法器还必须指定它从 c 中减去 a 得到 b,同样地从 c 中减去 b 得到 a。
python
1 | >>> from operator import add, sub |
我们想实现一个通用的三元(三向)约束,它使用来自 adder 的三个连接器和三个函数来创建一个接受 new_val 和 forget 消息的约束。对消息的响应是局部函数,它们被放置在称为约束的字典中。
python
1 | >>> def make_ternary_constraint(a, b, c, ab, ca, cb): |
称为约束的字典是一个调度字典,也是约束对象本身。它响应约束接收到的两条消息,但也作为调用其连接器的 source 参数传递。
每当约束被告知其连接器之一具有值时,就会调用约束的局部函数 new_value。该函数首先检查 a 和 b 是否都有值。如果是,它告诉 c 将其值设置为函数 ab 的返回值,在加法器的情况下为 add。约束将自身(约束)作为连接器的 source 参数传递,该连接器是加法器对象。如果 a 和 b 不同时都有值,则约束检查 a 和 c,依此类推。
如果约束被告知它的一个连接器遗忘了它的值,它会请求它的所有连接器遗忘它们的值。(实际上只有那些由此约束设置的值会丢失。)
乘法器与加法器非常相似。
python
1 | >>> from operator import mul, truediv |
常量也是一种约束,但它永远不会发送任何消息,因为它只涉及它在构造时设置的单个连接器。
python
1 | >>> def constant(connector, value): |
这三个约束足以实现我们的温度转换网络。
连接器表示 (Representing connectors)。连接器表示为包含值的字典,也有具备局部状态的响应函数。连接器必须跟踪为其提供当前值的信息提供者,以及它参与的约束列表。
构造函数连接器具有用于设置和遗忘值的局部函数,这些值是对来自约束的消息的响应。
python
1 | >>> def connector(name=None): |
连接器也是约束用于与连接器通信的五个消息的调度字典。四个响应是函数,最后的响应是值本身。
当有设置连接器值的请求时调用局部函数 set_value。如果连接器当前没有值,它将设置它的值并记住请求设置值的源约束作为信息提供者。然后连接器将通知它的所有参与约束,除了请求设置值的约束。这是使用以下迭代函数完成的。
python
1 | >>> def inform_all_except(source, message, constraints): |
如果要求连接器遗忘其值,它会调用局部函数 forget-value,该函数首先检查以确保请求来自与最初设置值相同的约束。如果是这样,连接器会通知其关联的约束有关值的丢失。
对消息 has_val 的响应表明连接器是否有值。 对消息连接的响应将源约束添加到约束列表中。
我们设计的约束程序引入了许多将在面向对象编程中再次出现的思想。约束和连接器都是通过消息操作的抽象。当连接器的值发生变化时,它会通过一条消息进行更改,该消息不仅会更改值,还会验证它(检查源)并传播其效果(通知其他约束)。事实上,我们将在本章后面使用具有字符串值键和函数值的字典的类似架构来实现面向对象的系统
debug
请注意,回溯中的行似乎是配对在一起的。 该对中的第一行具有以下格式: 文件“<文件名>”,第 <编号> 行,<函数>
1 | File "<file name>", line <number>, in <function> |
该行为您提供以下信息: 文件名:包含问题的文件的名称。 Number:文件中引起问题的行号,或包含下一个函数调用的行号 函数:可以在其中找到该行的函数的名称。 回溯消息中的最后一行是错误语句。 错误语句具有以下格式: <错误类型>:<错误消息> 这一行为您提供了两条信息: 错误类型:引起的错误类型(例如SyntaxError,TypeError)。 这些通常具有足够的描述性,可以帮助您缩小错误原因的搜索范围。 错误消息:更详细地描述导致错误的原因。 不同的错误类型会产生不同的错误消息。
Running doctests
Python has a great way to quickly write tests for your code. These are called doctests, and look like this:
1 | def foo(x): |
The lines in the docstring that look like interpreter outputs are the doctests. To run them, go to your terminal and type:
1 | python3 -m doctest file.py |
1 | python3 -m doctest file.py -v |
许多程序员喜欢研究他们的代码的一种方法是使用交互式 REPL。 也就是说,您可以在其中直接运行函数并检查其输出的终端。 通常,要完成此操作,您可以运行
1 | python -i file.py |
使用 assert声明
Python 有一个特性称为 assert语句,它可以让您测试条件是否为真,并打印错误 否则在一行中消息。 如果您知道某些条件在某些点需要为真,这会很有用 在你的程序中。 例如,如果您正在编写一个接受整数并将其加倍的函数,那么它可能会很有用 确保您的输入实际上是一个整数。 然后你可以编写以下代码
1 | def double(x): |
请注意,我们并没有真正调试 double在这里,我们正在做的是确保任何拨打电话的人 double正在以正确的论点这样做。 例如,如果我们有一个函数 g接受一个字符串和一个数字 并将字符串的长度添加到数字的两倍,其实现如下:
1 | def g(x, y): |
SyntaxError
原因 :代码语法错误
示例 :
1
2
3
4File "file name", line number
def incorrect(f)
^
SyntaxError: invalid syntax解决办法 :
^符号指向包含的代码 无效的语法。 错误消息没有告诉你 什么 是 错了,但它确实告诉你 在哪里 。注意 :Python 将检查
SyntaxErrors执行之前 任何代码。 这与其他错误不同,其他错误仅 在运行时引发。
IndentationError
原因 :缩进不当
示例 :
1
2
3File "file name", line number
print('improper indentation')
IndentationError: unindent does not match any outer indentation level解决方案 :显示缩进不正确的行。 只需重新缩进即可。
注意 :如果制表符和空格不一致,Python 将提出其中之一。 确保使用空格! (只是少了点 在 Python 中使用空格和所有 cs61a 内容通常令人头痛 使用空格)。
TypeError
原因一 :
原始运算符的操作数类型无效。 你是 可能尝试加/减/乘/除不兼容 类型。
示例 :
1
TypeError: unsupported operand type(s) for +: 'function' and 'int'
原因2 :
在函数调用中使用非函数对象。
示例 :
1
2
3
4
5>>> square = 3
>>> square(3)
Traceback (most recent call last):
...
TypeError: 'int' object is not callable
原因3 :
向函数传递错误数量的参数。
示例 :
1
2
3
4>>> add(3)
Traceback (most recent call last):
...
TypeError: add expected 2 arguments, got 1
NameError
原因 :变量没有分配给任何东西或者没有分配 存在。 这包括函数名称。
示例 :
1
2
3File "file name", line number
y = x + 3
NameError: global name 'x' is not defined解决方案 :确保您正在初始化变量(即 在使用之前为变量分配一个值)。
注意 :错误消息显示“全局名称”的原因是 因为Python将从a开始搜索变量 函数的本地框架。 如果在那里找不到该变量, Python将继续搜索父框架,直到到达 全球框架。 如果仍然找不到变量,Python 引发错误。
IndexError
原因 :尝试索引序列(例如元组、列表、 string)的数字超过了序列的大小。
示例 :
1
2
3File "file name", line number
x[100]
IndexError: tuple index out of range解决方案 :确保索引在范围内 顺序。 如果您使用变量作为索引(例如
seq[x], 确保变量被分配给正确的索引。
object
因为两个列表可能内容相同,但实际上是不同的列表,所以我们需要一种方法来测试两个对象是否是同一个。Python 包括两个比较运算符,称为 is 和 is not,它们测试两个表达式实际上是否计算为相同的对象。如果两个对象的当前值相等,则它们是相同的,并且对一个对象的任何更改都将始终反映在另一个对象中。身份是比相等更强大的条件。
1 | suits is ['heart', 'diamond', 'spade', 'club'] |
字典也确实有一些限制:
- 字典的键不能是或包含可变值。
- 对于给定的键,最多只能有一个对应的值。 非局部语句 (nonlocal statement)。当我们调用 make_withdraw 时,我们将 balance 绑定到初始金额。然后我们定义并返回一个局部函数 withdraw,它会在调用时更新并返回 balance 的值。
python
1 | >>> def make_withdraw(balance): |
非局部语句声明:每当我们更改 balance 的绑定时,绑定关系都会在已经绑定 balance 的第一帧中更改。回想一下,如果没有非局部语句,赋值语句将始终在当前环境的第一帧中绑定。非局部语句指示名称不会出现在第一个(局部)帧或最后一个(全局)帧,而是其他地方。
错题集
递增子序列
1 |
|
反转奇数深度树的标签
1 | return |
生成器的生成器
1 |
|
生成器生成树的搜索路径
1 | if t.label == value: |