基于哈佛cs50的计算机通识笔记
计算机安全常识
账户安全
美国国家标准与技术研究院(NIST)的建议:
- 密码长度应至少为八个字符
- 验证者应规定所有打印的 ASCII 字符和 Unicode 符号的长度最多为 64 个字符
- 验证者应该将预期的密码与可用的字典单词、重复序列、被破坏的密码列表和上下文特定的单词进行比较
- 验证者不应允许未经身份验证的用户访问密码提示
- 验证者不应要求定期更改密码
- 验证者应限制失败的身份验证尝试次数并锁定潜在的攻击者
多重身份验证(2fa)由三个组成部分组成。
- 知识:只有你知道的东西
- 所有物:仅由授权用户拥有的物品或设备
- 固有物:仅是您可以获得的一个因素,例如您的指纹、面部或其他生物识别信息
一次性密码 OTP:
- 人们可以获得一种特殊的密钥卡或提供一次性密码的设备
- OTP 通常是从设备或应用程序获取的
- 基于短信的 OTP 很容易通过 SIM 交换而被欺骗,攻击者会获取并克隆 SIM 卡并访问您的短信, 因此验证器类型的验证应用程序更安全(比如需要指纹验证的)
键盘记录:
- 用户名、密码和 OTP 很容易被攻击者记录您的击键
- 键盘记录是通过在计算机上安装恶意软件来完成的
- 最好确保您仅登录您只能访问的设备
社会工程/钓鱼:
- 懂得都懂,点击 url 时需要谨慎再谨慎,收到任何可能泄露信息的请求时核对对方身份
单点登录 SSO:
- SSO 允许您使用 Google 或 Facebook 登录来访问 Google 或 Facebook 未提供的服务
- 因此,您能够以更少的摩擦和更高的安全性轻松访问其他服务
密码管理器:
- 把鸡蛋放在一个篮子里,但是相对能提高安全性
- 推荐 keepass
数据安全
哈希:将一些纯文本转换为可读性较差的散列值输出的方法,常存储密码的哈希值从而降低风险
- 字典攻击 仍然可以将字典中的一个又一个值输入到哈希函数中,作为破解它的一种方式。
- 彩虹表 是另一种威胁,对手拥有哈希表中所有潜在哈希值的表。然而,这需要数 TB(甚至 PB)的存储容量才能完成
- 单向哈希函数 用代码编写,接收任意长度的字符串并输出固定长度的哈希值。
- 利用这样的功能,哈希值和哈希函数的持有者将永远不会知道原始密码。
盐:加盐 是将附加值“撒”到哈希函数中,从而使哈希值发生变化的过程,几乎可以保证用户提供的哈希值(即使是具有相同密码的用户)也会收到不同的哈希密码
非对称加密:你需要一个公钥一个私钥,例如公钥是两个素数的乘积,私钥是其中一个因数,私钥被收发双方共用
- 发送者使用公钥和明文并将其输入算法中。这会产生密文
- 接收者将私钥和密文输入到算法中。这会产生破译的文本
- 消息(文档的内容)被传递给哈希函数,从而产生哈希值,私钥和哈希值被传递给数字签名算法,从而产生数字签名;接收者将公钥和提供给解密算法的签名传递给解密算法,从而产生应与先前计算的哈希值相匹配的哈希值,验证签名
硬盘加密:
- 操作系统删除文件时,事实上只释放了空间,原有文件内容有可能留存一段时间,因此需要 安全删除 ,将已删除文件的所有剩余部分更改为零、一或零和一的随机序列
- 全盘加密 或 静态加密 可完全加密硬盘驱动器的内容。
- 如果您的设备被盗或您出售了设备,任何人都将无法访问您的加密数据。
- 然而,它的缺点是,如果您丢失密码或脸部发生足够大的变化,您将无法访问您的数据。
- 另一个缺点是黑客可能通过 勒索软件 使用相同类型的技术来加密您的硬盘并将其劫为人质
- 例如 veracrypt 之类的软件可以实现硬盘级或者文件级(将一个文件虚拟成硬盘分区)的加密,微软的 bitlock 配合部分硬件功能甚至可以实现硬件级加密(范围是卷)
量子计算:新兴的计算机技术,可能彻底颠覆目前的计算机密码学
系统安全
- 超文本传输协议 ( HTTP )是一种未加密的数据传输方式。
- 使用 HTTP,人们很容易受到 中间人 攻击,攻击者可能会在下载的内容中注入额外的 HTML 代码。广告可以被注入到您通过 HTTP 访问的所有网页中。此外,还可以插入恶意代码。
- 事实上,还存在其他威胁。 数据包嗅探 是攻击者查看双方之间传输的数据内部的一种方式。可以想象,放置在不安全数据包中的信用卡号会被攻击者检测到并窃取。
- Cookie 是网站放置在您计算机上的小文件。网站可能会使用 Cookie 来跟踪您的身份、显示您的电子邮件或跟踪您的购物车。 Cookie 使人容易受到 会话劫持 ,对手可以通过注入 超级 cookie 来跟踪您。
- HTTPS 是 HTTP 的安全协议。传输中加密流量(使用上一章提及的公钥加密技术)
- CA 是颁发证书的受信任的第三方公司
- 当访问网站时,浏览器会下载该网站的证书,并创建哈希值。
- 然后,它使用网站的公钥和提供给算法的证书签名来验证哈希值是否符合
- 如果哈希匹配,则网络浏览器应用程序确信这是一个安全网站
- SSL Stripping 是一种攻击者在网站上使用 HTTP 将流量重定向到恶意网站的攻击。攻击者甚至可能将其重定向到非预期网站的 HTTPS 安全域。
- 减轻这种威胁的一种方法是实施 HSTS 或 HTTP 严格传输安全 ,服务器告诉浏览器将所有流量引导到安全连接
- 攻击者可能会对服务器进行 端口扫描 ,尝试所有潜在端口以查看它们是否正在接受流量
- 防火墙是一种软件,通过阻止未经授权的访问(包括设备上受损的服务)来保护各种服务
- 防火墙利用 IP 地址 (分配给网络上每台计算机的唯一编号)来防止外部人员攻击
- 防火墙还可以使用 深度数据包检查 ,检查数据包中的数据以查找您的公司可能感兴趣的材料。这可以用来检查您是否正在向媒体或可能被您公司视为对手的其他方发送电子邮件。
- 使用 深度数据包检测通过代理 ,其中中间的设备用作流量传入和传出网络的路径。您的学校或公司可能会在此代理上更改 URL、记录您尝试浏览的 URL,并希望保护您免受潜在有害行为的影响。
- 蠕虫病毒 是一种恶意软件,可以通过安全漏洞从一台计算机转移到另一台计算机。
- 僵尸网络 是一种恶意软件,一旦安装在您的计算机上,就会感染其他计算机,并且攻击者可以利用它向数千台受感染的计算机发出命令。
- 受僵尸网络感染的计算机可用于发出 拒绝服务攻击 dos ,从而可以向服务器发出大量请求,以减慢或关闭服务器。由于僵尸网络中有如此多的计算机,因此这种类型的攻击可以称为 分布式拒绝服务攻击 ddos
- 零日攻击 ,这种攻击会在杀毒软件公司有机会创建修复程序之前利用软件中的未知漏洞
软件安全
- 攻击者可能会利用您不注意的情况,声称您正在链接到一个网页,而实际上您正在链接到另一个网页,如
<a href="https://yale.edu">https://harvard.edu</a> - 攻击者经常创建虚假版本的网站,其唯一目的是诱骗用户在这些网站中输入敏感信息。例如,如果您是一名哈佛学生,访问此类假哈佛网站,您可能会尝试登录并向对手提供您的用户名和密码
- 跨站点脚本攻击 ( XSS )是一种攻击形式,攻击者将代码附加到合法网站上, 通过用户的输入诱骗网站运行恶意代码。当受害者加载网站时,代码就会执行。
- 反射攻击 一种利用网站接受输入的方式来欺骗用户浏览器发送导致攻击的信息请求的攻击,如伪造了请求数据包的源 IP,接受请求的主机被诱骗将其 UDP 响应数据包发送到目标受害者 IP,而不是发送回攻击者的 IP 地址
- 存储攻击 网站可能容易受到攻击,被诱骗存储恶意代码。
- 字符逃脱 一些特殊字符如
<>可用于注入恶意代码,对于特殊字符安全软件应该进行转义 - 常见的转义字符包括:
<,“<”>,“>”&,“&”",“','
- 可通过 html 标头仅允许通过单独的文件加载 js 或 css, 避免被注入标签执行恶意代码
- SQL 注入 利用 sql 语法注入代码并执行语句,类似字符逃脱,永远不要相信用户的输入,需要转义整个用户输入信息
- 现代常用的防止 sql 注入方法:预制 sql 模板,部分信息接收用户输入前必须转义输入
- 命令 注入 攻击是一种对底层系统本身发出命令的攻击。
- 如果命令从用户输入传递到命令行,效果可能是灾难性的。需要阅读编程语言系统接口的文档了解如何转义
- 不要相信 html 部分的验证,通过开发者工具可以随时更改,验证应该在服务端进行
- 跨站点请求伪造 / CSRF 诱骗用户在另一个网站上执行命令,如伪造一个亚马逊网站,用户点击网站购买的请求被攻击者转发给亚马逊,在此过程中攻击者可以得到受害人和亚马逊之间的所有收发数据
- 防止此类攻击的一种方法是使用 CSRF 令牌 ,其中服务器为每个用户生成一个凭证令牌,令牌无法验证通过的请求是非法的
- 令牌通常通过 HTML 标头提交。
- 任意代码执行 ( ACE )是执行不属于软件内预期代码的代码的行为。有时,此类攻击可用于 破解 或绕过注册或支付软件费用的需要或者逆向工程
- 应用程序商店采用加密技术,仅接受由授权开发人员签名的软件或代码。作为回应,应用程序商店使用数字签名对软件进行签名。因此,操作系统可以确保只安装经过授权、签名的软件。
- 包管理器 采用类似的签名机制来确保您从第三方下载的内容是值得信赖的。但是,上游开源软件仍是有可能注入恶意代码的
- common vulnerabilities and exposures or CVE 是全球开发者可以查看的漏洞表,使其进行安全维护并确认安全优先级
隐私安全
- 浏览历史记录既是一种功能,也是对隐私的潜在威胁
- 服务器通常具有 用户活动日志 。因此,即使您清除浏览器历史记录,服务器也会跟踪您访问过的内容
- 当你通过 href 标签访问链接时,浏览器默认向跳转网站提供将您引向该网站的链接,也就是跳转到的网站的来源信息,包括您之前进行的搜索即搜索内容等来源
- 可以将以下元标记添加到您的网站,以限制仅发送来源域名或不提供来源信息。更多相关元标记可自行谷歌
1 | <meta name="referrer" content="origin"> |
- 每个浏览器都会提供有关您的身份和行为的信息,无论您选择哪种浏览器,服务器都会记录您的活动。
- 指纹识别 是第三方可以根据可用线索识别您身份的一种方式,即使您已限制浏览器共享尽可能少的有关您的信息。
- 您的 IP 地址,屏幕分辨率、安装的扩展、安装的字体,常用语言,可以被逐渐收集,让您越来越容易被识别
- Session cookie 是服务器放置在您的计算机上用于识别您身份的信息,每个会话编号对于每个用户来说都是唯一的,通常有过期时间
- 第三方使用追踪 cookie 来跟踪您在网站上的行为,例如设定将这个 cookie 信息发给每个你访问的网站
- url 中可以设置特殊参数来追踪用户, 如
https://example.com/ad_engagement?click_id=YmVhODI1MmZmNGU4&campaign_id=23中click_id用户追踪用户, 因此浏览器越来越倾向于清理跟踪参数 - 第三方(即其他服务器或公司)想要了解您如何在网站之间移动,例如在 a 网站的第三方广告设置一个 cookie, b 网站也有这个广告,发现你的 cookie,说明访问 ab 网站的事同一个用户
- 保护您的活动的一种方法是 私密浏览 。
- 在私人浏览窗口或选项卡中,过去的 cookie 将被删除。但新的 cookie 依旧可以生效
- 无论谁为您提供互联网服务,都可以在您不知情的情况下将他们自己的 cookie 注入到您的 HTTP 标头中
- 域名系统 DNS 是 一种服务将域名转化为特定 ip 地址,按照惯例,到 DNS 的流量完全未加密。因此,您正在向全世界宣布您正在尝试访问哪个网站,您的互联网服务提供商和 DNS 服务确切地知道您尝试访问的位置
- DNS over HTTPS 或 DoH 以及 DNS over TLS 或 DoT 是您可以加密 DNS 请求的服务
- Tor 是一款将您的流量重定向到 Tor 服务器节点的软件。流量通过许多加密节点进行引导。根据设计,该软件不会记住您的大部分活动。使用此类服务很可能无法识别您的身份。
- 但请注意,如果您是工作地点或学校本地网络上唯一使用 Tor 的人,则很可能通过其他方式识别您的身份。
- 基于位置的服务 提供您的地理位置。最好记住,如果您向 Apple 地图和 Google 地图提供此类权限,它们就非常清楚您在任何给定时间所在的位置
- 没有任何技术可以为您提供绝对的保护。
人工智能
搜索 search
常见的搜索问题可由以下成分组成:
- 问题状态
- 行动
- 代理人: 采取行动的实体
- 转换模型: 给出一对给定状态和行动产生的新状态
- 状态空间: 通过任何操作序列从初始状态可到达的所有状态的集合
- 目标测试: 判断是否已经达成目标
- 路径成本
经典的搜索算法: dfs, bfs(略)
- 非穷举情况下 dfs 无法保证最优解
- bfs 保证最优解
贪心最佳优先搜索:
bfs 和 dfs 都是无信息算法,实际情况下,我们可以估计哪种搜索行动更优,例如曼哈顿距离(当前位置和目标在 x, y 轴距离的绝对值之和)更少的行动优先进行
这种估算称为启发式函数,一般不保证最优
A star 算法:
- 不仅考虑 h(n) (从当前位置到目标的估计成本),还考虑 g(n) (直到当前位置为止累积的成本)
- 如果估计成本 h(n) +g(n) 超过某个先前选项的估计成本,这条路径就会被放弃
- 为了使这种搜索最佳,需要:
- 估计成本小于等于真实成本
- 新节点到目标的估计路径成本+从前一个节点转移到该新节点的成本大于或等于前一个节点到目标的估计路径成本,即若 n'是 n 的后继节点且 c 是 n'到 n 的成本,h(n) ≤ h(n’) + c (确保在扩展新节点时, 不会选择比已有路径更差的路径)
- 根据以上条件,算法将优先向估计成本(实际成本上界)最小的方向逼近
对抗性搜索 Adversarial Search
在这种搜索中算法面临着试图实现相反目标的对手。通常,在一些竞技游戏里会有对抗性 ai,例如井字棋
极小极大: 将获胜条件表示为一侧 (-1) 和另一侧 (+1), 最小化一方试图获得最低分数,最大化一方试图获得最高分数
- S₀ :初始状态(一个空的 3X3 板)
- Players(s) :一个函数,给定状态 s ,返回轮到哪个玩家(X 或 O)
- Actions(s) :一个函数,给定一个状态 s ,返回该状态下的所有合法动作(棋盘上哪些位置是空闲的)
- Result(s, a) :一个函数,给定状态 s 和操作 a ,返回一个新状态。
- Terminal(s) :一个函数,给定状态 s ,检查是否有人获胜或平局, 有则返回 True , 否则返回 False
- Utility(s) : 一个函数, 给定最终状态 s ,返回该状态的效用值:-1、0 或 1
用伪代码表示,Minimax 算法的工作原理如下:
- 给定一个状态 s
- 最大化玩家 : 在 Actions(s) 中选择产生 Min-Value(Result(s, a))值最高的动作 a
- 最小化玩家 : 在 Actions(s) 中选择产生 Max-Value(Result(s, a))值最低的动作 a
- Function Max-Value(state)
- v = -∞
- if Terminal(state): return Utility(state)
- for action in Actions(state): v = Max(v, Min-Value(Result(state, action))); return v
- Function Min-Value(state):
- v = ∞
- if Terminal(state): return Utility(state)
- for action in Actions(state): v = Min(v, Max-Value(Result(state, action))) ; return v
Alpha-Beta 修剪 Alpha-Beta Pruning
- Alpha 表示当前玩家(最大化玩家)可以确保获得的最小值
- Beta 表示当前玩家的对手(最小化玩家)可以确保获得的最大值
跳过一些明显不利的递归计算。在确定一个行动的价值后,如果有证据表明接下来的行动可以使对手获得比目前所知的最好行动使我方更差的行动机会,则无需进一步调查该行动,因为它肯定会不如先前的行动
这说起很绕,其实可以这么理解,minimax 博弈假定双方都是理性者,并有全局视野,我们可以对手下一步的行动策略评估目前的行动(因为对手的策略必然是让我们赢面最小化), 因此我们可以多判断一步哪个选择后对手可以让我们赢面更低,然后丢弃这个选择
例如下图中,23 选择看上去很好,但之后对手可以选一个更差的值,因此不如 1
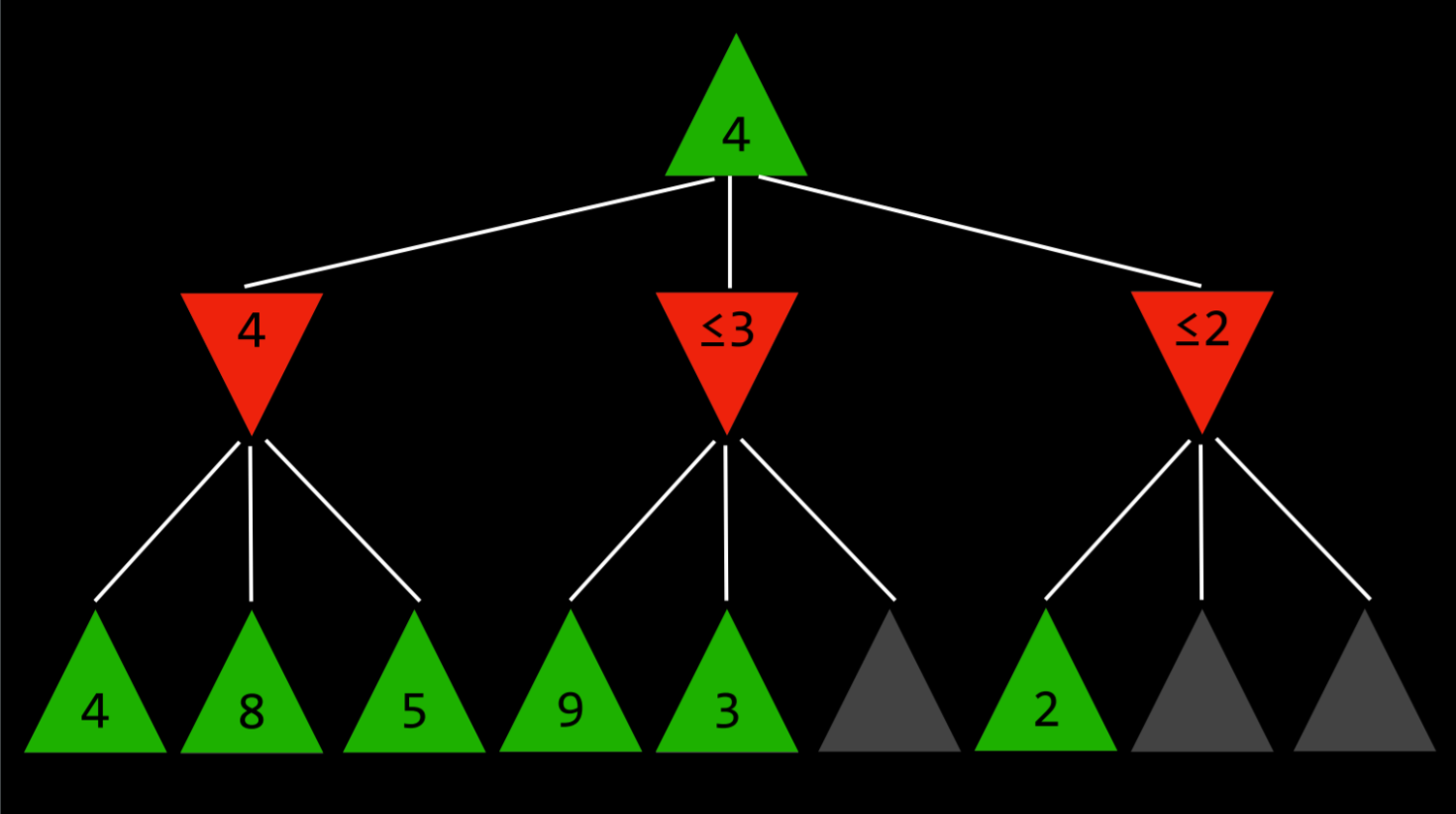
深度限制 Depth-Limited Minimax
设置一定的深度限制,到达限制就退出计算,并通过一个评估函数计算一名玩家相对于另一名玩家的有利程度
知识 knowledge
ai 使用逻辑来分析总结知识,关于世界的知识却体现在各种命题的真值中 命题 P→Q 表示若 P 必然有 Q,若非 P 对任何 Q 成立
| P | Q | P → Q |
|---|---|---|
| false | false | true |
| false | true | true |
| true | false | false |
| true | true | true |
| P | Q | P ↔︎ Q |
|---|---|---|
| false | false | true |
| false | true | false |
| true | false | false |
| true | true | true |
如果 α ⊨ β (α 蕴涵(Entailment) β),那么在任何 α 为真的世界中,β 也为真
eg: 如果 α:“这是一月的星期二” 并且 β:“这是星期二”,那么 α ⊨ β
与 → 不同的是:→ 表示命题之间的逻辑连接,与其连接的 PQ 组合成一个新的命题;⊨ 表示命题间的关系,在语义上可以表示为两个信息集合之间的关系
推理 Inference
最简单的推理方法莫过于穷举一个模型内所有条件的搭配,
如下图:
| P | Q | R | KB |
|---|---|---|---|
| false | false | false | false |
| false | false | true | false |
| false | true | false | false |
| false | true | true | false |
| true | false | false | false |
| true | false | true | true |
| true | true | false | false |
| true | true | true | false |
根据此表可确认 KB ⊨ R
对逻辑的代码表示
1 | from logic import * |
check_all 函数是递归的。也就是说,它选择一个符号,创建两个模型,其中一个该符号为真,另一个该符号为假,然后再次调用自身,现在有两个模型,两者真值分配不同。循环直到模型中的所有符号都被分配了真值即 symbols 为空
知识工程 Knowledge Engineering
知识工程是关于如何在人工智能中表示命题逻辑 Propositional Logic 的过程
假设我们有三个人:Mustard、Plum 和 Scarlet,三种工具:小刀、左轮手枪和扳手,以及三个地点:舞厅、厨房和图书馆,需要推理 when who how 三个问题
游戏一开始,每个玩家都会看到一个人、一件工具和一个地点,从而知道他们与谋杀案无关。玩家不会分享在这些卡片中看到的信息
1 | # Add the clues to the KB |
考虑以下示例:四个不同的人,吉德罗、波莫娜、密涅瓦和霍勒斯,被分配到四个不同的学院:格兰芬多、赫奇帕奇、拉文克劳和斯莱特林。每栋房子里只有一个人
假设使用命题逻辑,我们将编写:
(密涅瓦·格兰芬多 → ¬ 米勒娃·赫奇帕奇) ∧ (密涅瓦·格兰芬多 → ¬ 米勒娃·拉文克劳) ∧ (密涅瓦·格兰芬多 → ¬ 米勒娃·斯莱特林) ∧ (密涅瓦·赫奇帕奇 → ¬ 米勒娃·格兰芬多)…
面对较为复杂的问题,一阶逻辑是另一种类型的逻辑,可以让我们比命题逻辑更简洁地表达更复杂的想法, 使用两种类型的符号: 常量符号 和 谓词符号 Constant Symbols and Predicate Symbols 我们可以使用 Person(Minerva) 句子来表达 Minerva 是一个人的命题。类似地,我们可以使用句子 House(Gryffindor) 来表达格兰芬多是一所房子的命题
谓词符号还可以采用两个或多个参数并表达它们之间的关系。例如,BelongsTo 表达两个参数(人和该人所属的房屋)之间的关系, 米勒娃属于格兰芬多的想法可以表达为 BelongsTo(米勒娃,格兰芬多)
量化是一种可以在一阶逻辑中使用来表示句子的工具,而无需使用特定的常量符号。通用量化使用符号 ∀ 来表达“对于所有人”
存在量化用于创建对至少一个 x 成立的句子。用符号 ∃ 表示
存在量化 Existential Quantification 和全称量化 Universal Quantification 可以在同一句话中使用。例如,句子 ∀x。 Person(x) → (∃y.House(y) ∧ BelongsTo(x, y)) 表达了这样的想法:如果 x 是一个人,则至少有一个房子 y 是这个人所属的。换句话说,这句话的意思是每个人都至少属于一所房子
Mastermind 游戏
在这个游戏中,玩家一按照一定的顺序排列颜色,然后玩家二必须猜测这个顺序。每回合,玩家二进行猜测,玩家一给出一个数字,表明玩家二猜对了多少种颜色,假设有四个颜色需要猜测

用命题 red0、red1、red2、red3、blue0… 代表颜色和位置,用命题逻辑表示游戏规则(每个位置只有一种颜色并且没有颜色重复)并将它们添加到知识库中,随后不断补充线索,随后模型检查算法可以为我们提供难题的解决方案
推理规则 Inference Rules
模型检查不是一种高效的算法,因为它必须在给出答案之前考虑每个可能的模型
推理规则使我们能够根据现有知识生成新信息,而无需考虑每种可能的模型
假设:
- 如果下雨,那么哈利在屋子里
- 正在下雨
基于此,理性的人都可以得出这样的结论:
- 哈利在屋里
一些基本的推理规则: 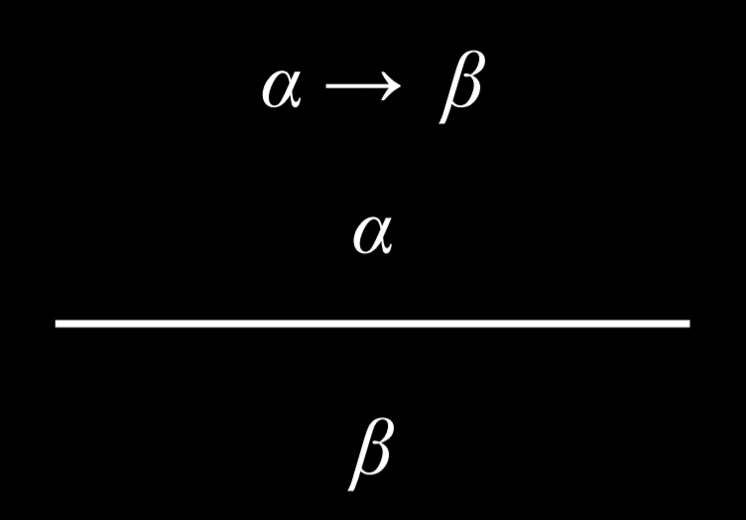
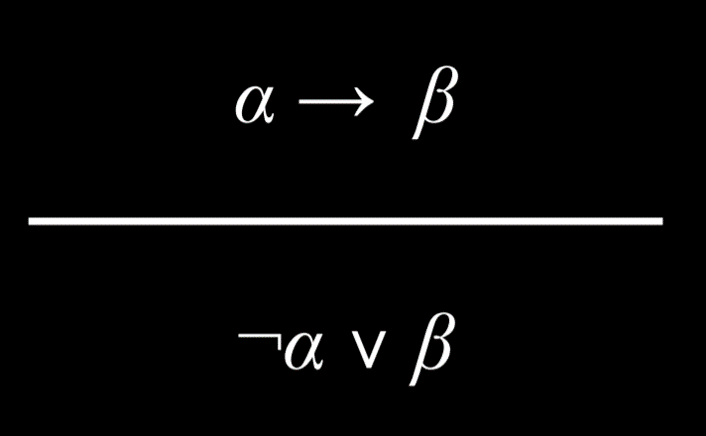
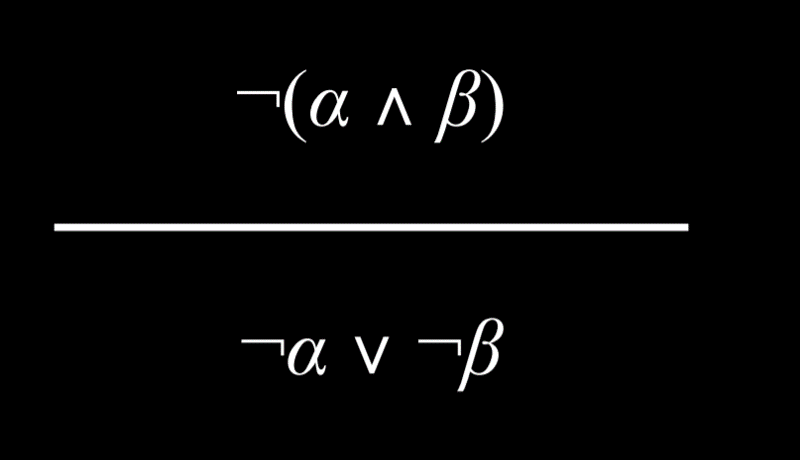
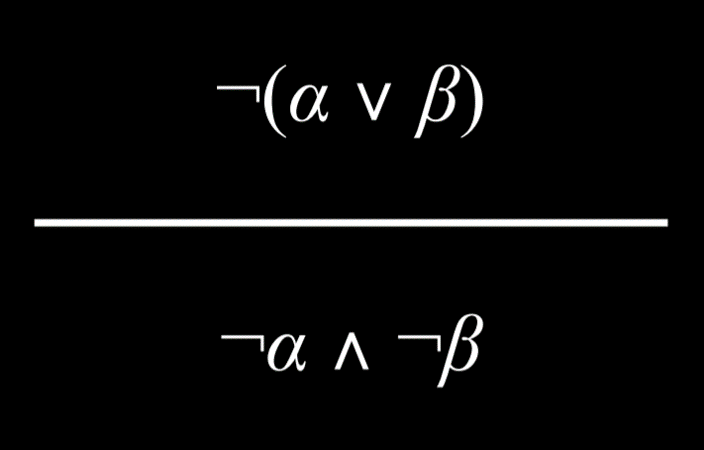
具有用 And 或 Or 连接词分组的两个元素的命题可以分解为由 And 和 Or 组成的更小的单元
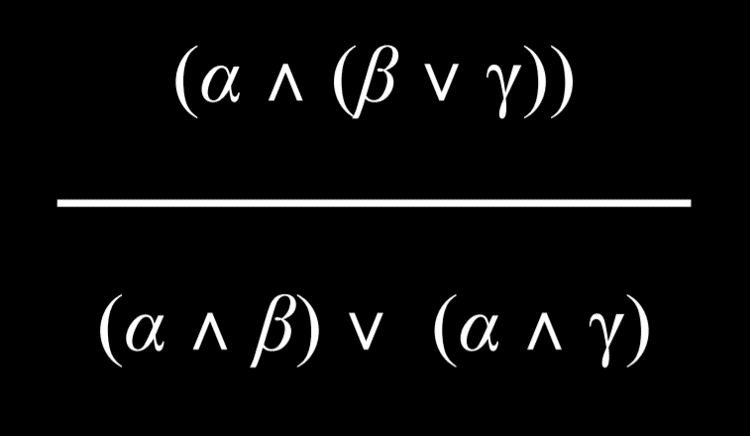
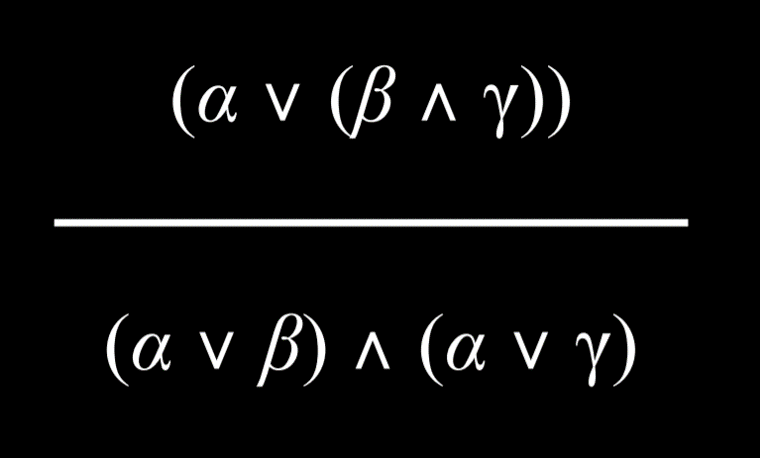
推理可以被视为具有以下属性的搜索问题:
- 初始状态:启动知识库
- 动作:推理规则
- 转换模型:推理后的新知识库
- 目标测试:检查我们要证明的语句是否在知识库中
- 路径成本函数:证明中的步骤数
析取 disjunction 由与 Or 逻辑连接词连接的命题组成, 子句 clause 是对文字 literals (命题符号或命题符号的否定)的析取, 如 (P ∨ Q ∨ ¬R)
由 And 逻辑连接词 (P ∧ Q ∧ R) 连接的子句允许我们将任何逻辑语句转换为 合取范式 (CNF Conjunctive Normal Form),即子句的合取,例如:(A ∨ B ∨ C) ∧ (D ∨ ¬E) ∧ (F ∨ G)
求合取范式的过程:
- 消除双条件句
- Turn (α ↔︎ β) into (α → β) ∧ (β → α).
- 消除条件句
- Turn (α → β) into ¬α ∨ β.
- 使用德摩根定律,将否定向内移动
- Turn ¬(α ∧ β) into ¬α ∨ ¬β
将 (P ∨ Q) → R 转换为合取范式的示例:
- (P ∨ Q) → R
- ¬(P ∨ Q) ∨ R
- (¬P ∧ ¬Q) ∨ R
- (¬P ∨ R) ∧ (¬Q ∨ R)
得到的合取范式可以继续简化,如(P ∨ Q ∨ S) ∧ (¬P ∨ R ∨ S) 可化为 (Q ∨ R ∨ S)
要确定 KB ⊨ α 是否为真:
- 检查:(KB ∧ ¬α) 是否矛盾?
- 如果是这样,则 KB ⊨ α
- 否则,无蕴涵关系
就计算机算法而言,可使用以下步骤:
- 将 (KB ∧ ¬α) 转换为合取范式
- 检查是否可以生成新的子句
- 如果产生空子句(相当于 False),那么得出矛盾,从而证明了 KB ⊨ α
- 然而,如果没有矛盾并且不能推断出更多的子句,则不存在蕴涵
示例:(A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) 是否蕴含 A?
- 首先,为了反证,我们假设 A 是假的。因此,我们得到 (A ∨ B) ∧ (¬B ∨ C) ∧ (¬C) ∧ (¬A)
- 现在,我们可以开始生成新信息。因为我们知道 C 是假的 (¬C),所以 (¬B ∨ C) 为真的唯一方法是 B 也为假。因此,我们可以将 (¬B) 添加到我们的知识库中
- 接下来,由于知道 (¬B),所以 (A ∨ B) 为真的唯一方法是 A 为真。因此可以将 (A) 添加到知识库中
- 现在我们的知识库有两个互补的文字:(A) 和 (¬A)。抵消得到空集()。根据定义,空集是假的,因此遇到了矛盾
概率 Uncertainty
0 <p( ω )<1:代表概率的值必须在 0 到 1 之间。零是不可能的事件, 如扔 1-6 的骰子扔出 7。
p(a|b) 表示给定 b 条件下 a 的概率
可以用向量表示一系列事件的概率,如 P(Flight) = <0.6, 0.3, 0.1> (准时,延误,取消)
概率规则:
- P(¬a) = 1 - P(a)
- P(a ∨ b) = P(a) + P(b) - P(a ∧ b)
- P(a) = P(a, b) + P(a, ¬b)
- 独立性: P(a ∧ b) = P(a)P(b)
- 贝叶斯: P(a|b) = P(a ∧ b)P(b) 其中: P(a ∧ b)= p(a|b)p(b)
联合概率 Joint Probability:多个事件同时发生的概率
| C = cloud | C = ¬cloud |
|---|---|
| 0.4 | 0.6 |
| R = rain | R = ¬rain |
|---|---|
| 0.1 | 0.9 |
| R = rain | R = ¬rain | |
|---|---|---|
| C = cloud | 0.08 | 0.32 |
| C = ¬cloud | 0.02 | 0.58 |
联立不同条件的情况下, P(C, rain) = P(C ∧ rain),P(C | rain) = P(C ∧ rain)/P(rain)
此时,可写作 P(C, rain)/P(rain) = αP(C, rain), 或 α <0.08, 0.02> ,即规定 rain 的情况下 c 的分布,我们知道 c 的所有分布和为 1,因此需要一个 α 系数将其化 1
贝叶斯网络:
- 用定向图表示
- 图上的每个节点代表一个随机变量
- 从 x 到 y 的箭头表示 x 是 y 的父节点。也就是说,y 的概率分布取决于 x 的值
- 每个节点 X 具有概率分布 P(X | Parents(X))
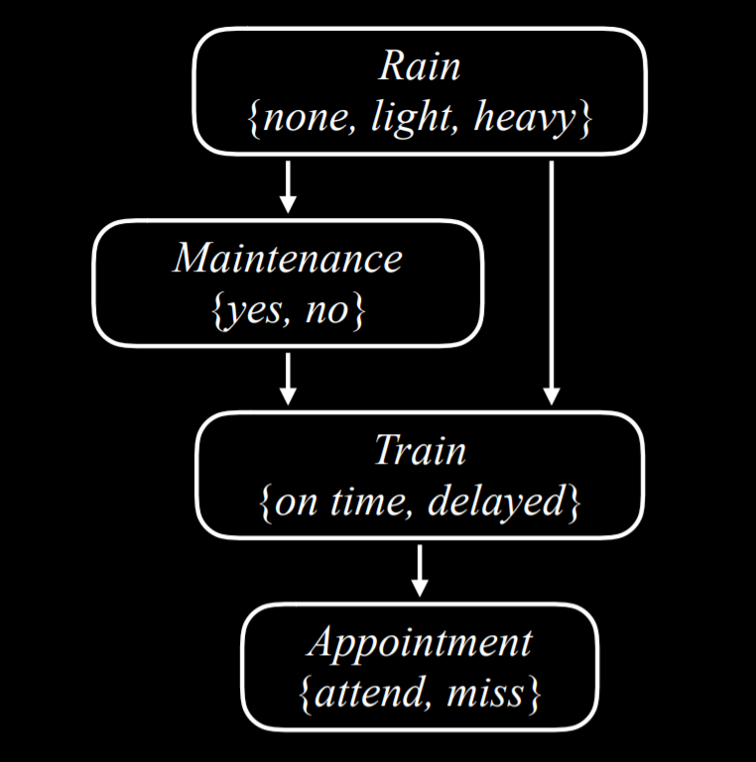
例如,如果想得到 P(小雨, 不维护,列车推迟,错过会议),就可以通过 P(light)P(no | light)P(delayed | light, no)P(miss | delayed)得到
实际情况中,部分变量可能难以观察到
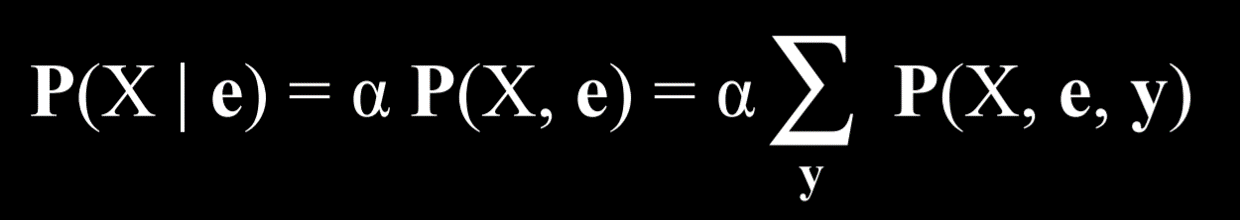 如图,X 是被观察的变量,e 是可见的证据,y 则是隐藏变量的所有可能取值,α 归一化结果,使最终得到的概率总计为 1
如图,X 是被观察的变量,e 是可见的证据,y 则是隐藏变量的所有可能取值,α 归一化结果,使最终得到的概率总计为 1
例如 P(Appointment, light, no) = α [P(Appointment, light, no, delayed) + P(Appointment, light, no, on time)]
因此,在不知道 y 的分布情况下也可以根据 e 进行分布推断
采样 Sampling
通过对一个变量多次采样,可以估算其概率分布,如果想得到例如 p(a|b)的概率,可以简单地用 p(a)/p(b)估算,对非 b 条件的情况可以直接忽略
也可以计算基于附加变量的概率分布,固定证据变量 a,使用贝叶斯网络中的条件概率对非证据变量加权,例如,例如 a 是列车准时(直接赋予 on time 这个值),对所有样本按贝叶斯网络加权,如小雨且维护的样本需要加权 P(Train = on time | light, yes)
马尔可夫模型 Markov Models
马尔可夫假设: 当前状态只取决于以前有限个且固定个的状态
马尔可夫链是一个随机变量的序列,其中每个变量的分布遵循马尔可夫假设。也就是说,链中的每个事件都基于之前事件发生的概率
![]()
隐马尔可夫模型 Hidden Markov Model:现实世界有很多无法被观察的变量影响发生的事件,在这些情况下,世界状态称为隐藏状态 ,而 AI 可以访问的数据是观察结果,基于这个假设的马儿可夫模型
例如:
- 对于探索未知地形的机器人,隐藏的状态是其位置,观察对象是机器人传感器记录的数据。
- 在语音识别中,隐藏状态是所说的单词,观察对象是音频波形。
- 评估用户在网站上的参与度时,隐藏的状态是用户的参与度,并且观察对象是网站或应用存储的数据。
传感器马尔可夫假设 Sensor Markov assumption:证据变量仅取决于相应状态的假设。例如,上方例子假设人们是否将雨伞带到办公室仅取决于天气,人们可能的其他特点(例如皮肤不好不能晒太阳)则是隐藏状态,并不被纳入考虑 假设 ai 想观测天气,但传感器只有一个监控器可以判断人们有没有带伞, 通过观察人们是否带来了雨伞,可以合理猜测外面的天气 
通过对证据变量的记录和学习,可以推测过去,现在,未来的隐藏变量状态
优化 Optimization
优化是从一组可能的选项中选择最佳选项。
例如曼哈顿距离就是计算当前位置与目标点 xy 坐标差的绝对值之和来估计成本,而 a star 算法通过这种估计来优先选择下一个可能路径
本地搜索 Local Search 是一种搜索算法,它通过维护当前节点的属性,然后移动到相邻节点,重复直到搜索到一个满意的状态。例如给定一些房屋位置,要为新建的医院选址,让距离和最短
爬山 Hill Climbing 算法 :一种本地搜索,给定当前状态,寻找一个最佳邻居状态,若这个邻居比当前更优,转移到邻居,如此循环。最后会到达一个极值
问题在于,极值未必是最大值,且如果两个邻居和当前一样,算法什么都不会做
改进:以随机初始状态重复几次,或者每次可以选 k 个邻居进行比较(k >= 2)
退火是使被加热的金属缓慢冷却的过程,这可以使金属变硬。模拟退火 Simulated Annealing 算法指的是:从高温开始,更有可能做出随机决策,并且随着温度降低,越来越不可能做出随机决策
算法有一个 max 参数规定最多可以比较的次数,t 函数每次返回一个温度值,温度初期较高,逐渐降低,ΔE 表示目前和邻居状态的差值,大于 0 是直接移到邻居位置,否则以 e^(ΔE/T)的概率移动。即温度和状态差同时影响移动概率
线性编程 Linear Programming :给定若干元 x1-xn, 以及成本系数 a1-an, 元之间的若干约束,计算最低成本的取值,对其的优化可以使用 Simplex 算法和 Interior-Point 算法(牛顿迭代)
约束满足 Constraint Satisfaction
约束满意度问题:在满足某些条件的同时分配变量 例如:学生学习的课程有 A,B,…,G 都是变量。每个课程都需要考试,考试的可能日子是星期一,星期二和星期三,也就是变量的域。但是,同一学生不能在同一天进行两次考试。在这种情况下,变量是课程,域是日子,而限制是不能安排在同一天进行考试的限制因素

图上的每个节点都是一门课程,如有两门课不能安排在同一天,就添加一条弧
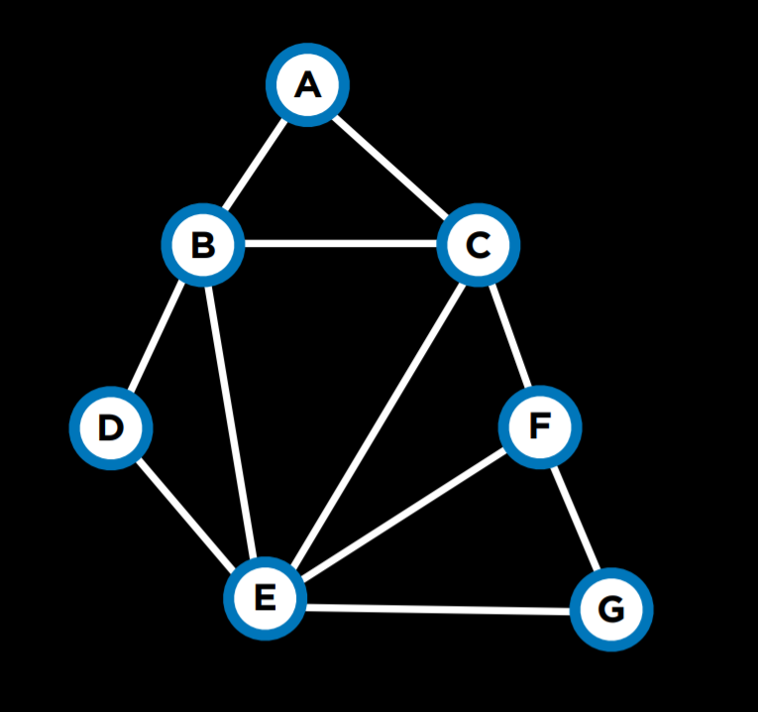
- 硬约束:在正确解决方案中必须满足的约束。
- 软约束:表示解决方案的优劣性
- 单元约束:仅涉及一个变量的约束。如课程在星期一不能进行考试{ a≠ 星期一 }。
- 二元约束: 涉及两个变量的约束。如两个课程不能具有相同的值{ a≠b }。
节点的一致性(Node Consistency): 某个变量在变量域中所有取值都可以满足对该变量的一元约束,例如对变量课程 a, b 来说,其域是星期一二三,{A ≠ Mon, B ≠ Tue, B ≠ Mon, A ≠ B},此时 ab 都没有变量一致性,因为 ab 的取值都定死了,如果移除 A ≠ Mon, a 就会有一致性,如果要让 b 也有一致性,就需要移除周二周三两个约束
弧的一致性(Arc Consistency): 某个变量在变量域中所有取值都可以满足对该变量二元约束,即对每个 a 至少有一个 b 取值满足 ab 间约束关系,类似节点一致性,在上个例子中,如果 a 取周三,b 将无法取值,因此需要移除 a!= b 约束,移除后 a 就有了弧一致性
以下算法通过移除 x 无法满足二元约束的取值来保证 x 的弧一致性(最坏情况下会删掉 x 所有的取值范围),换句话说就是找到二元约束下 x 能取的值:
1 | function Revise(csp, X, Y):#CSP 代表“约束满意度问题” |
一般来说,我们会希望能让每个变量都有弧一致性,因此需要使用 ac-3 算法
1 | function AC-3(csp): |
弧一致性的算法可以简化问题,但不一定会解决问题,因为它仅考虑二元约束,而不是如何互连多个节点。
约束满意度问题可以看作是一个搜索问题:
- 初始状态:空任务(所有变量都没有分配给它们的任何值)。
- 操作:向分配添加{ variable = value }; 也就是说,给一些变量一个值。
- 过渡模型:显示添加分配的方式如何改变整个任务。返回包括最新动作之后的状态。
- 目标测试:检查是否可以分配所有变量,并满足所有约束。
- 路径成本:所有路径的成本相同。正如我们前面提到的,与典型的搜索问题相反,优化问题关心解决方案,而不是通往解决方案的途径。
回溯搜索 Backtracking Search
用于解决约束满意度问题的递归搜索算法,如果满足约束,继续分配值,否则尝试不同的任务
1 | if assignment complete: |
流程:
- 假设任务完成(变量分配完),直接返回
- 选择一个未分配变量,遍历变量的所有取值
- 如果有一个取值不和之前的约束矛盾, 添加这个取值进当前状态进入递归
- 递归返回后,如果其中的子问题有解,返回结果
- 运行到这步说明这种取值不行,那么移除该取值
- 运行到这里说明所有尝试都失败了,返回失败信息,这说明需要回溯到之前的某个状态,当前是无解的
作为简单粗暴的递归算法,回溯搜索的复杂度很高,考虑到维持弧一致性的成本相对较低,我们可以考虑把 ac-3 算法融合进来,这个算法称为 Maintaining Arc-Consistency algorithm,会在每次新的赋值后维持弧一致性
1 | function Backtrack(assignment, csp): |
优化: 与随机选择一个新变量相比,我们可以用一些经(玄)验(学)法则,说不定有更好的效果, 也就是所谓的启发式 heuristic
- Minimum Remaining Values (最少剩余值 MRV) ,优先选择取值范围最少的变量,这是个很符合直觉的想法,如果这条路会失败,那我们应该尽早排除它,此外,这么一来可以尽可能多地约束其他变量的度数。而当变量的取值范围相同时,自然的想法就是选度数最高的变量赋值
- 当我们从变量的域中选择一个值时,使算法更有效的另一种方法是采用另一种启发式 Least Constraining Values(最少限制值) , 选一个能约束最少其他变量的变量值,也就是说,我们想定位最大的麻烦来源(最高度数的变量),然后使其成为最不麻烦的问题(为其分配最小约束值)
机器学习 Machine Learning
最大的概念,为计算机提供数据,通过学习这些数据让计算机学会识别模式并执行任务
监督学习 Supervised Learning
计算机基于一个函数对数据集进行输入映射到输出的任务,监督学习有多个任务,其中之一是分类,即用函数将输入映射到离散输出的任务
例如输入温度,湿度和气压,输出下雨或者不下雨。
如下图红色代表不下雨,蓝色表示下雨,白色需要映射:
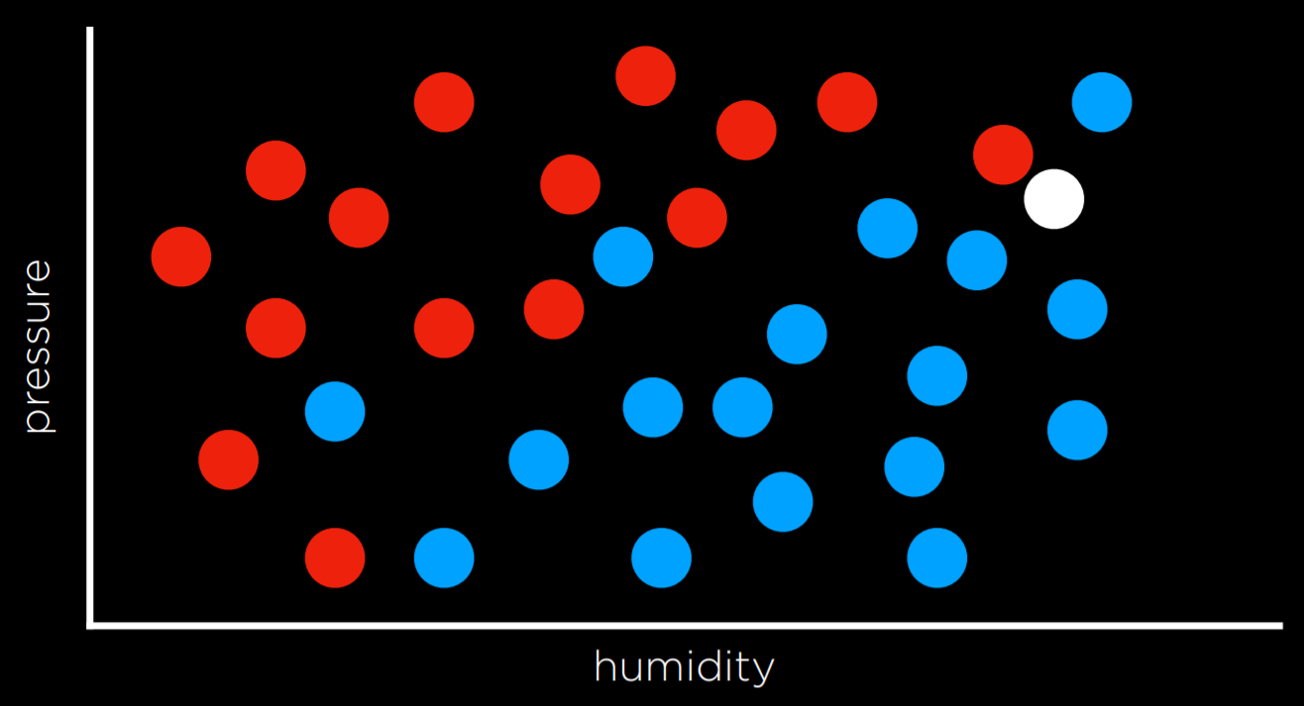
最简单的策略莫过于直接选一个最近点作为输出,即 Nearest-Neighbor Classification,但如上图可能出现不准确问题,对其的改进可以是 k-邻近算法,选 k 个最近点的最多输出作为输出
缺点在于计算距离开销较大
常用的库是 scikit-learn, 常叫 sklearn
感知机学习 Perceptron Learning
简单地说就是画出一条分界线,用来分类或者决策,说起来简单,实际上很难选出最好的分界线
在这个例子里,判断数据在边界哪侧只需要用一个线性方程,属于初中数学范畴,不多赘述
\(\ {h}_{\mathrm{W}}({\bf x})={\begin{array}{l}{1\,\mathrm{if}\;{ W}\ {\cdot\;{\bf X}}\geq0}\\ {0\,\mathrm{otherwise}}\end{array}}\,\)
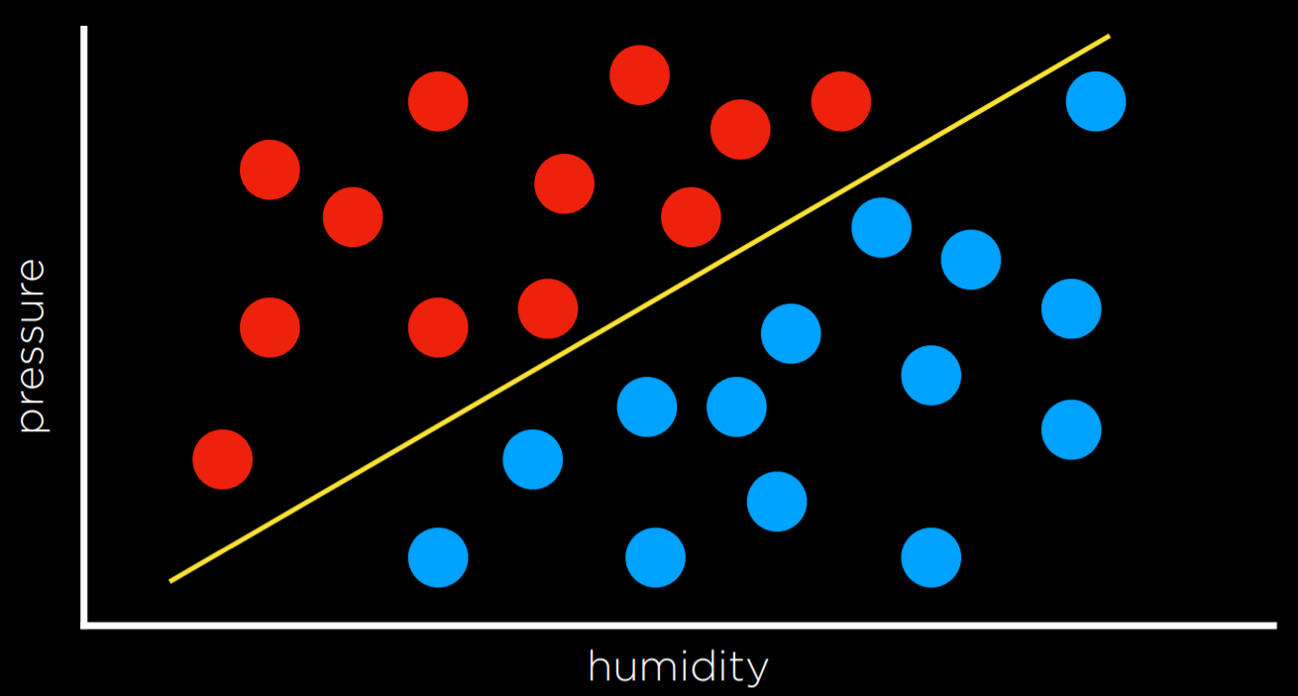
感知机的重点是,找到最好的权重,其学习规则是:
\(w_{i}=w_{i}+α(y-h_{w}({\bf x}))\times x_{1}\)
对于每个数据点,我们调整权重以使函数更加准确,y 表示观察到的值,h(假设函数)表示估计值,如果观察下雨但估计没下,括号里的参数设 1,相反的情况下设-1,α 则表示新数据对总体权值的影响力
这种离散输出模型的缺点是,无法表示不确定性,可以将其平滑化,使用软阈值,最后输出一个估计概率
支持向量机 Support Vector Machines
该方法在决策边界附近使用额外的向量(支持向量),以在分离数据时做出最佳决策。 
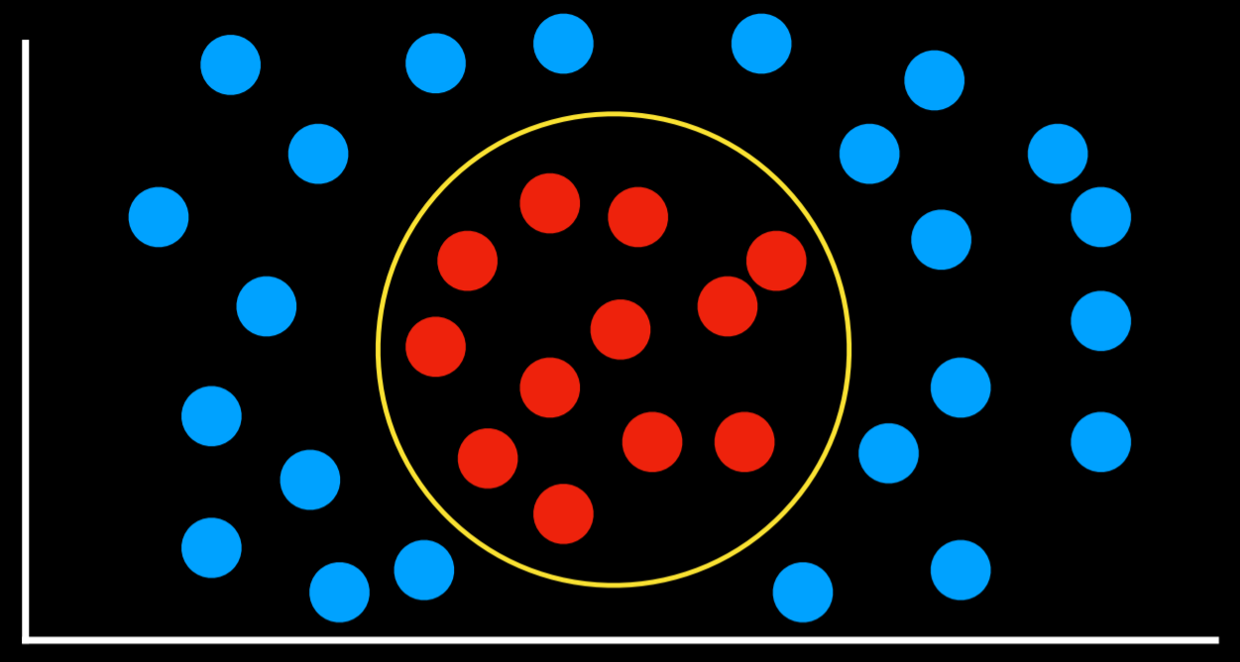
例如, 直觉来说最好的划分应该离两个每个组有相同的距离,即边界离其所分离的两组尽可能远,这被称为最大边缘分离器 Maximum Margin Separator
以及,支持向量机可以在复数维度上创建分界线
回归 Regression
回归是一项函数的监督学习任务,该任务将输入点映射到连续值 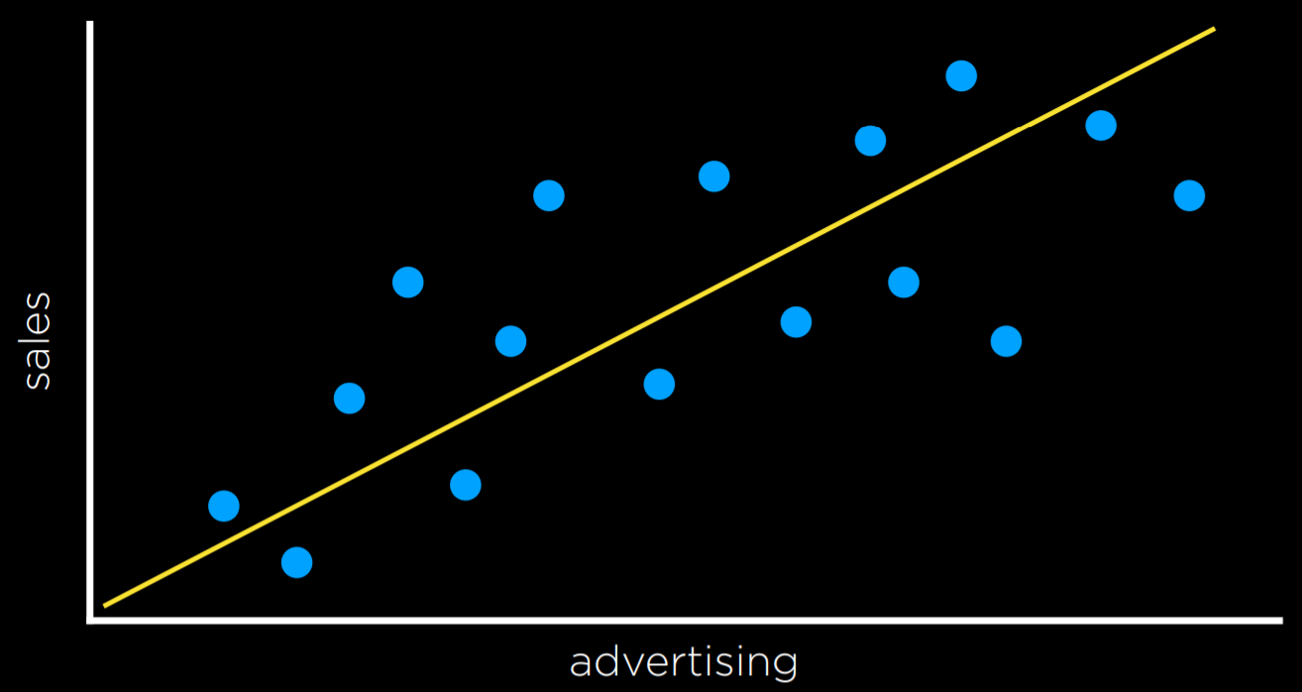 最经典的线性回归在线代课里讲过,简单地说就是找到距离平方和最小的直线来拟合输出
最经典的线性回归在线代课里讲过,简单地说就是找到距离平方和最小的直线来拟合输出
给定一组输入特征 X = [x1, x2, ..., xn] 和相应的目标输出 y。
目标是找到一个线性函数 h(X) = θ0 + θ1 x1 + θ2 x2 + ... + θn*xn 来拟合数据。
其他比较常见的回归有随机森林,决策树等
损失函数 Loss Functions
损失函数用于评估以上决策规则的准确度 对分类问题,可以简单地用 01 二分法;而连续值可以用 l₁ 和 l₂ 损失函数,前者为线性差值的绝对值,在坐标轴上就是 y 轴上的距离,后者为差值平方,很明显,l2 更为严格
过拟合 Overfitting
模型过于适配训练数据集以至于无法推广其他训练集
测试过拟合的常用方法是 交叉验证 Cross Validation, 如最简单的 holdout 交叉验证,只分一次训练和验证集;而 k 折交叉验证就是将训练集分为 k 份,每次选一份用于验证,其他 k-1 份用于训练, 这样一共能验证 k 次
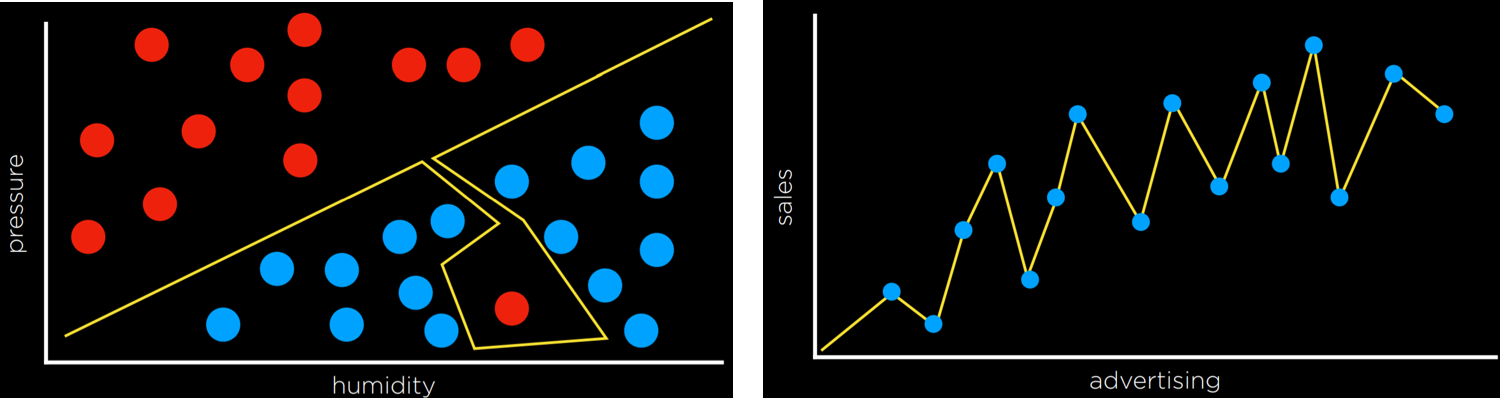
正则化 Regularization
正则化在损失函数中加入一个惩罚项, 降低模型复杂度, 限制模型参数的大小或数量, 从而防止过拟合, 提高模型的泛化能力。
cost(h) = loss(h) + λcomplexity(h)
lambda(λ)是一个常数,我们可以用它来调节对我们成本功能的复杂性的惩罚程度。 λ 越高,复杂性的惩罚越强
常用 l1(Lasso 回归), l2(Ridge 回归) 正则化,即复杂度用权重矩阵绝对值和或平方和表示
一般来说 l1 适合让参数稀疏化(部分权值会被降到 0),适合特征选择;l2 相对会惩罚高权重从而更能防止过拟合(但不会降到 0)
强化学习 Reinforcement Learning
强化学习是一种用于机器学习的方法,在每个动作之后,代理以奖励或惩罚的形式(正值或负值)获得反馈。 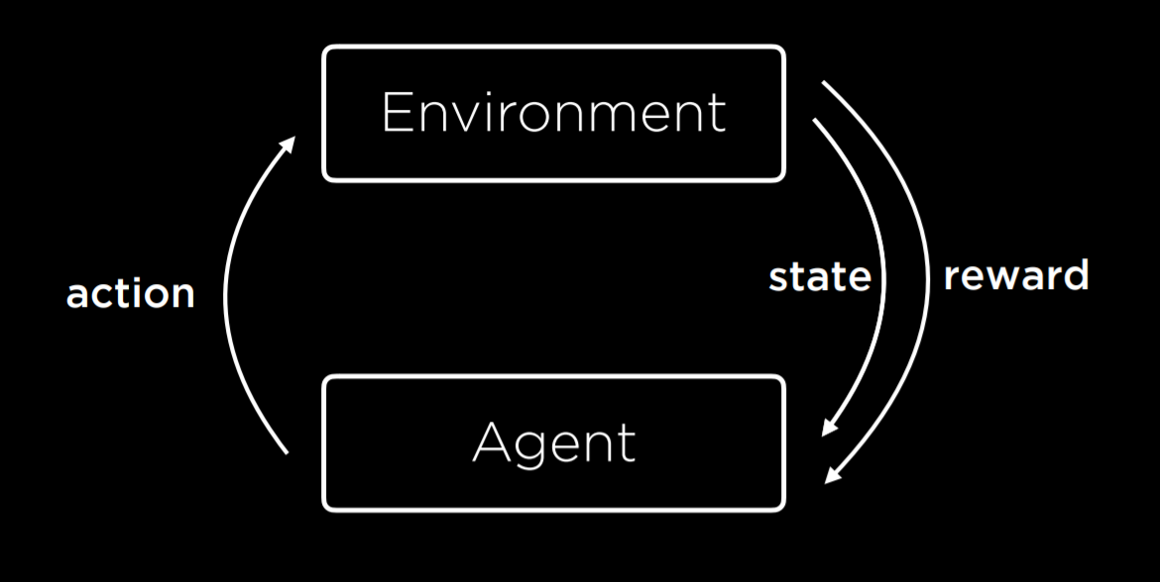 环境为代理提供初始状态,代理根据状态执行行动并不断获得反馈
环境为代理提供初始状态,代理根据状态执行行动并不断获得反馈
这种类型的算法可用于训练步行机器人,例如成功走了一步是正反馈,摔倒是负反馈
马尔可夫决策过程 Markov Decision Processes
强化学习可以看作是马尔可夫决策过程,具有以下属性:
- Set of states S
- Set of actions Actions(S)
- Transition model P(s’ | s, a)
- Reward function R(s, a, s’)
在每个时间步骤中,随机过程都处于某种状态 s,决策者可以选择在状态 s 下可用的动作 a。该随机过程在下一时间步骤会随机进入新状态 s′,并给予决策者相应的回馈 Ra(s, s′)
随机过程进入新状态 s′的概率受所选操作影响。具体来说,它是由状态变换函数 P 给出的。因此,下一个状态 s′取决于当前状态 s 和决策者的动作 a。给定 s 和 a,它条件独立于所有先前的状态和动作
马尔可夫决策过程是马尔可夫链的推广,不同之处在于添加了行动(选择)和奖励(反馈)。
如图,代理是黄色圆圈,它需要到达绿色正方形的同时避开红色正方形。上下左右移动是动作,过渡模型在动作后产生新状态,并且代理会获得反馈
图中代理如果想向右移动,会得到一个负面反馈;到达绿色方形时会得到正面反馈
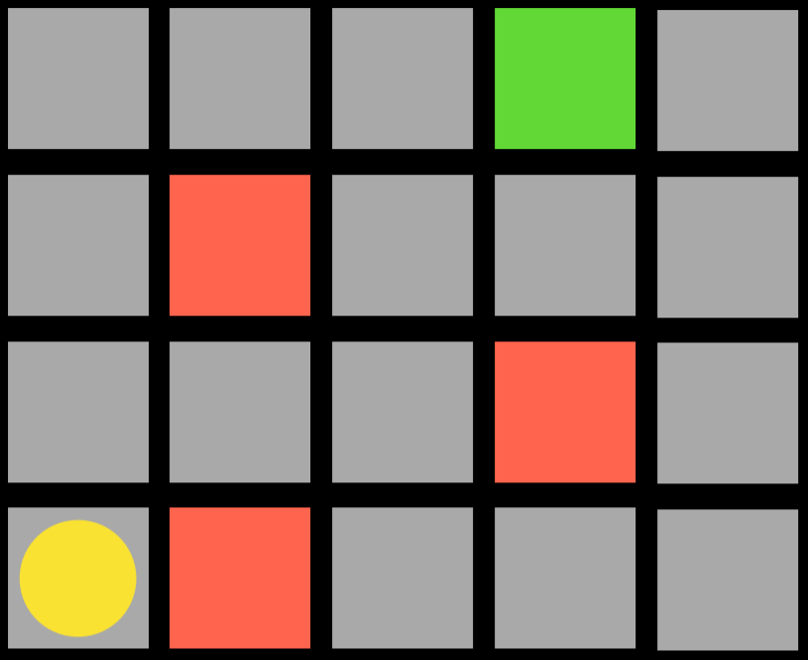
Q 学习 Q-Learning
一种强化学习模型,使用的函数 Q 函数 Q(s, a) 接收 s 状态下的行动 a,并产生对其的一个评估值,注意这个评估值和回馈 r 不同
起初,所有 q 函数的输出为 0,随着模型不断“行动-反馈”的过程,模型不断基于当前状态给出输出,以及不断考虑过往估计与新估计,并以此更新函数规则。即在过程中就可以不断总结经验自我学习。
Q(s, a) ⟵ Q(s, a) + α(new value estimate - Q(s, a))
α 表示调整的权重
那么新的估计怎么产生呢? 可以表述为当前收到的回馈 r 以及估计的未来回馈的(加权)和;模型会记录之前的(状态,回馈)表,估计的未来回馈用最近一次行动后的最新状态,在这个状态下根据过往经验选一个最高回馈,即记录表中 Q(s', a')里的最高值。对未来回馈的估计也可以用一个系数 γ 约束,公式如下:
\(Q(s,a)\leftarrow Q(s,a)+\alpha((r+\gamma\,\mathrm{max}_{\mathrm{a'}}\!\cdot\!\mathrm{Q}(s^{\prime},\,{\mathrm{a}}^{\prime}))-\mathrm{Q}(s,a))\)
例如对某个(s, a)对, 其 r 值直接查表得到,这个 a 后得到一个新状态 s',查表 s'状态下最好的 r,我们假设之后的新行为 a'能得到这个最好的 r,因此以此来更新 Q 函数
贪婪决策算法 Greedy Decision-Making 总是选取估计回馈最好的行动,而不是根据状态选出 Q(s, a)最好的行动,这往往能解决问题,但并非全局最优
总的来说,这可以归类于 Explore vs. Exploit tradeoff,是一个经典的问题。为了避免 exploit 带来的问题,例如限于以往经验不走了,可以对贪心进行改进,以一个概率 ε 决定是否贪心当前最优解,还是选一个随机解,称为 (epsilon) greedy algorithm
训练强化学习模型的另一种方法是,在整个任务完成后才给予评估,而不是每一步。对一些博弈游戏,这样的训练方式可能更有效。
对状态集和动作相对复杂的作业,如国际象棋来说,很难对每个动作进行估计,需要进行函数近似 function approximation,将类似的状态行动队归到一起用于产生估计值
无监督学习 Unsupervised Learning
在无监督的学习中,仅存在输入数据,并且 AI 在这些数据中学习模式,不需要特定输出输出
例如聚类是一项无监督的学习任务,它将输入数据获取并将其组织为不同的组,使类似对象被分入同一组。被用于遗传学之类的领域
K-均值聚类 k-means Clustering
执行聚类任务的算法,用于将数据映射到空间中,起初随机设置 k 个聚类中心在空间里(数量由程序员指定), 各个中心至少一个点。
聚类过程中,每个群里的点都是在所有中心中里所处群中心最近的。完成这样的一次分配后,群中心们会被移到聚类的中心,再迭代一次对各个点的分类,如果某个迭代过程里没有任何点更改自己所处的类,那就完成了任务
神经网络 Neural Networks
AI 神经网络受神经科学的启发。在大脑中,神经元是相互连接的细胞,形成网络。每个神经元都能接收和发送电信号。一旦神经元接收到一定阈值的电输入,神经元就会激活,从而向前发送其电信号。
而人造的神经网络本质上是一种数学模型,由网络状连接起来的数学函数组成,而网络的形状由基于数据的训练形成
每个“神经元”可以视为输入数据和输出数据的映射关系,这也是函数的数学定义,如我们之前提到的预测下雨等任务。
前馈神经网络 feed-forward neural network,是最简单的神经网络,各神经元分层排列,每个神经元只与前一层的神经元相连。本课程里介绍的神经网络大多属于此类(除了该章节提到的循环神经网络)
激活函数 Activation Functions
在神经元中,输入的 input 经过一系列加权求和后作用于另一个函数,这个函数就是激活函数。激活函数最终决定了是否传递信号以及要发射给下一个神经元的内容。
对预测下雨这个离散输出的问题,我们需要某种阈值
例如使用 step function, logistic function(输出连续值表示输出可信度), Rectified Linear Unit (ReLU)(允许任何正值,负数输出强制置 0)
神经网络结构 Neural Network Structure
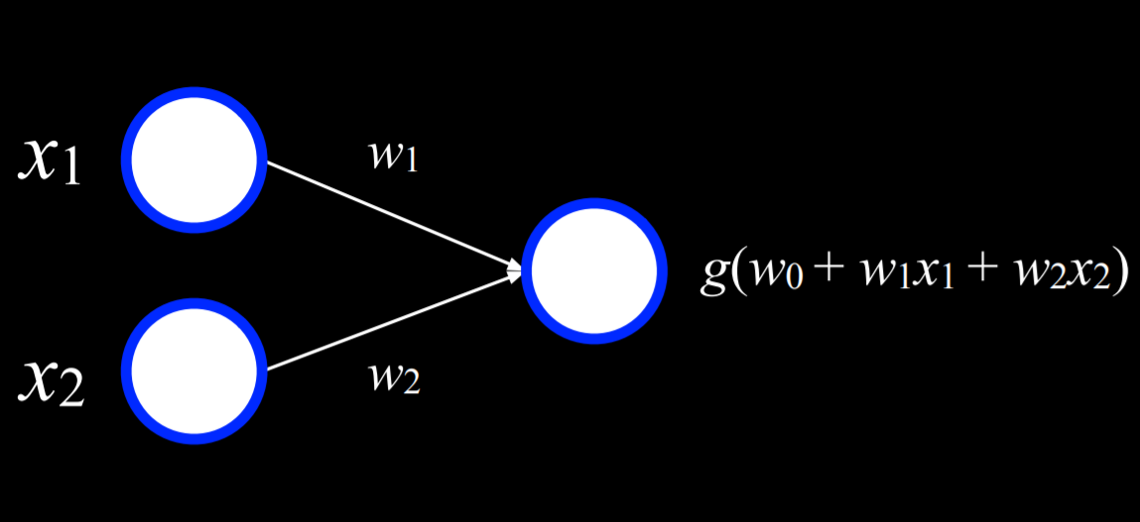 如图,x1, x2 为输出,边附有一个权值 wi, 连接到输出产生 g,这可以视为一个极小的神经网络
如图,x1, x2 为输出,边附有一个权值 wi, 连接到输出产生 g,这可以视为一个极小的神经网络
梯度下降 Gradient Descent
梯度下降是一种在训练神经网络时最小化损失的算法。如前所述,神经网络能够从数据中推断出有关网络本身结构的知识。到目前为止,我们定义了不同的权重,神经网络允许我们根据训练数据计算这些权重。为了更好地找到合适权重,我们使用梯度下降算法,其工作原理如下:
- 从随机选择权重开始
- 重复:
- 根据所有数据点计算梯度,从而减少损失。最终,梯度是一个向量
- 根据梯度更新权重。
根据所有数据计算梯度可能成本较高,为了降低成本,可以使用随机梯度下降 Stochastic Gradient Descent,(根据随机选取的点计算梯度); 小批量梯度下降 Mini-Batch Gradient Descent(基于随机选择的几个点来计算梯度)
当然,输入输出间可以有更复杂的关系,例如根据气压温度等输入给出不同天气的概率, 此时,如下图,每个输入都连接到每个输出,单个输入和任何输出都可以视为一个小规模神经网络,和其他输出分开训练
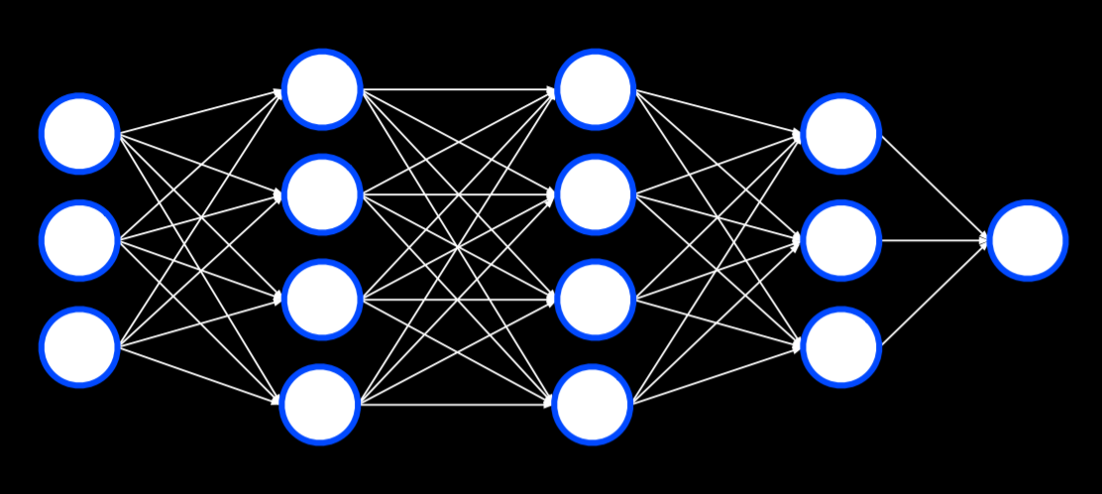
多层神经网络 Multilayer Neural Networks
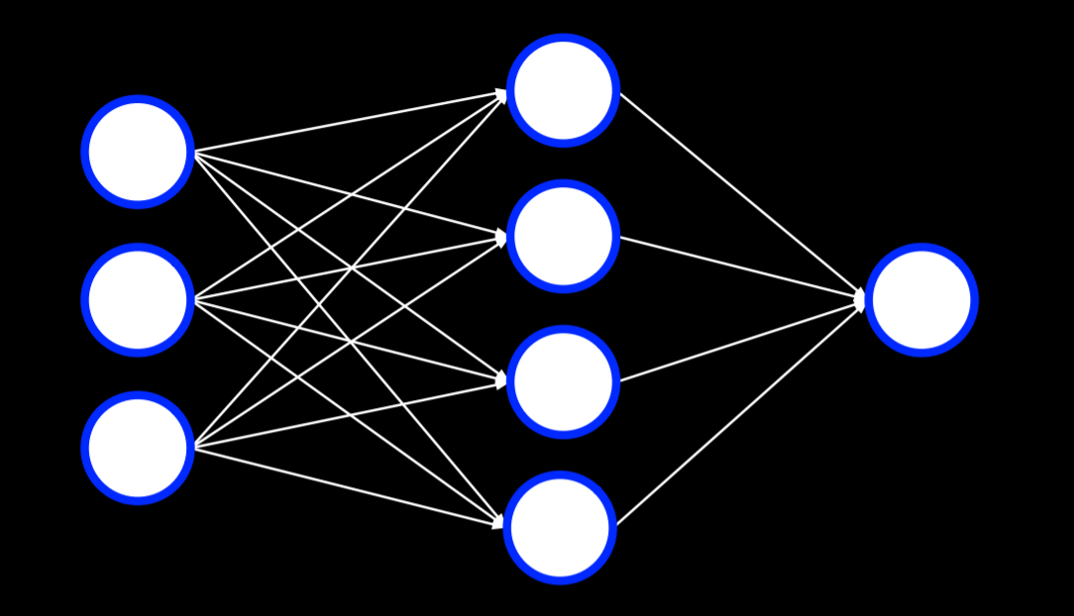
到目前为止,我们的神经网络依赖于 感知器 输出单元。这些单元只能学习线性决策边界,使用直线来分离数据。然而,通常,数据不是线性可分的,在这种情况下,我们转向多层神经网络来对数据进行非线性建模。
多层神经网络是一种具有输入层、输出层和至少一个隐藏层的人工神经网络。
第一个隐藏层中的每个单元从输入层中的每个单元接收加权值,对其执行一些操作并输出一个值。这个过程是自动进行的,不需要人为输入数据。这些值中的每一个都被加权并进一步传播到下一层,重复该过程直到到达输出层。通过隐藏层,可以对非线性数据进行建模。
反向传播演算法 Backpropagation
反向传播是用于训练具有隐藏层的神经网络的主要算法。
通过从输出单元中的误差开始,计算前一层权重的梯度下降,并重复该过程直到到达输入层来实现。
- 计算输出层的误差
- 对于每一层,从输出层开始并向内移动到最早的隐藏层:
- 将误差传播回前一层。换句话说,从当前层将错误发送到前一层。
- 传播的过程中,根据误差更新权重。
这可以扩展到任意数量的隐藏层, 适用于深度神经网络(deep neural networks 有复数个隐藏层)
过拟合 Overfitting
对抗过拟合的一种方法是 dropout 去拟合, 临时删除学习过程里的随机单眼,以此方法避免过度依赖网络中的某个单元
训练完成后会再次重新启用整个网络
下面是实现了反向传播的神经网络库 tensorflow 示例
1 | import csv |
计算机视觉 Computer Vision
计算机视觉包含用于分析和理解数字图像的不同计算方法,并且通常使用神经网络来实现。
图像由像素组成,像素由 0 到 255 之间的三个值表示,一为红色,一为绿色,一为蓝色。这些值通常用缩写词 RGB 来表示。我们可以用它来创建一个神经网络,其中每个像素中的每个颜色值都是输入,其中有一些隐藏层,输出是一些单元,这些单元告诉我们图像中显示的内容。
这种方法有一些缺点。首先,通过将图像分解为像素及其颜色值,我们不能使用图像的结构作为辅助。其次,输入的数量非常大,这意味着我们必须计算大量的权重。
图像卷积 Image Convolution
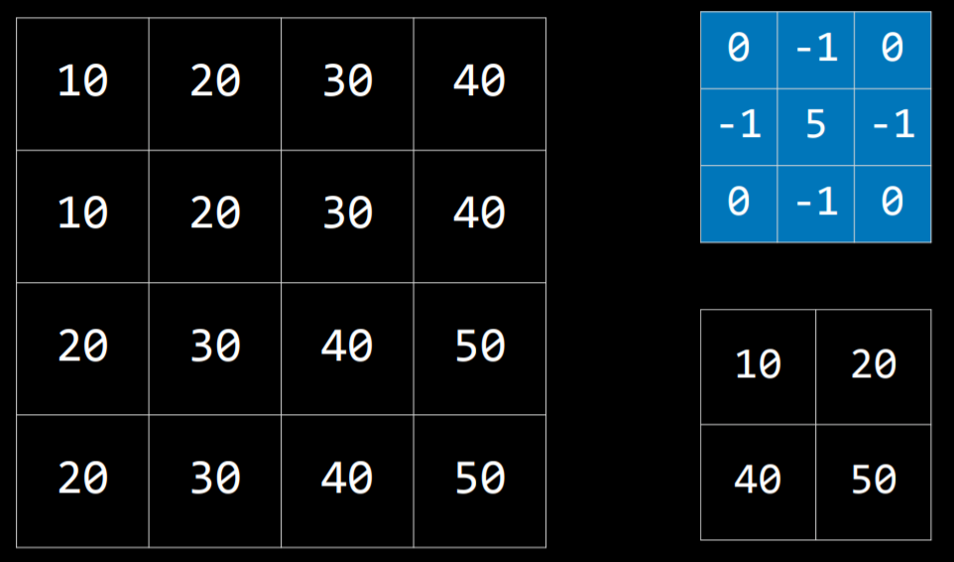
图像卷积使用一个过滤器 filter ,将图像的每个像素值与其相邻像素值根据内核矩阵的权值乘积相加。这样做会改变图像并可以帮助神经网络处理它。
例如对下图,用右上角的内核矩阵从左侧图像矩阵的左上角 20 开始滚动计算加权和,得到右下角的矩阵
所谓的卷积其实是数学概念,这里先不赘述
此外由于内核矩阵覆盖不到边缘,处理后的图像会小一圈
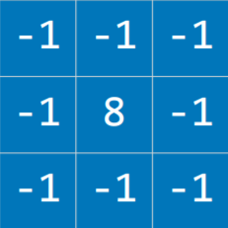
不同的内核矩阵有不同的用处,例如下面的矩阵用于提取边缘(这里的想法是: 如果一个点和周边相似,相加就会得到 0)
PIL library (stands for Python Imaging Library)可以实现图像卷积 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import math
import sys
from PIL import Image, ImageFilter
# Ensure correct usage
if len(sys.argv) != 2:
sys.exit("Usage: python filter.py filename")
# Open image
image = Image.open(sys.argv[1]).convert("RGB")
# Filter image according to edge detection kernel
filtered = image.filter(ImageFilter.Kernel(
size=(3, 3),
kernel=[-1, -1, -1, -1, 8, -1, -1, -1, -1],
scale=1
))
# Show resulting image
filtered.show()
考虑一下图像的像素数量,计算量依旧很恐怖,一个降低计算量的方法叫池化 Pooling, 通过采样来减少输入量, 即一片区域里选一个像素来计算,如一种方法 Max-Pooling , 选区域里值最高的像素形成一个更小的图像
例如一个 4×4像素矩阵 对 2×2 区域采样的话,最后就得到 2×2 像素矩阵
卷积神经网络 Convolutional Neural Networks
卷积神经网络是使用卷积的神经网络,通常用于分析图像。使用过滤器通过不同的内核矩阵来提取图像特征,正如学习权重一样,过滤器也可以通过学习和反馈来提高效果。
最后,汇总提取好的图像,喂给我们的神经网络作为输入数据
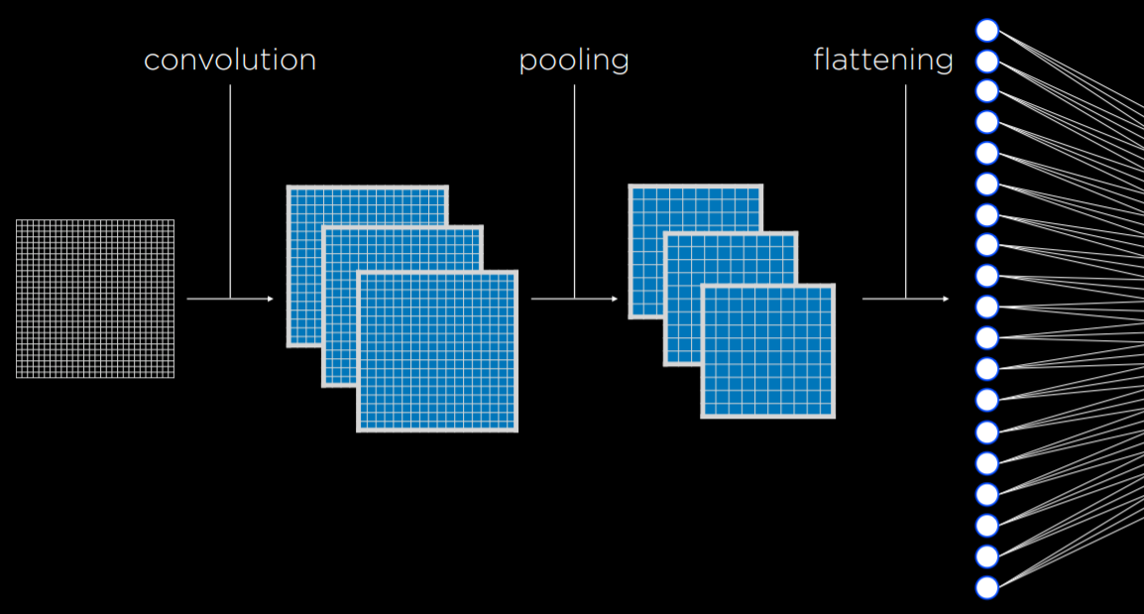
卷积和池化步骤可以重复多次,以提取额外的特征并减少神经网络输入的大小。这样做还有一个好处是,让神经网络对变化不那么敏感
在代码上,卷积神经网络与传统神经网络没有太大区别。例如以下示例使用 tensorflow 训练卷积网络识别数字
1 | import sys |
循环神经网络 Recurrent Neural Networks
循环神经网络 RNN 由非线性结构组成,也就是说网络可以用自己的输出作为输入。例如微软的 captionbot 能用语句描述图像内容。这与分类不同,因为其输出长度可以根据图像的属性改变,前馈神经网络则无法改变自己的输出数量
而 captioning 能够循环将自己的输出作为输入直到产生满意的结果
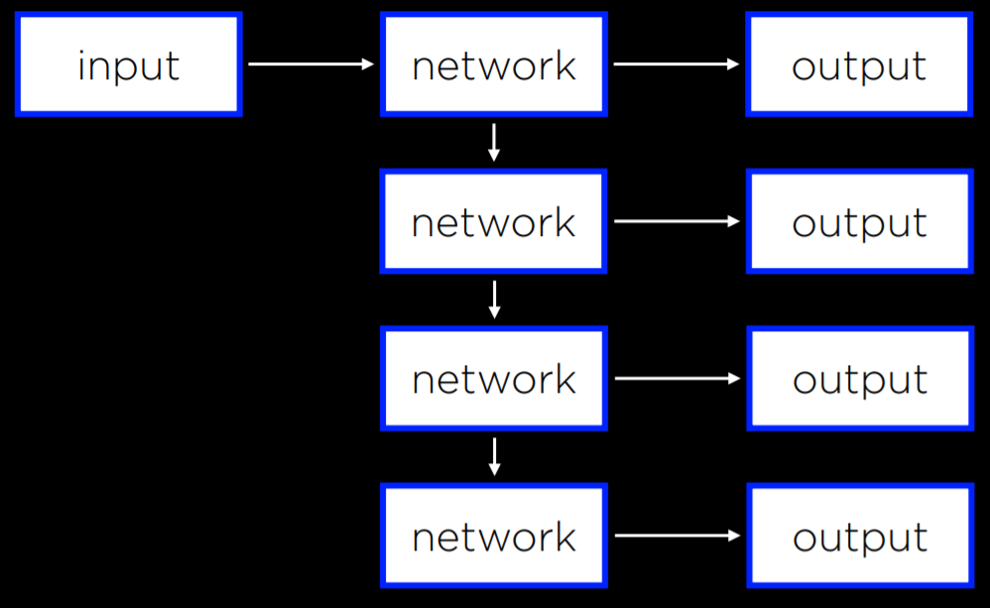
当需要处理数据序列而不是单个对象时,循环神经网络很有用, 翻译任务等也有类似的性质
自然语言处理 Natural Language Processing
自然语言处理涵盖人工智能获取人类语言作为输入的所有任务。以下是此类任务的一些示例:
- 自动摘要,其中人工智能接受文本作为输入,并生成文本摘要作为输出
- 信息提取,其中人工智能被给予文本语料库,人工智能提取数据作为输出
- 语言识别,其中人工智能被给予文本并返回文本的语言作为输出
- 机器翻译,即向人工智能提供源语言的文本,并输出目标语言的翻译。
- 命名实体识别,其中人工智能被给予文本,它提取文本中实体的名称(例如,公司名称)
- 语音识别,人工智能接受语音并在文本中产生相同的单词
- 文本分类,人工智能收到文本后需要将其分类为某种类型的文本
- 词义消歧,人工智能需要为具有多种含义的词选择正确的含义
句法和语义 Syntax and Semantics
句法是句子的结构。对母语者来说下意识就能判断句法正确性,对人工智能或者非母语者来说则不然
语义是单词或句子的含义,就中英文来说,不同句法的句子都可以表示相同的含义,结构正确的句子也可能完全无意义
对人工智能来说,两者都需要掌握
上下文无关语法 Context-Free Grammar
形式文法 Formal Grammar 是关于如何用语言生成句子的规则系统。而上下文无关语法则将文本的含义抽象出来,从而用形式文法表示句子的结构
例如句子 She saw the city. 我们首先为每个单词分配其词性。 she 和 city 是名词,我们将其标记为 N。 Saw 是动词,我们将其标记为 V。The 是限定词,将后面的名词标记为定或不定,我们将其标记为 D。上面的句子可以改写为 NVDN
那么如何表示这个句子的结构呢,如图,可视为 noun phrase (NP), verb phrase (VP)的组合
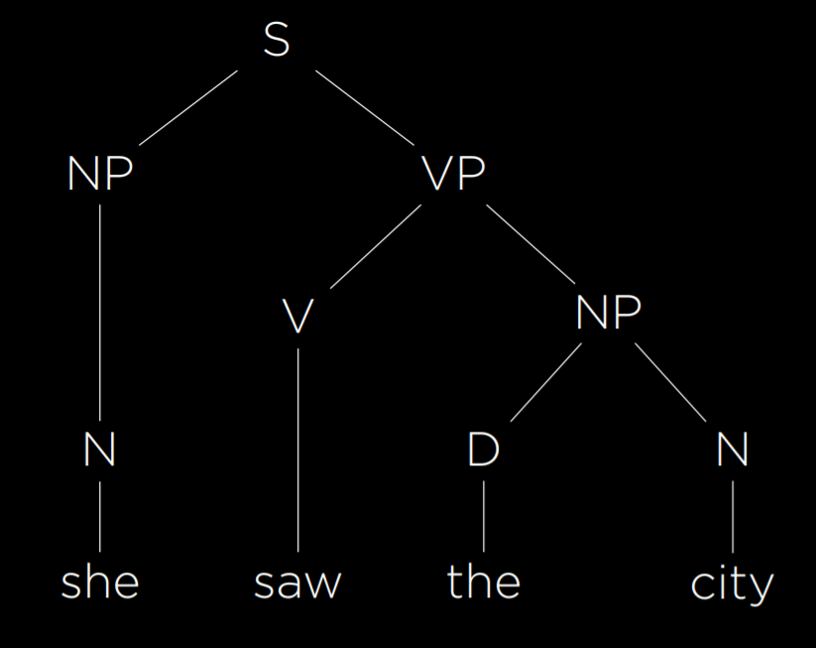
使用形式文法,人工智能能够表示句子的结构。python 中 nltk 库用于实现这一功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> D N | N
VP -> V | V NP
D -> "the" | "a"
N -> "she" | "city" | "car"
V -> "saw" | "walked"
""")
parser = nltk.ChartParser(grammar)
sentence = input("Sentence: ").split()
try:
for tree in parser.parse(sentence):
tree.pretty_print()
tree.draw()
except ValueError:
print("No parse tree possible.")
n 元语法 n-grams
一段文本样本中 n 个文本对象的序列就是 n 元语法 ,在 character n-gram 中,对象是字符,word n-gram 中对象是单词
unigram, bigram, and trigram(一元语法,二元语法,三元语法) 可表示 1,2,3 个对象的 n 元语法
例如对下面的句子,前三个三元语法是 “how often have,” “often have I,” and “have I said.”
“How often have I said to you that when you have eliminated the impossible whatever remains, however improbable, must be the truth?”
这种分解方便人工智能记忆和查找,例如输入法推测你下一个可能输入的单词就可以通过这种机制实现
标记化 Tokenization
将字符序列分割成片段(标记)的任务,标记可以是单词也可以是句子,在这种情况下,任务称为 单词标记化 或 句子标记化 (word tokenization or sentence tokenization)
再分割中,我们会遇到标点符号,符合直觉的想法是一些标点附近的词,如句末,相比其他词更重要。处理这些问题就是标记化的重点任务。
马尔可夫模型 Markov Models
基于文本的序列性,使用马尔科夫模型是个符合直觉的想法,例如我们在一段文本上训练模型,不断基于前一个 n 元语法,根据概率计算下一个可能的标记
词袋模型 Bag-of-Words Model
词袋是一种将文本表示为无序单词集合的模型。该模型忽略语法,仅考虑句子中单词的含义。这种方法对于某些分类任务很有帮助,例如情感分析和区分常规电子邮件与垃圾邮件
考虑这些句子:
- “My grandson loved it! So much fun!”
- “Product broke after a few days.”
- “One of the best games I’ve played in a long time.”
- “Kind of cheap and flimsy, not worth it.”
1,3 中的(“loved,” “fun,” “best”),24 中的 (“broke,” “cheap,” “flimsy”)不难得出答案
Naive Bayes
朴素贝叶斯是一种可用于词袋模型情感分析的技术。在情感分析中,问题是“给定句子中的单词,该句子是积极/消极的概率是多少”。
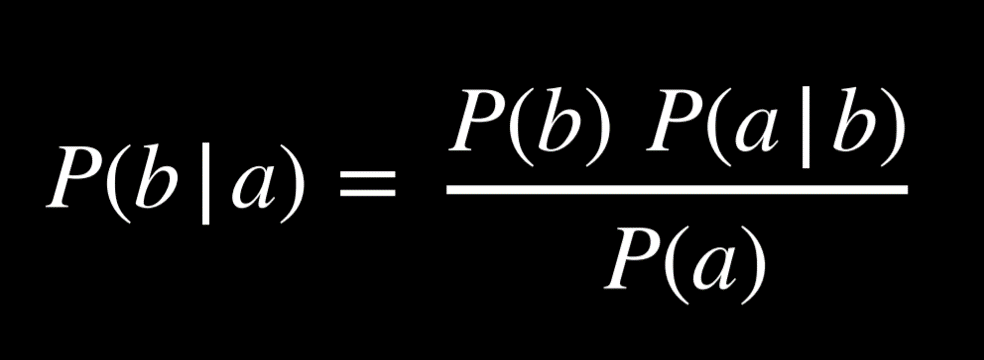
假设我们想知道 P(positive | “my grandson loved it”), 对文本标记化得到 P(positive | “my”, “grandson”, “loved”, “it”), 使用贝叶斯公式: P(“my”, “grandson”, “loved”, “it” | positive)*P(positive)/P(“my”, “grandson”, “loved”, “it”) 就可以计算答案
鉴于求的是概率,归一化是个自然的想法, 也就是我们只需要考虑分子;而条件概率 P(A|B)与联合概率 P(A, B)成正比,可以进一步化为 P(positive, “my”, “grandson”, “loved”, “it”)*P(positive), 这个式子算起来会非常麻烦,也就是要算 P(positive)*P(“my” | positive)*P(“grandson” | positive, “my”)*P(loved | positive, “my”, “grandson”)*P(“it” | positive, “my”, “grandson”, “loved”)
因此我们需要朴素贝叶斯,朴素(naive)的含义是: 我们假设每个单词的概率独立于其他单词。这不准确,但尽管存在这种不精确性,朴素贝叶斯仍能产生良好的情绪估计。
这样一来只用计算 P(positive)*P(“my” | positive)*P(“grandson” | positive)*P(“loved” | positive)*P(“it” | positive)
 我们可能遇到的一个问题是,某些单词可能永远不会出现在某种类型的句子中。例如 P(“grandson” | positive) = 0
我们可能遇到的一个问题是,某些单词可能永远不会出现在某种类型的句子中。例如 P(“grandson” | positive) = 0
解决这个问题的一种方法是使用 加法平滑 Additive Smoothing,我们向分布中的每个值添加一个值 α 以平滑数据。这样,即使某个值是 0,通过向其添加 α,我们也不会将肯定句或否定句的整个概率乘以 0。 拉普拉斯平滑 Laplace Smoothing 是一种特定类型的加法平滑,它会为我们的每个值添加 1 计数,假装所有值都至少被观察过一次。
假设在文本分类中,有 3 个类,C1、C2、C3,在指定的训练样本中,某个词语 K1,在各个类中观测计数分别为 0,990,10,K1 的概率为 0,0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
1/1003 = 0.001,991/1003 = 0.988,11/1003 = 0.011
信息检索 Information Retrieval
信息检索是响应用户查询查找相关文档的任务。我们使用 主题建模 topic modeling 来发现一组文档的主题
人工智能如何提取文档主题?一种方法是查看 术语频率 term frequency,即简单地计算术语在文档中出现的次数
一般来说我们追求所谓的内容词 content words,也就是信息含量比较高的词,而不是 功能词 function words
指标 逆文档频率 Inverse Document Frequency,用于衡量一个词在语料库中的文档中的常见或罕见程度。通常通过以下等式计算: 
tf-idf(库)表示 Term Frequency — Inverse Document Frequency.即将每个单词的术语频率乘以逆文档频率,从而获得每个单词的值,一个词在一份文档中出现的频率越高、出现的文档越少,其值就越高。 TFIDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
信息提取 Information Extraction
信息抽取是从文档中抽取知识的任务。到目前为止,当我们希望人工智能执行简单的任务时,例如识别句子中的情绪是积极的还是消极的,或者检索文档中的关键词,使用词袋方法处理文本很有帮助。然而,对于像信息提取这样的任务,我们需要人工智能来理解不同单词之间的联系,词袋方法就不太实用了
信息提取的可能任务可以采取以下形式:向人工智能提供文档作为输入,并获取公司列表及其成立年份作为输出。最符合直接的可能给 ai 一个模板让其匹配,但并非所有数据都按模板给出,因此可以给人工智能一个抽象的例子,比如“Facebook,2004”,并让它开发自己的模型来提取数据。
总之,我们需要 ai 能某种程度上能理解词语之间的关系
词网 Word Net
Wordnet 是一个类似于字典的数据库,其中为单词提供了定义以及更广泛的类别。例如,“房屋”一词会产生多种定义,其中之一是“为一个或多个家庭提供居住区的住宅”。该定义与“建筑”和“住宅”类别配对。
词汇表征 Word Representation
我们希望在人工智能中表示单词的含义。正如我们之前所看到的,以数字形式向人工智能提供输入是很方便的, 即 词嵌入(Word Embedding)(将文本中的单词映射到向量空间中)。这种向量称为词向量
对小文本可以使用独热编码 One-Hot Representation,即 N 位信息来对 N 个状态进行编码,每个单词都用一个向量表示,该向量由与文本总单词数量个维度组成。
句子 He wrote a book 可以这么表示:
- [1, 0, 0, 0] (he)
- [0, 1, 0, 0] (wrote)
- [0, 0, 1, 0] (a)
- [0, 0, 0, 1] (book)
对规模更大的文本,可以使用分布式表示 Distributed Representation , 向量的每个维度表示某种程度上的语义,例如:
- [-0.34, -0.08, 0.02, -0.18, …] (he)
- [-0.27, 0.40, 0.00, -0.65, …] (wrote)
- [-0.12, -0.25, 0.29, -0.09, …] (a)
- [-0.23, -0.16, -0.05, -0.57, …] (book)
另一个好处是:我们也可以用周围的词义来优化一个单词的词义向量
word2vec
一种用于生成单词的分布式表示的算法。
word2vec 使用 Skip-Gram 架构 ,一种神经网络架构,用于预测给定目标单词的上下文。在这种架构中,神经网络对于每个目标词都有一个输入单元。较小的单个隐藏层(例如 50 或 100 个单元)将生成表示单词的分布式表示的值。该隐藏层中的每个单元都连接到输入层中的每个单元。输出层将生成可能出现在与目标单词相似的上下文中的单词。与我们在上一讲中看到的类似,该网络需要使用反向传播算法使用训练数据集进行训练。
即该模型可以用单个词预测上下文,也可以反过来用上下文填空
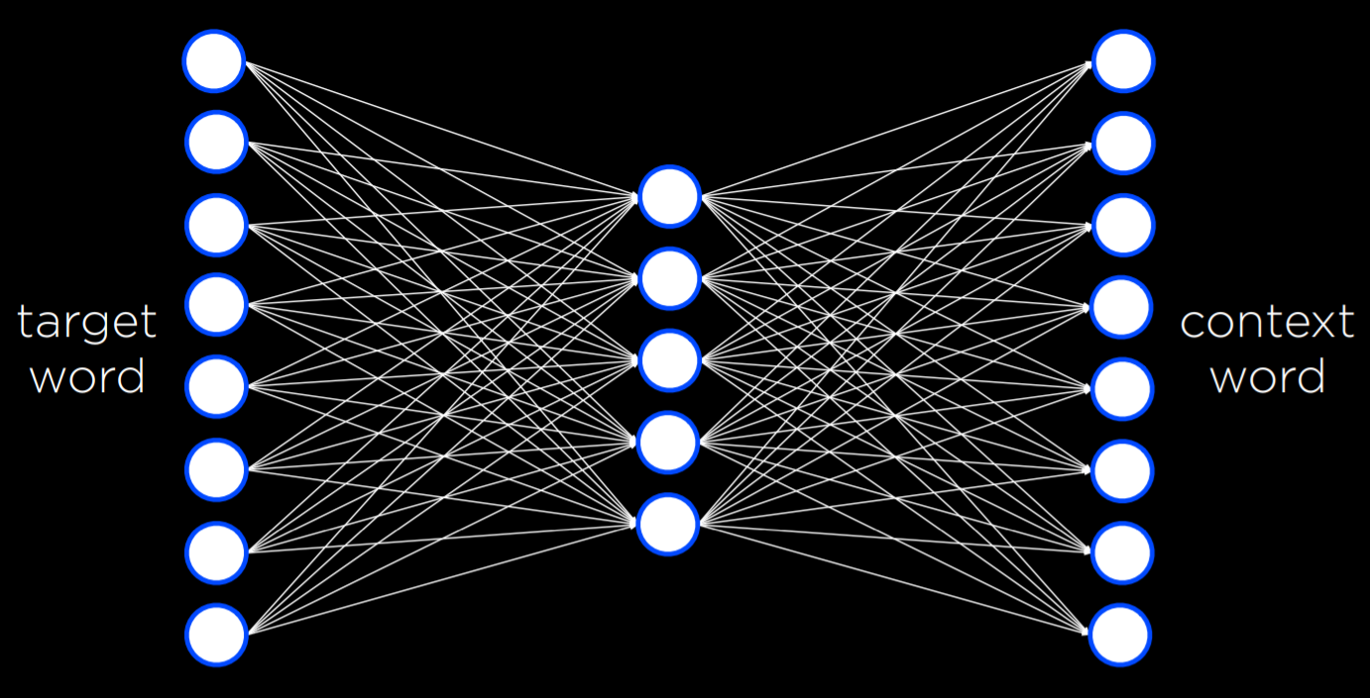
这么一来我们可以方便地查找相似向量的单词,例如对单词 book: books, essay, memoir, essays, novella, anthology, blurb, autobiography, audiobook
此外,king and man, queen and woman 的差异是相似的,考虑日本和拉面,用到美国上就会得到墨西哥卷饼(话说为什么不是汉堡)