基于伯克利ds100的数据科学笔记pandas部分
notebook
Ctrl+Return(或者Cmd+Return在 Mac 上): 评估当前单元格Shift+Return: 评估当前单元格并移至下一个单元格ESC: 命令模式 (在使用以下任何命令之前可能需要按)a: 在上面创建一个单元格b: 在下面创建一个单元格dd: 删除一个单元格z: 撤消上一次单元格操作m: 将单元格转换为 Markdowny: 将单元格转换为代码
pandas
创建表格DataFrame
按列创建
1 | fruit_info = pd.DataFrame( |
按行创建
1 | fruit_info2 = pd.DataFrame( |
选择行和列
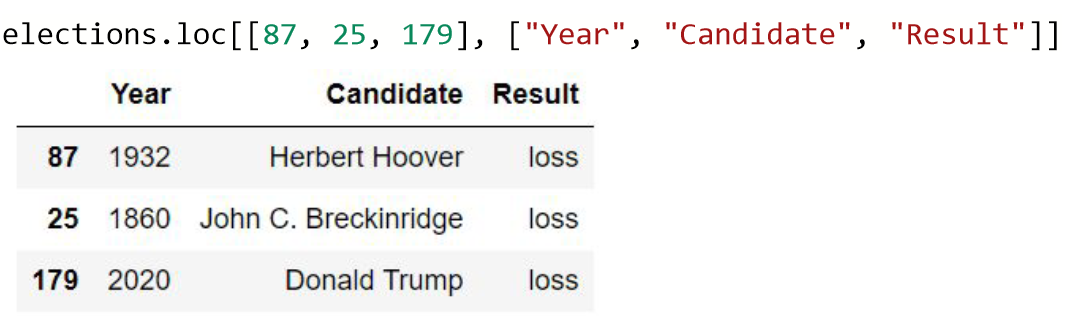
- loc 两个详细运算符中的第一个是
loc,它需要两个参数。 第一个是一个或多个行 标签 ,第二个是一个或多个列 标签 。
所需的行或列可以单独提供、以切片表示法或作为列表提供。 单独提供会返回series 单独切片参数默认返回行
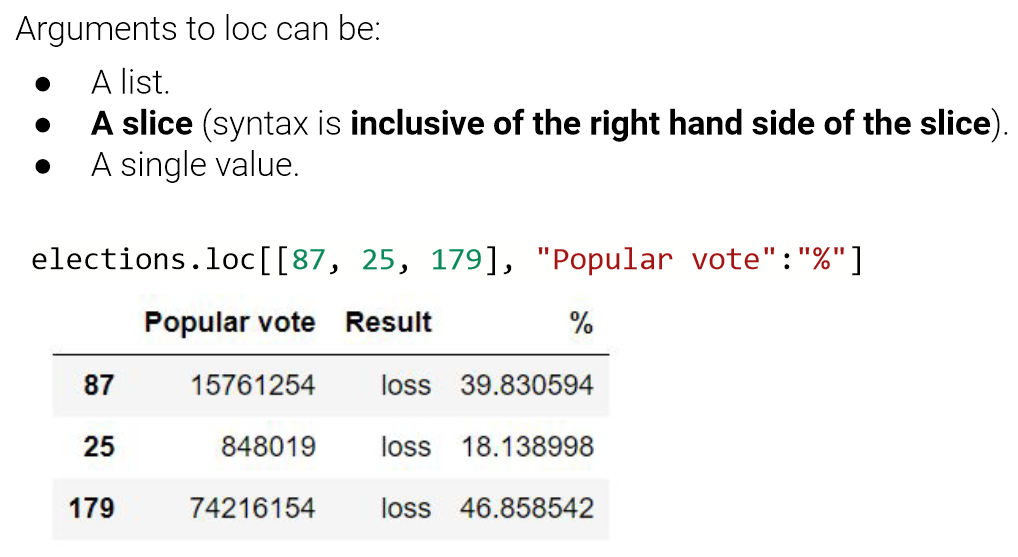
 ● loc selects items by label. First argument is rows, second argument is columns. ● iloc selects items by number. First argument is rows, second argument is columns. ● [] only takes one argument, which may be: ○ A slice of row numbers. ○ A list of column labels. ○ A single column label. That is,[] is context sensitive.
● loc selects items by label. First argument is rows, second argument is columns. ● iloc selects items by number. First argument is rows, second argument is columns. ● [] only takes one argument, which may be: ○ A slice of row numbers. ○ A list of column labels. ○ A single column label. That is,[] is context sensitive.
- 列名一般唯一,可以强制重复
- 行名可以重复 pandas支持裸操作,但此时无法使用切片
1 | # Here we're providing a list of fruits as single argument to [] |
其他行列操作
添加行和列
1 | fruit_info['rank1'] = [1,2,3,4] |
使用 .drop()方法来 删除 这两个 rank1和 rank2您创建的列。 确保使用 axis参数正确。 注意 drop不会更改表,而是返回一个具有较少列或行的新表,除非您设置可选 inplace范围
1 | fruit_info |
重命名
1 | fruit_info_caps=fruit_info_original.rename(columns={'fruit':'F','color':'C','price':'P'}) |
布尔数组筛选和查询
1 | result = baby_names[(baby_names['Year']==2000) & (baby_names['Count']>3000)] |
slides实例
提取列数据:
1 | elections["Candidate"].tail(5).to_frame() |
提取目录:
1 | For row labels, use DataFrame.index: |
支持布尔数组检索 
1 | elections[elections["Party"] == "Independent"] |
支持用其他数组检索
1 | a_parties = ["Anti-Masonic", "American", "Anti-Monopoly", "American Independent"] |
查询类似sql
1 | elections.query('Result == "win" and Party not in @parties') |
匿名函数辅助查询
1 | What if we wanted to find the longest names in California? |
创建删除列
1 | babyname_lengths = babynames["Name"].str.len() |
map方法使用函数统计数据
1 | def dr_ea_count(string): |
字典创建表格
1 | #build dictionary where each entry is the rtp for a given name |
使用group建立新表格
1 | female_babynames.groupby("Name").agg(ratio_to_peak) |
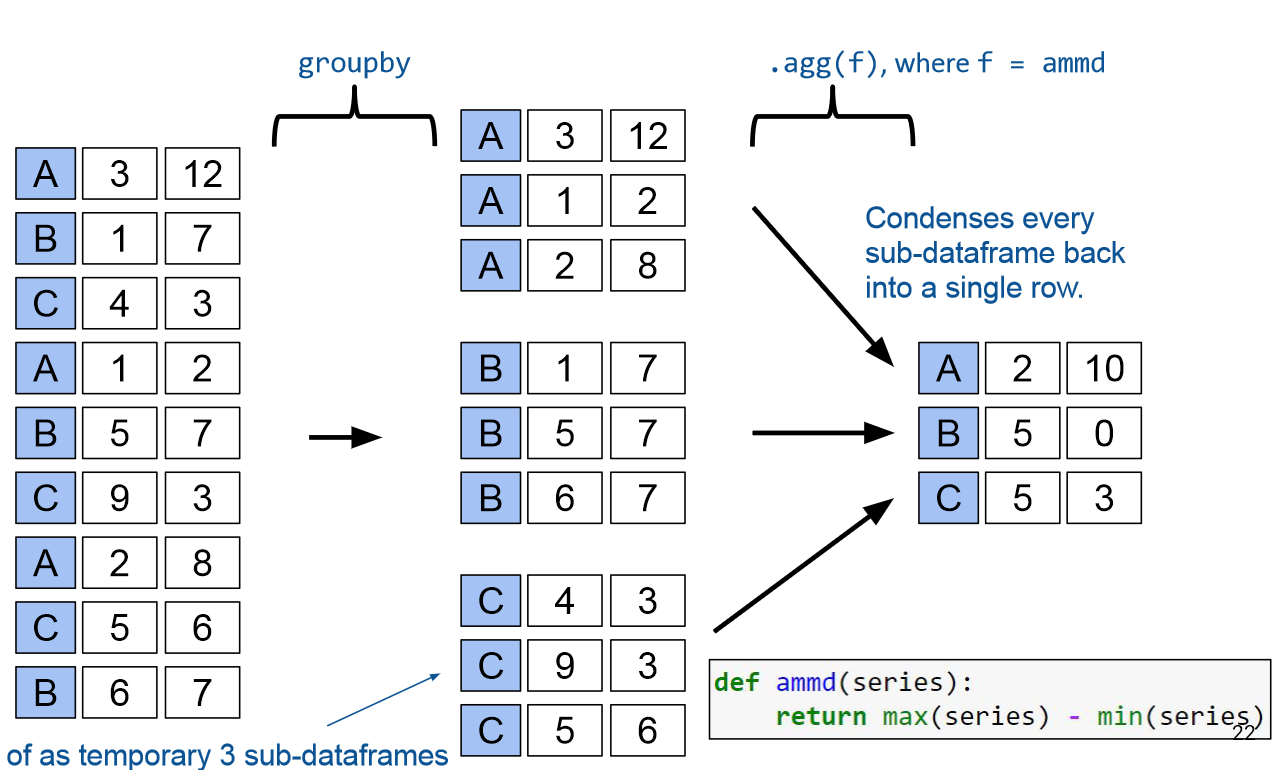 groupby的其他用法
groupby的其他用法
1 | Given a DataFrameGroupBy object, can use various functions to generate DataFrames (or |
合并表格
1 | merged = pd.merge(left = elections, right = male_2020_babynames, |